






前言
Transformer 是Google 2017 年提出来的,紧接着 2018年OpenAI 就基于Transformer 发布了GPT1,Google 属于是起个大早,赶了个晚集。
为什么 Transformer 比之前CNN、RNN 神经网络架构有优势呢?
最关键的就是“Attention” 注意力机制。
为了让大家通俗理解,我举个例子来说明。
假设有一句话:“The boy who was bitten by a spider turned into Spiderman.”(被蜘蛛咬到的男孩变成了蜘蛛侠。)
在传统的循环神经网络(RNN)中,模型可能会很难系“boy”和“Spiderman”之间的关系,因为它们在句子中相隔很远。
RNN 严格从前往后一词一词地处理文本,随着句子长度的增加,早期词的信息可能会被遗忘。而在Transformer中,自注意力机制允许模型在处理“Spiderman”这个词时,直接“查看”句子中的每个词,包括“boy”和“bitten by a spider”等关键信息,这样是可以理解整个句子的意义,我们经常说的上下文长度就是理解的最大token 范围,GPT 3是2048.
总的来说,Transformer 通过自注意力机制在处理文本时提供了一种“全局观”,能够看到句子中所有的词并评估它们之间的关系,提升了模型对长距离依赖和复杂语义的理解能力。
这就好比你正在看一篇文章,当读到一段复杂晦涩的文本时,正常人会怎么做?
肯定不是机械地从头到尾读过去,而是会跳来跳去,抓住重要的词或句子,理解上下文的关系,并根据需要回顾前文,你的注意力会集中在文章的关键信息上,而不是一字不漏地读每个字。这个就是GPT 相比之前传统NLP 算法的不同之处,以前的算法都是一个字一个字的理解,一次关注一个词,构建很多层,当层次很深的时候,会忘了前面的信息。
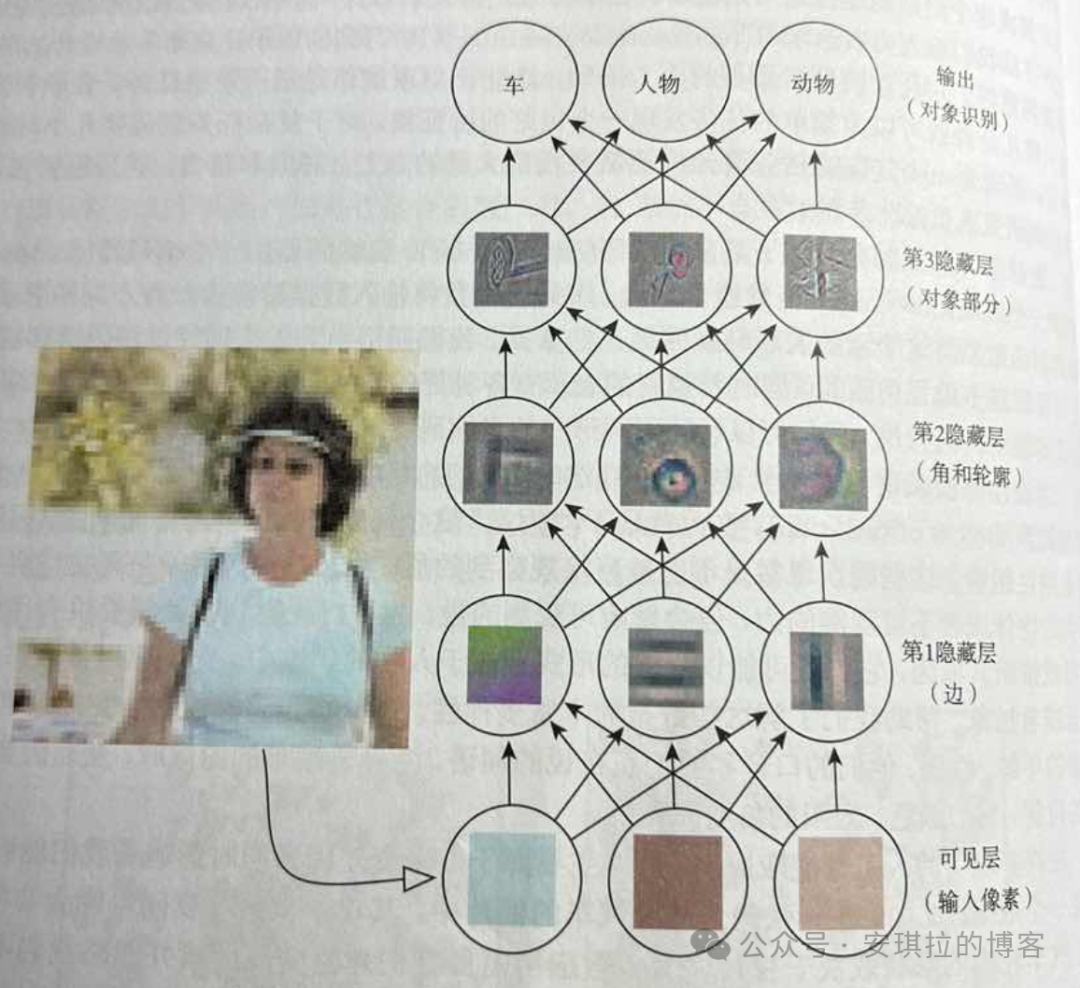
下面这张图是我从花书中拍的,这个是做了些简化,可以看到传统CNN深度学习是从下往上,有很多隐藏层用户抽象和转换信息,隐藏层会有很多。
这里重提一下上一篇文章说到的大模型的本质:根据给定的文本序列,预测出接下来的文本内容。
举个例子,当你的给大模型的输入是“中国的首都是__”,大模型会根据之前预训练的数据,给出下一个可能的文本序列和对应的概率分布,如下图所示。
