







 本文介绍了使用Python进行Kaggle House Price数据预处理和可视化的步骤。作者分析了'SalePrice'与其他特征的关系,发现'GrLivArea'、'TotalBsmtSF'、'OverallQual'和'YearBuilt'与价格相关。通过处理缺失值、离群值,以及进行正态性、方差齐性和线性检查,为模型建立打下基础。文章还包括了数据转换和非数值特征的处理。
本文介绍了使用Python进行Kaggle House Price数据预处理和可视化的步骤。作者分析了'SalePrice'与其他特征的关系,发现'GrLivArea'、'TotalBsmtSF'、'OverallQual'和'YearBuilt'与价格相关。通过处理缺失值、离群值,以及进行正态性、方差齐性和线性检查,为模型建立打下基础。文章还包括了数据转换和非数值特征的处理。
参考原文链接 https://www.kaggle.com/pmarcelino/comprehensive-data-exploration-with-python
数据预处理源码(详细注释)git 地址:
https://github.com/xuman-Amy/kaggel
引入要用的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns #统计绘图
from sklearn.preprocessing import StandardScaler
from scipy.stats import norm
from scipy import stats #统计
import warnings
warnings.filterwarnings('ignore')
#画图直接显示
%matplotlib inline 加载数据 ——训练集 测试集 train test
#bring in the six packs
df_train = pd.read_csv('G:Machine learning\\kaggel\\house prices\\train.csv')
df_test = pd.read_csv('G:Machine learning\\kaggel\\house prices\\test.csv')粗略查看数据各字段 利用常识简单分析之间的联系
#check the decoration
#数据.columns 各列名称 分析有哪些数据,可以将数据分为numerical (数值型)和categorical(类别型)
df_train.columns
1、分析【SalePrice】
#describe函数用来数据的快速统计汇总
df_train['SalePrice'].describe()
可以看出min大于0,所以不用担心0的问题了
【用直方图看下数据分布】
#seaborn 用法 https://zhuanlan.zhihu.com/p/24464836
#seaborn的displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,
#增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途
sns.distplot(df_train['SalePrice'])
【峰值和偏态】
#show skewness and Kurtosis 偏态和峰度
print("Skewness : %f " % df_train['SalePrice'].skew())
print("Kurtosis : %f " % df_train['SalePrice'].kurt())

【分析 与价钱有关的特征值】
分析价钱可能会与'GrLivArea' and 'TotalBsmtSF'. 'OverallQual' and 'YearBuilt'. 有关
分别查看关系
【 GrLivArea】
#scatter plot Grlivearea / SalePrice
var = 'GrLivArea'
#pd.concat 函数 可以将数据根据不同的轴作简单的融合 axis = 0-->代表行 axis = 1 --> 代表列
data = pd.concat([df_train['SalePrice'],df_train[var]],axis = 1)
data.plot.scatter(x = var, y = 'SalePrice',ylim = (0,800000));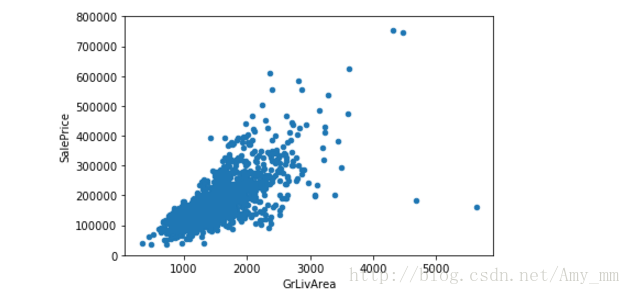
看起来 二者呈线性分布
【TotalBsmtSF】
#scatter plot saleprice / totalbsmtsf
var = 'TotalBsmtSF'
data = pd.concat([df_train['SalePrice'],df_train[var]],axis = 1)
data.plot.scatter(x = var, y = 'SalePrice',ylim = (0,800000))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









