






AE(auto encoder)
1. Sparse AE 稀疏自编码器
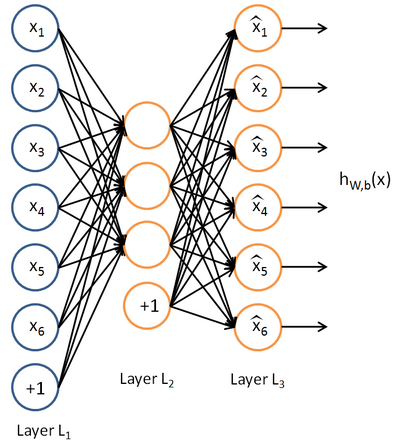
一般情况下,影藏层的结点数目少于输入层。
模型能够得到原始数据较好的低维表示的前提是输入数据中存在一定的潜在结构,比如存在相关性,这样稀疏自动编码可以学习得到类似于主成分分析(PCA)的低维表示。如果输入数据的每一个特性都是相互独立的,最后学习得到的低维表示效果比较差。用途:特征提取、降维。
1.1 稀疏的含义及损失函数
一般使得隐含层小于输入结点的个数,如果隐藏层的节点数大于输入结点的个数,只需要对其加入一定的稀疏限制就可以达到同样的效果。如何隐藏层的节点中大部分被抑制,小部分被激活。如果的非线性函数是sigmoid函数,当神经元的输出接近1时为激活,接近0时为稀疏;如果采用tanh函数,当神经元的输出接近1时为激活,接近-1时为稀疏。
稀疏自动编码希望让隐含层的平均激活度为一个比较小的值。
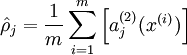
其中,
a
j
(
2
)
(
x
)
a_{j}^{(2)}(x)
aj(2)(x)表示在输入数据为x的情况下,隐藏神经元j的激活度。为了使得均激活度为一个比较小的值,引入
ρ
\rho
ρ ,称为稀疏性参数,一般是一个比较小的值,使得
ρ
^
j
=
ρ
\hat{\rho}_{j}=\rho
ρ^j=ρ,这样就可以是隐含层结点的活跃度很小。
上面只是理论上的解释,那如何转化成数据表示,该模型引入了相对熵(KL divergence)。KL的表达式为:
K
L
(
ρ
∥
ρ
^
j
)
=
ρ
log
ρ
ρ
^
j
+
(
1
−
ρ
)
log
1
−
ρ
1
−
ρ
^
j
\mathrm{KL}\left(\rho \| \hat{\rho}_{j}\right)=\rho \log \frac{\rho}{\hat{\rho}_{j}}+(1-\rho) \log \frac{1-\rho}{1-\hat{\rho}_{j}}
KL(ρ∥ρ^j)=ρlogρ^jρ+(1−ρ)log1−ρ^j1−ρ
我们假设
ρ
=
0.2
\rho=0.2
ρ=0.2 ,得到的相对熵值
K
L
(
ρ
∥
ρ
^
j
)
\mathrm{KL}\left(\rho \| \hat{\rho}_{j}\right)
KL(ρ∥ρ^j) 随着
ρ
^
\hat{\rho}
ρ^ 变化的变化趋势图。
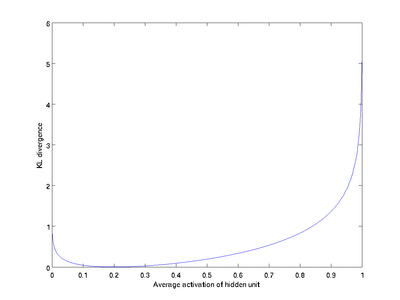
如上图所示,相对樀在
ρ
^
j
=
ρ
\hat{\rho}_{j}=\rho
ρ^j=ρ, 时达到它的最小值 0 ,而当
ρ
^
j
\hat{\rho}_{j}
ρ^j 靠近 0 或者 1 的时候,相对熵则变得非常大 (其实是趋向于
∞
\infty
∞ )。
原文链接:https://blog.csdn.net/danieljianfeng/article/details/41744067
1.2 权重衰减
L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化。
原因:
(1)从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。
(2)从数学方面的解释:过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的**导数值(绝对值)**非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
L2正则化就是在代价函数后面再加上一个正则化项:
C
=
C
0
+
λ
2
n
∑
w
w
2
C=C_{0}+\frac{\lambda}{2 n} \sum_{w} w^{2}
C=C0+2nλw∑w2
其中C0代表原始的代价函数,后面那一项就是L2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。
λ
\lambda
λ 就是正 则项系数,权衡正则项与CO项的比重。另外还有一个系数
1
/
2
,
1
/
2
1 / 2 , 1 / 2
1/2,1/2 经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产 生一个
2
,
2 ,
2, 与
1
/
2
1 / 2
1/2 相乘刚好凑整为 1 。系数
λ