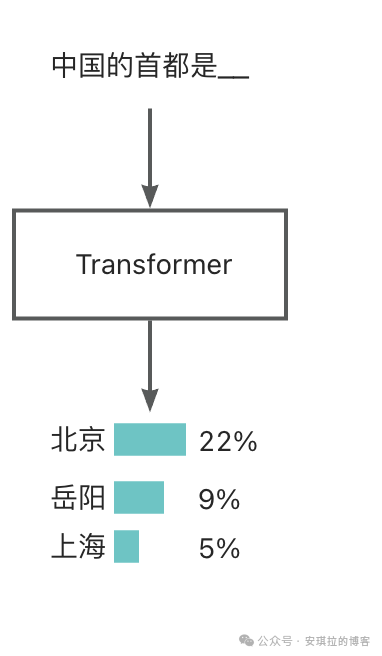
所以大模型的核心就是根据前面的文本序列(中国的首都是),给出所有候选词(北京、岳阳、上海),以及概率分布(对应的概率值)。
那这个怎么来实现的呢?
我们先用上篇文章的例子来描述这个事情。还记得我们上篇文章讲的西瓜的三个属性吗?色泽、根蒂、敲声。
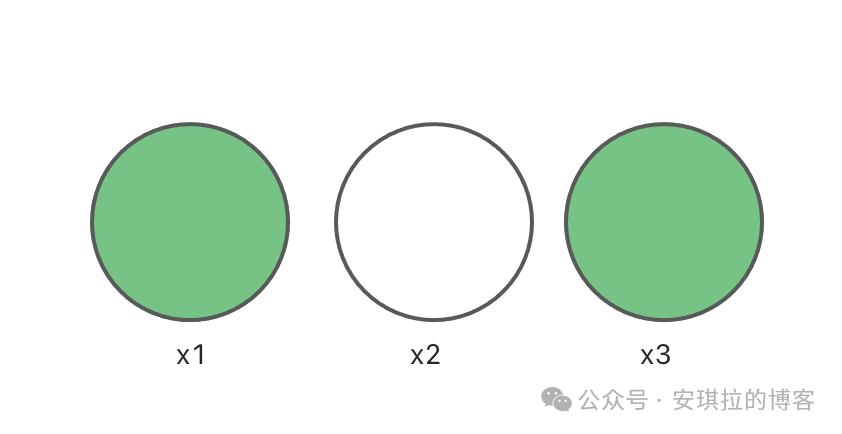
那我们可以用 3 维向量来描述西瓜(3个维度分别代表西瓜的3个属性),如果有三个瓜分别是 x1: [1, 0, 1], x2:[0, 1, 0], x3:[1, 0, 0] 3 维向量中第1 个维度值的含义可以这么理解:1 代表瓜绿色,0代表不绿,如下图,第一个和第三个瓜都是绿色,第二个瓜不绿,实际上这个值范围可以很大,颜色嘛,我们为了便于讲解,简化成了只用0 和 1简单表示瓜是否绿。
那我们把所有单词,以及标点符号都用向量来描述,比如第一个维度描述是否是名词,第二个维度描述是否是动物,等等,那GPT 3里面用了多少个维度来描述一个词(token)呢,12288维度,1万多个维度描述1个词,哈哈。
接下来,我们讲解一下大模型的实现步骤:首先,你输入的内容会被切分成许多小片段,这些小的片段叫做“Token”,一般文本里面片段都是指单词。
一个token 对应的是一个向量,向量的表达就是一组数字,例如上面西瓜的例子,就是三维向量,相当于用向量来表征 token 的含义。
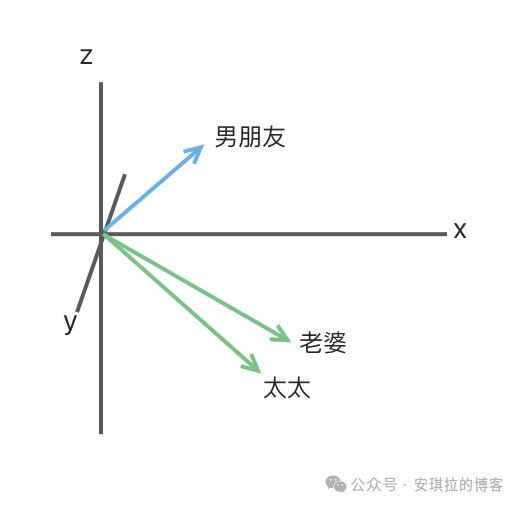
这样有个什么好处,如下图所示,如果把向量比如高纬空间中的坐标,那意思相近的二个 token 在空间中的距离也会非常接近,比如“老婆”和“太太”距离就很近,和“男朋友”就很远。
把西瓜的属性用向量编码之后,可以很方便看出 1号瓜(x1)和 3号瓜(x3) 相似度比x2 更高, 大家可以画一个三维坐标轴,x、y、z轴,上面三个西瓜的坐标点画下,基本就知道1号瓜和3号瓜距离比较近,而和2号瓜距离较远,拿中国的首都这个案例来说,就是北京离“中国的首都” 这个序列的向量距离最近,而岳阳比北京离“中国的首都”距离远。
