







 本文介绍了多项式回归的基本概念,包括其扩展了线性回归的模型形式。讨论了在金融、气象学和生物统计学中的应用场景,以及模型的灵活性、简单性、过拟合风险和选择最佳阶数的挑战。通过Python示例展示了如何实施和评估多项式回归模型。
本文介绍了多项式回归的基本概念,包括其扩展了线性回归的模型形式。讨论了在金融、气象学和生物统计学中的应用场景,以及模型的灵活性、简单性、过拟合风险和选择最佳阶数的挑战。通过Python示例展示了如何实施和评估多项式回归模型。
多项式回归是一种形式的线性回归,在处理非线性数据时非常有用。它通过对一个或多个自变量的幂进行建模,来拟合一个非线性关系。本文将探讨多项式回归的基本概念、应用场景、优缺点以及如何实施。
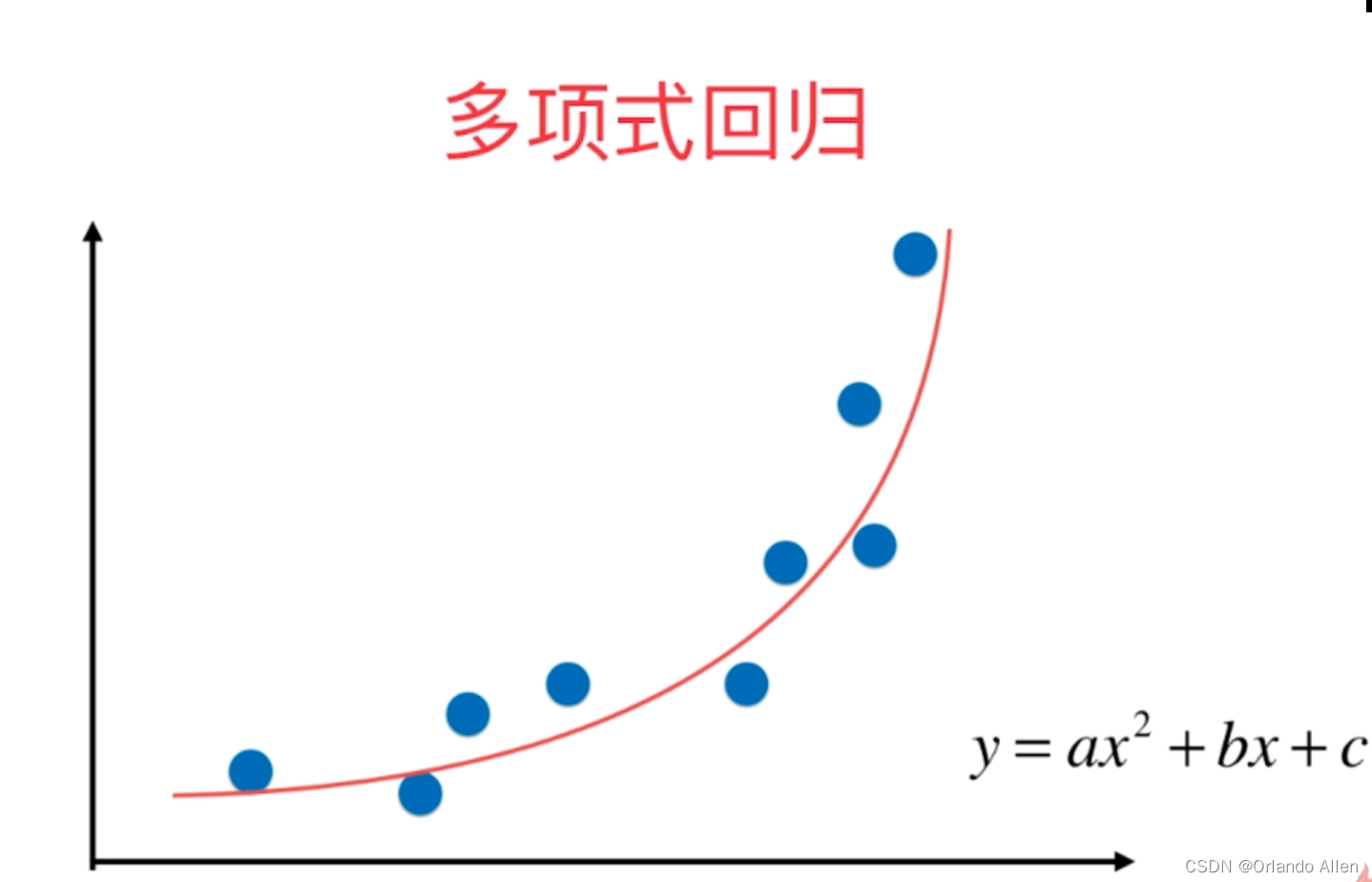
基本概念
多项式回归模型是线性回归的一个扩展,它允许自变量的高次项和交互项作为预测变量。模型的一般形式可以表示为:
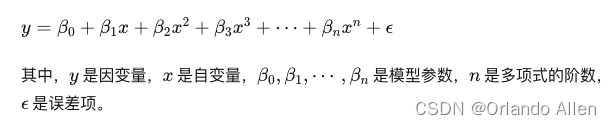
应用场景
多项式回归在很多领域都有应用,特别是在那些线性模型无法提供良好拟合的场景。例如,在金融领域,它可以用来预测资产的价格变动;在气象学中,用于模拟气温和海平面高度的变化关系;在生物统计学中,分析药物剂量与治疗效果之间的非线性关系。
优缺点
优点:
- 灵活性:多项式回归能够拟合数据中的非线性模式,提供比线性模型更精确的预测。
- 简单性:尽管是非线性模型,但多项式回归可以使用线性回归的技术来估计参数,使问题简化。
缺点:
- 过拟合:高阶多项式回归容易过拟合,特别是在有限的数据点上。过拟合会导致模型在新数据上的泛化能力变差。
- 选择难度:确定多项式的最佳阶数可能很困难,需要通过交叉验证等方法综合判断。
实施步骤
- 数据准备:收集并清洗数据,确保数据质量。
- 选择阶数:通过交叉验证等技术选择一个合适的多项式阶数。
- 模型训练:使用选定的阶数训练多项式回归模型。
- 评估模型:通过计算诸如R-squared、均方误差(MSE)等指标来评估模型的性能。