\lambda
λ 就是权重衰减系数。
原文链接:https://blog.csdn.net/program_developer/article/details/80867468
2. Stack AE
贪婪训练,训练好一个再训练另一个。
就是一个最基本的autoencode,需要构建一个临时的输出层(也就是图中最右边那层,维度跟原始输入完全一样),记住,输出目标还是尽可能还原原始输入,训练完后,得到第一层参数,W和b,保存下来,然后丢弃这个输出层,因为实际上这个输出层除了在训练过程中有用之外,之后并没有什么卵用。
随后把上面训练好的这个包含一个隐藏层的神经网络看做一个整体,任何灌入到它的数据都会以一个更低维的数据表示作为输出(比如我们可以记为h1),然后对这个整体后面再添加第二层的神经元(维度更低),并添加构造一个临时输出层,然后同样的方式训练第二层,这里特别注意,我们把前面的整体输出(h1)当成这第二层的输入了,那么构建第二个autoencoder时,添加的临时输出层就不再是原始的(x1)了,而是第一部分的输出,即(h1)。这一点是避免训练方式的误解的关键所在。
从“信息量”的角度来说,这一层层保持得很好,跟原始数据差距不大,只不过它们用更低的维度来表示了数据,那么可以理解为更“精炼”版本的数据
原文链接:https://blog.csdn.net/xunileida/article/details/82716895
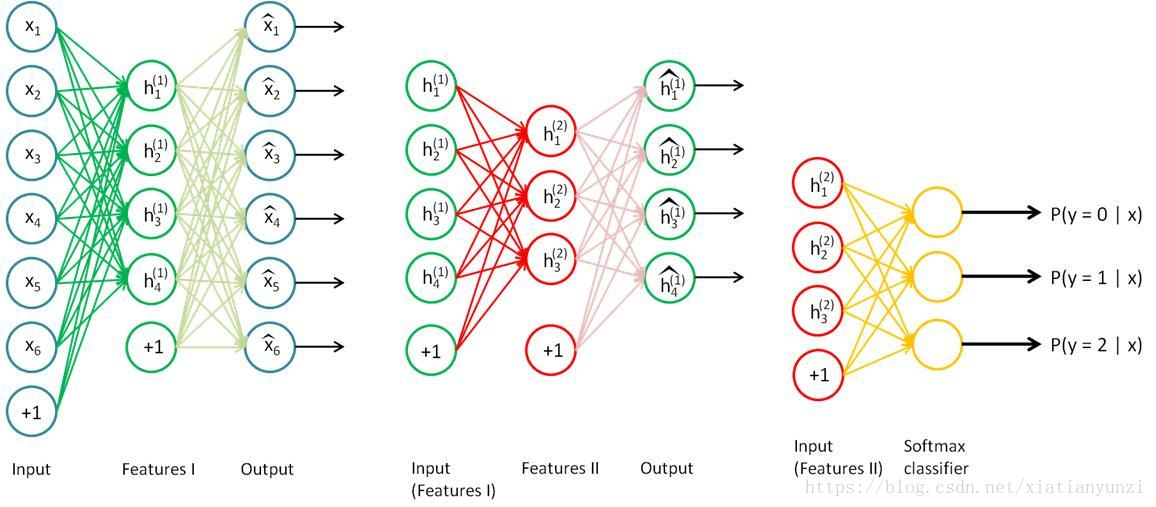
在上述预训练结束之后,将上面三层结合起来得到包含两个隐藏层和一个softmax输出层的栈式自编码网络,如下图所示。
然后采用反向传播算法调整所有层的参数,这个过程称为微调。微调过程中,网络所有层的全部参数都被优化,经过微调后,可以大幅提高神经网络的分类性能。

原文链接:https://blog.csdn.net/xiatianyunzi/article/details/82456125
3. 论文损失函数构建
论文:http://dx.doi.org/10.1016/j.ymssp.2017.03.034
论文所提损失函数:
J
new
(
θ
)
=
−
J
M
C
(
θ
)
+
J
weight
(
θ
)
+
J
sparse
(
θ
)
J_{\text {new }}(\boldsymbol{\theta})=-J_{\mathrm{MC}}(\boldsymbol{\theta})+J_{\text {weight }}(\boldsymbol{\theta})+J_{\text {sparse }}(\boldsymbol{\theta})
Jnew (θ)=−JMC(θ)+Jweight (θ)+Jsparse (θ)
3.1 相关熵损失
标准的自动编码器损失函数是用 MSE 设计的,这对于复杂信号的特征学习并不鲁棒 。 相关熵是一种非线性和局部相似性度量,最大相关熵对复杂和非平稳的背景噪声不敏感。
For two random variables
A
=
[
a
1
,
a
2
,
…
a
N
]
T
A=\left[a_{1}, a_{2}, \ldots a_{N}\right]^{T}
A=[a1,a2,…aN]T and
B
=
[
b
1
,
b
2
,
…
b
N
]
T
B=\left[b_{1}, b_{2}, \ldots b_{N}\right]^{T}
B=[b1,b2,…bN]T, the correntropy is define as
V
σ
(
A
,
B
)
=
E
[
κ
σ
(
A
,
B
)
]
=
∫
κ
σ
(
a
,
b
)
d
F
A
B
(
a
,
b
)
V_{\sigma}(A, B)=E\left[\kappa_{\sigma}(A, B)\right]=\int \kappa_{\sigma}(a, b) d F_{A B}(a, b)
Vσ(A,B)=E[κσ(A,B)]=∫κσ(a,b)dFAB(a,b)
where
E
[
⋅
]
E[\cdot]
E[⋅] is the expectation operator,
κ
σ
(
⋅
,
⋅
)
\kappa_{\sigma}(\cdot, \cdot)
κσ(⋅,⋅) is the Mercer kernel, and
F
A
B
(
a
,
b
)
F_{A B}(a, b)
