







本文分两个部分,第一部分讲解transformers的网络架构和原理,第二部分讲解如何将其应用到CV领域;
1,transformers的网络架构
《Attention Is All You Need》是一篇Google提出的将Attention思想发挥到极致的论文。这篇论文中提出一个全新的模型,叫 Transformer,抛弃了以往深度学习任务里面使用到的 CNN 和 RNN。目前大热的Bert就是基于Transformer构建的,这个模型广泛应用于NLP领域,例如机器翻译,问答系统,文本摘要和语音识别等等方向。
如下是Transformer的两个结构示意图:
可以看到transformers主要由多个encoder和多个decoder层叠加而成。
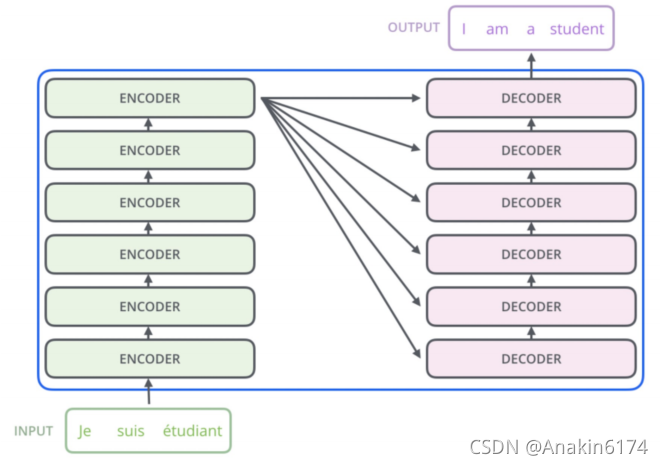
至于encoder和decoder的细节可以从论文中的架构图看到:
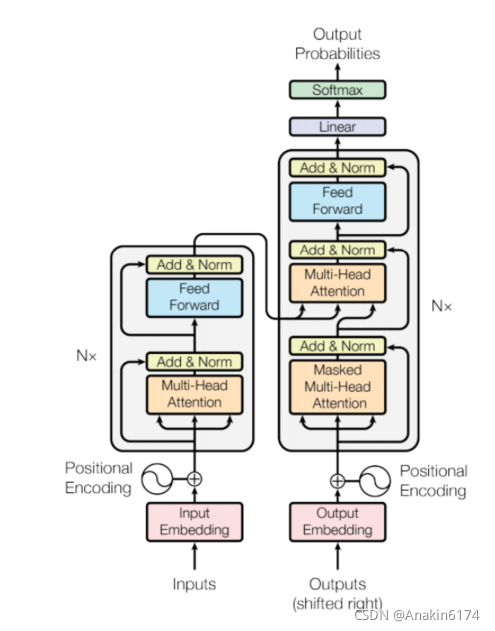
模型大致分为 Encoder (编码器)和 Decoder (解码器)两个部分,分别对应上图中的左右两部分。
其中编码器由N个相同的层堆叠在一起(我们后面的实验取N=6),每一层又有两个子层。
第一个子层是一个 Multi-Head Attention (多头的自注意机制),第二个子层是一个简单的 Feed Forward (全连接前馈网络)。两个子层都添加了一个残差连接+layer normalization的操作。
模型的解码器同样是堆叠了N个相同的层,不过和编码器中每层的结构稍有不同。对于解码器的每一层,除了编码器中的两个子层 Multi-Head Attention 和 Feed Forward ,解码器还包含一个子层 Masked Multi-Head Attention,如图中所示每个子层同样也用了residual以及layer normalization。
模型的输入由 Input Embedding 和 Positional Encoding (位置编码)两部分组合而成,模型的输出由Decoder的输出简单的经过softmax得到。
2,为什么transformers能够work?
transformers能够在NLP领域大放异彩,除了应用自注意力机制,还应用了多个技巧,使其能够在各个任务中取得超前的成绩。
(1),融入位置信息
位置信息对于序列的表示至关重要。两个句子只要包含的词相同,即使顺序不同,他们的表示也完全不同。为了解决这个问题,需要为序列中每个输入的向量引入不同的位置信息以示区分。transformer采用位置编码的形式,用sin和cos函数来进行编码。
(2),输入向量角色信息
原始的注意力模型在计算注意力时直接使用两个输入向量,然后直接使用得到的注意力对同一个输入向量加权,这样导致一个输入向量同事承担了三者角色查询、键和值。更好的做法是对不同的角色使用不同的向量,为了做到这一点,可以使用不同的参数矩阵对原始输入向量做线性变换,从而让不同的变换结果承担不同的角色;
(3),多层注意力机制
多层注意力机制可以提取到更高层的信息。如果直接堆叠多层注意力机制模型,由于每层的变化都是线性的,最终的模型依然是线性的。因此,为了增强模型的表示能力,在每层注意力计算之后,增加一层非线性的多层感知机。同时,为了使模型更容易学习,还可以使用归一化,残差连接等技巧。
(4),自注意力机制计算结果互斥
由于自注意力结果需要经过归一化,即结果之间是互斥的,无法同时关注多个输入。因此,如果使用多组自注意力模型产生多组不同的注意力结果,则不同的注意力模型可能关注到不同的输入上,从而增强模型的表达能力,因此有多头注意力模型:multi-head self-attention;
3,transformers的工程实现
由于其强大威力,pytroch已经集成了现成的框架可以使用。datawhale的教程中也给出了具体的实现方式,由于代码篇幅太长,细节很多,这里不在重复贴出。
4,使用transformer实现OCR字符识别
本文OCR实验使用的数据集基于 ICDAR2015 Incidental Scene Text 中的 Task 4.3: Word Recognition ,这是一个单词识别任务。该数据集包含了众多自然场景图像中出现的文字区域,原始数据中训练集含有4468张图像,测试集含有2077张图像,他们都是从原始大图中依据文字区域的bounding box裁剪出来的,图像中的文字基本处于图片中心位置。
如何将transformer引入OCR?