那回到让大模型回答 “中国的首都是__”这个问题的时候,大模型实际就是去高维向量空间里面找离“中国的首都” 最近的向量,把前20个向量代表的词作为候选词,比如就是北京、上海、深圳,然后把每个词和“中国的首都”的距离转成概率,这个过程叫sofamax,就是把距离转成0-1之间的值,并且加起来和等于1。
这也是为什么大模型会胡说八道的原因,也叫“幻觉”,因为只要是概率预测模型,就不保证100%准确,不像传统程序,if else的逻辑是 100%明确的,理解了这点,也就理解了为什么到目前为止大模型还没有出现爆发式的应用出现,因为没法保障100%准确,就没法让大模型产出的结果直接对客,尤其是需要100% 准确无误的应用场景,大模型结果需要人的介入,应用场景就一定是辅助人,帮人提效,比如不敢直接让大模型来帮医生写诊断报告,反而是大模型写完,医生检查一下,所以当下大模型都是Copilot:辅助人而不是代替人。
其实讲到这里,我已经把大模型的核心机制讲完了,对的,你没看错,你看到这里,你可以跟人讲你已经理解离大模型的基本原理。后面的内容就是原理层的东西,如果你只是为了理解大模型的基本概念,跟人家交流大模型的时候没有障碍,看到这里就足够了。
下面有张图,相信搞大模型的应该见过很多次,就是Transformer 的架构,看不懂也没关系,我会分模块解释。
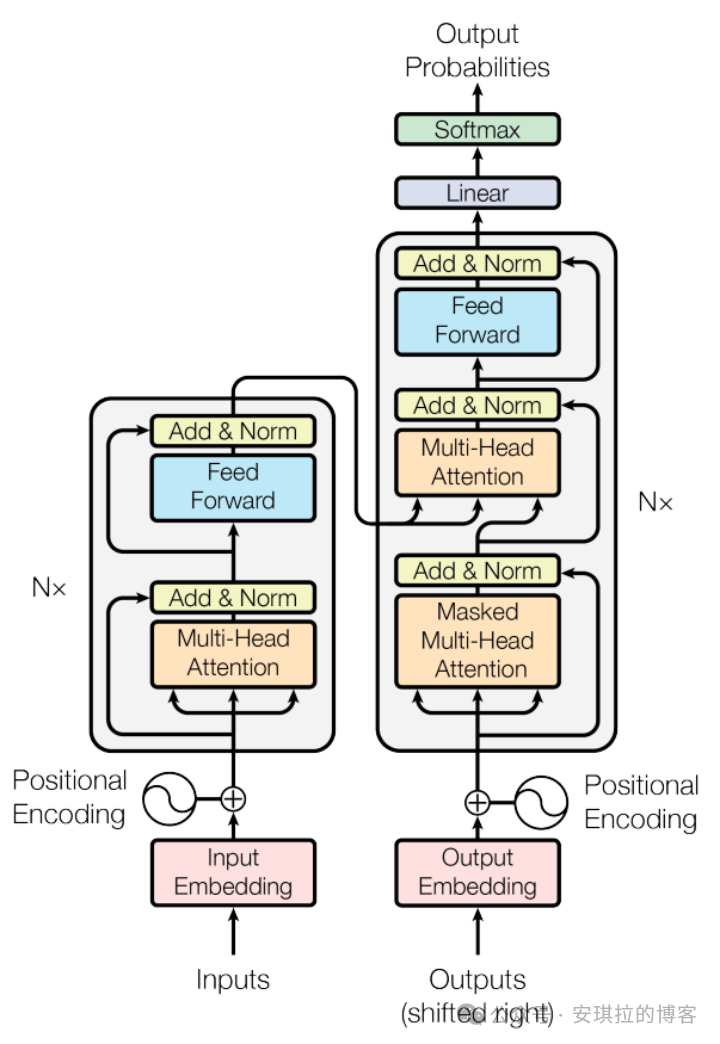
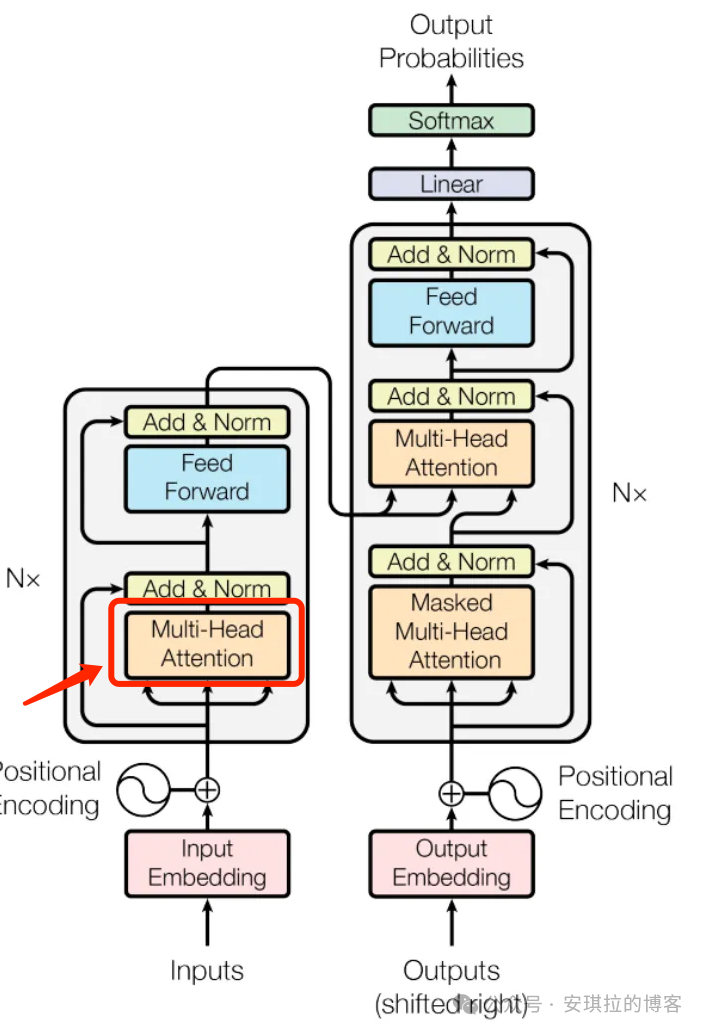
首先分了二个部分:左边是输入,右边是输出。可以看到左边输入之后,有个淡粉色的部分,叫“Input Embedding”,词嵌入。什么意思?就是对句子做分词,然后用12288 维的向量来表示每个词,这个步骤每个词都只是最初始的向量值,在GPT3里面,英文单词加各类符号一共5w+多个向量,构成了基础的词向量库。但是这些初始的词向量在不同的上下文里面会持续更新,这就是 Transfromer 中 Attention(注意力)最核心的部分,举个例子就你懂了。比如 “A machine learning model” 和 “A fashion model”, model 这个词在不同上下文中是完全不同的含义,前一句话代表机器学习的模型,后面代表模特,所以注意力机制就是通过上下文的信息不断让每个词向量更精确,model 这个词在高维向量空间中有好几个,一个不带具体语义的抽象概念(有点像Java 中的抽象类),一个是算法模型,一个是模特。