FAB(a,b) is the joint probability density function. In practical engineering, the joint probability density function is usually unknown and only a finite set of samples
{
(
a
i
,
b
i
)
}
i
=
1
m
\left\{\left(a_{i}, b_{i}\right)\right\}_{i=1}^{m}
{(ai,bi)}i=1m are available, then the estimated correntropy can be calculated by
V
~
σ
(
A
,
B
)
=
1
m
∑
i
=
1
m
κ
σ
(
a
i
,
b
i
)
\tilde{V}_{\sigma}(A, B)=\frac{1}{m} \sum_{i=1}^{m} \kappa_{\sigma}\left(a_{i}, b_{i}\right)
V~σ(A,B)=m1i=1∑mκσ(ai,bi)
Gaussian kernel is the most popular Mercer kernel in correntropy, which is defined as
κ
σ
(
a
i
,
b
i
)
=
1
2
π
σ
exp
(
−
(
a
i
−
b
i
)
2
2
σ
2
)
\kappa_{\sigma}\left(a_{i}, b_{i}\right)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(a_{i}-b_{i}\right)^{2}}{2 \sigma^{2}}\right)
κσ(ai,bi)=2πσ1exp(−2σ2(ai−bi)2)
where
σ
\sigma
σ is the kernel size.
Then, the new autoencoder loss function can be designed by maximizing the following function
J
M
C
(
θ
)
=
1
m
∑
i
=
1
m
κ
σ
(
x
i
−
z
i
)
J_{\mathrm{MC}}(\boldsymbol{\theta})=\frac{1}{m} \sum_{i=1}^{m} \kappa_{\sigma}\left(\mathbf{x}_{i}-\mathbf{z}_{i}\right)
JMC(θ)=m1i=1∑mκσ(xi−zi)
3.2 稀疏正则化
考虑到稀疏输入在学习有用特征方面的优势,在本文中,我们通过稀疏项对损失函数进行正则化.
J
sparse
(
θ
)
=
β
∑
j
=
1
S
2
K
L
(
ρ
∥
ρ
^
j
)
J_{\text {sparse }}(\boldsymbol{\theta})=\beta \sum_{j=1}^{S_{2}} \mathrm{KL}\left(\rho \| \hat{\rho}_{j}\right)
Jsparse (θ)=βj=1∑S2KL(ρ∥ρ^j)
ρ
^
j
=
1
m
∑
i
=
1
m
[
a
j
(
2
)
x
i
]
KL
(
ρ
∥
ρ
^
j
)
=
ρ
log
ρ
ρ
^
j
+
(
1
−
ρ
)
log
1
−
ρ
1
−
ρ
^
j
\begin{aligned} &\hat{\rho}_{j}=\frac{1}{m} \sum_{i=1}^{m}\left[a_{j}^{(2)} \mathbf{x}_{i}\right] \\ &\operatorname{KL}\left(\rho \| \hat{\rho}_{j}\right)=\rho \log \frac{\rho}{\hat{\rho}_{j}}+(1-\rho) \log \frac{1-\rho}{1-\hat{\rho}_{j}} \end{aligned}
ρ^j=m1i=1∑m[aj(2)xi]KL(ρ∥ρ^j)=ρlogρ^jρ+(1−ρ)log1−ρ^j1−ρ
where
β
\beta
β is the weight adjustment parameter,
s
2
s_{2}
s2 is the number of units in the second layer,
ρ
^
j
\hat{\rho}_{j}
ρ^j is the average activation value for the
i
i
i th hidden layer unit, and
ρ
\rho
ρ is a sparse parameter.