首先,我们知道,transformer被广泛应用在NLP领域中,可以解决类似机器翻译这样的sequence tosequence类的问题。
如果从把OCR问题看作是一个sequence to sequence预测问题这个角度,使用transformer解决OCR问题貌似是一个非常自然和顺畅的想法,剩下的问题只是如何将图片的信息构造成transformer想要的,类似于 word embedding 形式的输入。
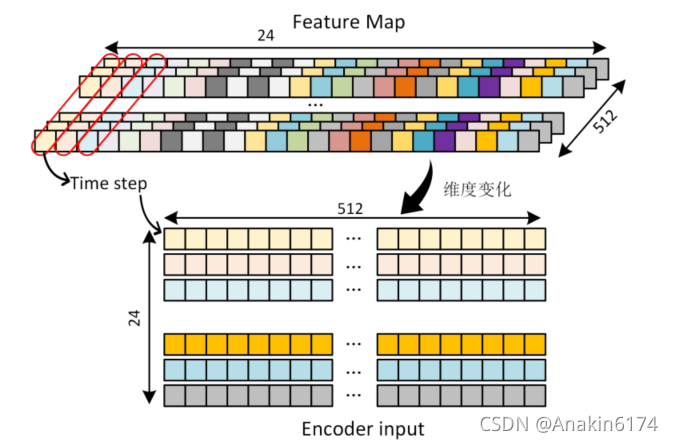
回到我们的任务,既然待预测的图片都是长条状的,文字基本都是水平排列,那么我们将特征图沿水平
方向进行整合,得到的每一个embedding可以认为是图片纵向的某个切片的特征,将这样的特征序列交给transformer,利用其强大的attention能力来完成预测。因此,基于以上分析,我们将模型框架的pipeline定义为下图所示的形式:
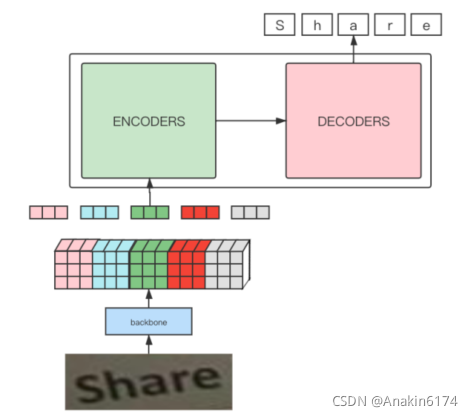
通过观察上图可以发现,整个pipeline和利用transformer训练机器翻译的流程是基本一致的,之间的差异主要是多了借助一个CNN网络作为backbone提取图像特征得到input embedding的过程。关于构造transformer的输入embedding这部分的设计,是本文的重点,也是整个算法能够work的关
键。
模型构建
代码通过 make_ocr_model 和 OCR_EncoderDecoder 类完成模型结构搭建。可以从 make_ocr_model 这个函数看起,该函数首先调用了pytorch中预训练的Resnet-18作为backbone以提取图像特征,此处也可以根据自己需要调整为其他的网络,但需要重点关注的是网络的下采样倍数,以及最后一层特征图的channel_num,相关模块的参数需要同步调整。之后调用了OCR_EncoderDecoder 类完成transformer的搭建。最后对模型参数进行初始化。
在 OCR_EncoderDecoder 类中,该类相当于是一个transformer各基础组件的拼装线,包括 encoder和 decoder 等,其初始参数是已存在的基本组件,其基本组件代码都在transformer.py文件中。
datawhale提供的教程中提供了非常详细的代码实现,具体的代码实现参考:https://github.com/datawhalechina/dive-into-cv-pytorch ;
感谢Datawhale社区提供的精彩教程!
参考文献:
1,the annotated transformer
2, dive into cv by pytorch














 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