所以注意力机制是找到上下文的哪些词,来更新某些词的含义,这里含义的表达形式就是向量,所以就是通过上下文来更新向量。这些词向量经过 [注意力模块]处理,就是下面 Transformer 里面左边黄色部分,有个单词叫 Attention 就是注意力,Multi-Head 晚点会解释。
Attention(注意力)的作用就是让向量之间可以互相交流,通过相互传递信息来更新自己的值,举个网上看到的例子。
再之后,这些向量会经过另一种处理,叫做[Feed Forward](前馈层),上图左侧蓝色的部分,也有的叫做多层感知机,这个阶段所做的事情有点类似于对每个词向量问一系列问题,根据问题的回答来不断修正向量,还是拿“A fashion model”(一个时尚模特)的 model 这个词来说,比如会问:是否是职业?回答是,更新model 向量值,问:是否是数学名词,回答否,更新model 向量值。无论是[Attention] 还是 [Feed Forward] 本质都是大量的矩阵乘法,上图 Transform 左边的 Nx 就是把 注意力和前馈层二个模块重复做N 次,在论文这个翻译任务里,作者的N 是6,也就是做了6次。
这么做最后的目标是,能将整段文字的所有关键信息,融入到序列的最后一个向量,这个向量的值代表下一个token 的概率分布,就是上面“中国的首都是”的例子, 从候选词中选概率最大的词输出。整个大模型的工作机制就是给一段初始文本,大模型根据初始文本产出下一个词的概率分布,然后选一个词,加到上一段文本中,继续产出下一个词的概率分布,依次循环往复。兄弟们,这部分概念懂了吧!
后面都是各种向量的矩阵计算,这部分我得好好想想怎么讲清楚。
最后
当你向大模型发一句话,大模型是如何理解你的问题并找到答案的?
1.输入解释和嵌入 当你输入一个长字符串(问题或文本),模型会先将这个字符串转化为模型可以理解的形式:
-
分词(Tokenization):输入的长字符串会被分割成一个个小的文字单元,通常称为“Token”。例如,“What is the capital of France?(翻译:法国的首都在哪?)” 可能会被分割成 [“What”, “is”, “the”, “capital”, “of”, “France”, “?”]。