- 模型调优:根据评估结果调整模型参数,如通过增加或减少多项式的阶数来优化模型。
示例代码
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
X = np.array([[1], [2], [3], [4], [5], [6], [7], [8], [9], [10]])
y = np.array([1, 4, 9, 16, 25, 36, 49, 64, 81, 100]) # y = x^2,一个简单的二次关系
# 转换特征
polynomial_features = PolynomialFeatures(degree=2) # 选择多项式的度为2
X_poly = polynomial_features.fit_transform(X)
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X_poly, y, test_size=0.3, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"模型的均方误差(MSE): {mse}")
print(f"模型的R^2分数: {r2}")
在这个例子中,我们首先生成了一组简单的二次数据。然后,我们使用PolynomialFeatures类来增加特征的多项式和交互项。接下来,我们拆分数据为训练集和测试集,用训练集训练线性回归模型,并在测试集上评估模型的性能。
通过调整PolynomialFeatures的degree参数,你可以尝试不同阶数的多项式来看看哪个给出了最好的模型性能。
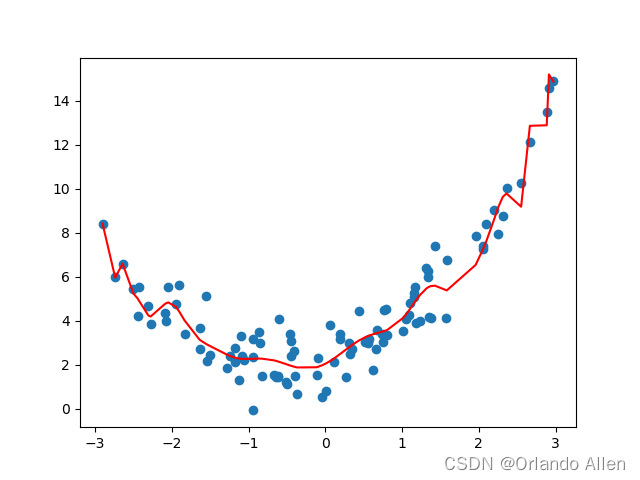
结论
多项式回归是一种强大的工具,可以帮助我们理解和预测数据中的复杂非线性关系。然而,使用时需要谨慎,避免过拟合,并选择合适的多项式阶数。通过有效的模型评估和调整,多项式回归可以在许多不同的领域发挥重要作用。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