3.3 权重衰减
In addition, a weight decay term
J
weight
(
θ
)
J_{\text {weight }}(\boldsymbol{\theta})
Jweight (θ) is also added to avoid overfitting(过拟合), expressed as
J
weight
(
θ
)
=
λ
2
∑
l
=
1
2
∑
i
=
1
s
l
∑
j
=
1
s
l
+
1
(
w
j
i
(
l
)
)
2
J_{\text {weight }}(\boldsymbol{\theta})=\frac{\lambda}{2} \sum_{l=1}^{2} \sum_{i=1}^{s_{l}} \sum_{j=1}^{s_{l+1}}\left(w_{j i}^{(l)}\right)^{2}
Jweight (θ)=2λl=1∑2i=1∑slj=1∑sl+1(wji(l))2
3.4 超参优化
The kernel size, the weight adjustment parameter, and the weight decay parameter are all decisive factors of the deep autoencoder. –
人工鱼群优化算法:https://blog.csdn.net/hba646333407/article/details/103082418
4. 收缩自编码器 Contractive auto-encoders (CAE)
论文:Contractive Auto-Encoders: Explicit Invariance During Feature Extraction
衡量一个自编码器模型的效果可以从两个标准入手:1.模型是否可以很好的重建输入信号;2.模型对输入数据在一定程度下的扰动是否具有不变性。
为了使自编码器在标准2下具有更好的效果,Rifai等人提出了收缩自编码器,其主要目的是为了抑制训练样本在所有方向上的扰动。为了实现这一目标,Rifai等人提出在传统自编码器的目标函数上增加一个惩罚项来达到局部空间收缩的效果。
对于auto encoder进行了改进,提出了对原有的auto encoder或者改进的正则化的auto-encoder的目标函数:
J
A
E
+
w
d
(
θ
)
=
(
∑
x
∈
D
n
L
(
x
,
g
(
f
(
x
)
)
)
)
+
λ
∑
i
j
W
i
j
2
\mathcal{J}_{\mathrm{AE}+\mathrm{wd}}(\theta)=\left(\sum_{x \in D_{n}} L(x, g(f(x)))\right)+\lambda \sum_{i j} W_{i j}^{2}
JAE+wd(θ)=(x∈Dn∑L(x,g(f(x))))+λij∑Wij2
将等号右边的正则项 (用来惩罚系数用的,防止过拟合),换成了F范数下的雅克比矩阵的形式,得到下面的公式:
J
C
A
E
(
θ
)
=
∑
x
∈
D
n
(
L
(
x
,
g
(
f
(
x
)
)
)
+
λ
∥
J
f
(
x
)
∥
F
2
)
\mathcal{J}_{\mathrm{CAE}}(\theta)=\sum_{x \in D_{n}}\left(L(x, g(f(x)))+\lambda\left\|J_{f}(x)\right\|_{F}^{2}\right)
JCAE(θ)=x∈Dn∑(L(x,g(f(x)))+λ∥Jf(x)∥F2)
the Jacobian norm has the following simple expression:
∥
J
f
(
x
)
∥
F
2
=
∑
i
=
1
d
h
(
h
i
(
1
−
h
i
)
)
2
∑
j
=
1
d
x
W
i
j
2
\left\|J_{f}(x)\right\|_{F}^{2}=\sum_{i=1}^{d_{h}}\left(h_{i}\left(1-h_{i}\right)\right)^{2} \sum_{j=1}^{d_{x}} W_{i j}^{2}
∥Jf(x)∥F2=i=1∑dh(hi(1−hi))2j=1∑dxWij2
作为惩罚项添加到自编码器的损失函数中,是因为当惩罚项具有比较小的一阶导数时,说明与输入信号对应的隐藏层表达比较平滑,则当输入出现一定变化时,隐藏层表达不会发生过大的变化,由此可以使自编码器对输入变化不敏感(扰动不敏感)。
稀疏自编码器通过对大部分隐藏层神经元进行抑制,隐藏层输出对应于激活函数的左饱和区域。收缩自编码器通过对隐藏层神经元的输出推向它的饱和区域来达到收缩性。
收缩自编码器的鲁棒性体现在对隐藏层表达上,而去噪自编码器的鲁棒性体现在重构信号中 (没咋懂,先放这儿)
原文链接:https://blog.csdn.net/jinhualun911/article/details/100736577

















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