-
词嵌入(Word Embedding):我不喜欢把Embedding 翻译成嵌入,感觉丢失了原来的意思。实际操作就是每个Token 会被转换成一个高维向量,称为Embedding 向量。这些向量可以捕捉到单词之间的语义相似性,例如,“Paris(巴黎)”和“France” 在语义空间中可能是接近的。
2.自注意力机制的全局处理 注意力机制(包括自注意力机制和多头注意力机制)并不仅仅局限于处理单个词,而是关注整个序列中的各个位置。因此,它们能够处理你输入的整个长字符串,而不仅仅是单个词。
-
生成Query, Key, Value:对整个序列中的每个词,都生成对应的Query, Key和Value向量。例如,对于句子 [“What”, “is”, “the”, “capital”, “of”, “France”, “?”],每个词(Token)都有它们各自的Query, Key和Value向量。
-
计算全局注意力得分:引入自注意力机制,模型计算每个词的Query向量与其他所有词的Key向量的相似度。这样,对每个词来说,它都有了一个与其他所有词的相似度得分。因此,自注意力机制并不是局限于单个词的处理,而是全局性地考虑整个输入序列中的所有词。
-
加权求和生成新的表示:使用计算出的注意力得分对所有词的Value向量进行加权求和,进而生成每个词的新表示。这些表示考虑了全句子中其他词的影响,从而使得模型能够捕捉长距离的依赖关系和复杂的上下文。
3.多层次处理 大模型通常由多个层级的Transformer模块组成,每一层都有独立的多头注意力机制。这使得模型可以在不同层次上反复应用注意力机制,逐步提高对输入文本的理解。逐层处理:每一层的输出,都会成为下一层的输入。每经过一层,模型就会更新对输入序列的理解,并生成越来越高层次的语义表示。
4.最后的预测 当所有层的计算完成后,模型会生成一个高维向量表示序列中每个Token的综合信息。然后通过一些解码步骤,将这些高维表示映射回原始的输出空间,比如预测下一个单词、句子分类或回答问题。模型利用已经训练好的知识和得到的语义表示来生成一个符合你的提问内容的回答。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









