






前言
大型语言模型(LLMs)在自然语言处理领域展现出了巨大的潜力和广泛的应用前景。在众多LLMs中,DeepSeek-V3、Qwen2.5、Llama3.1、Claude-3.5和GPT-4o以其卓越的性能和独特的特点脱颖而出。本文将对这五个模型进行全面的比较分析,探讨它们在不同领域的优势和劣势。
一、模型概述
- DeepSeek-V3
DeepSeek-V3是一款基于Mixture of Experts(MoE)架构的模型。MoE模型的特点在于,它针对特定任务动态激活参数子集,从而提高了效率。DeepSeek-V3在总参数达到671B的情况下,仅激活了37B的参数用于执行任务。这种高效的参数利用方式使得DeepSeek-V3在多个领域都展现出了强大的性能。
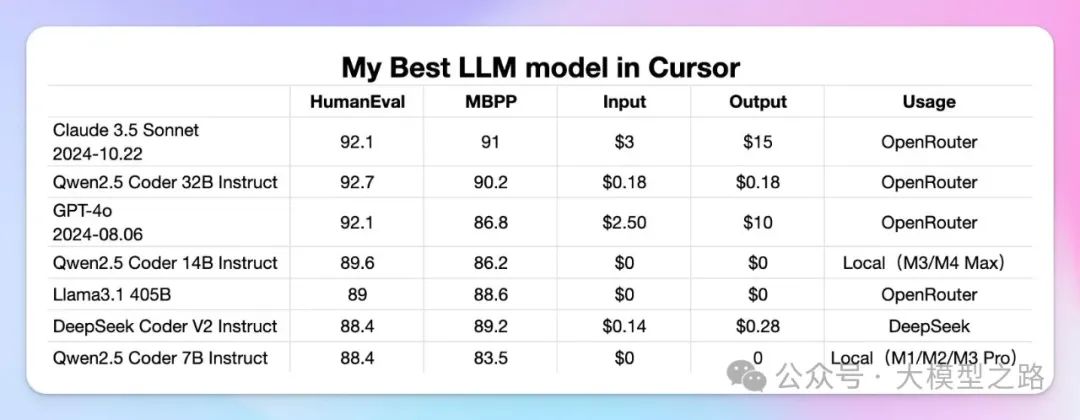
- Qwen2.5
Qwen2.5是一款典型的Dense模型,它的所有参数都被用于每个任务。这使得Qwen2.5在处理任务时表现出一致但计算成本较高的特点。Qwen2.5拥有72B的参数,这使得它在处理复杂任务时具有一定的优势。然而,Dense模型的缺点在于,在处理大量任务时,其计算资源消耗较大。
- Llama3.1
Llama3.1同样是一款Dense模型,其参数规模达到了405B。这使得Llama3.1在处理自然语言任务时具有强大的生成能力和丰富的上下文理解能力。然而,与Qwen2.5类似,Llama3.1在处理大量任务时也会面临计算资源消耗较大的问题。
- Claude-3.5(Sonnet-1022)
Claude-3.5是一款在英语问答领域表现尤为出色的模型。其独特的架构设计使得它在处理复杂问题、生成结构化响应以及严格遵循输入提示方面表现出色。Claude-3.5的英语问答能力得到了广泛的认可,成为许多英语QA应用的首选模型。
- GPT-4o
GPT-4o是一款具有强大多语言能力的模型。它在处理多语言问答任务时表现出色,尤其在中文和其他语言的对比测试中,GPT-4o展现出了均衡的精确度和效率。这使得GPT-4o在多语言应用场景中具有广泛的应用前景。
二、性能比较分析
(一)英语能力测评
综合理解能力(MMLU):在 MMLU(大规模多任务语言理解)测试中,DeepSeek-V3 表现卓越,达到 88.5% 的准确率,在 MMLU-Redux 测试中更是提升至 89.1%。这一成绩彰显了其强大的多任务理解能力,能够广泛且深入地理解各种主题知识。Claude-3.5 在这一测试中的表现虽然不及 DeepSeek-V3,但也展现出了较高的水准,反映出它在英语知识储备和理解方面的扎实功底。
推理与问答能力:DROP 测试聚焦于文本的数值和逻辑推理,DeepSeek-V3 以 91.6% 的 3-shot F1 得分位居榜首,体现出其卓越的推理能力,能够精准解析文本中的复杂逻辑关系并得出准确结论。在 IF-Eval(提示严格度)测试中,Claude-3.5 以 86.5% 的成绩领先,凸显其对输入提示的严格遵循和任务完成的高精准度,在复杂问答和需要严格按照指令执行的场景中优势明显。
通用问答与简单问答:在 GPQA-Diamond(通用问答严格标准测试)中,Claude-3.5 以 65% 的 Pass@1 准确率独占鳌头,展现出在通用问答领域的深厚实力;而 SimpleQA 测试中,各模型的表现则呈现出一定差异,反映出不同模型在简单问答任务处理上的能力区别。
(二)代码能力测评
编码与软件工程能力:Qwen2.5 在编码相关测试中大放异彩,在 HumanEval-Mul 测试中,解决编码问题的准确率高达 77.3%,在 Aider-Edit 测试中,代码编辑和调试准确率达到 84.2%,均为各模型中的最佳成绩。这表明 Qwen2.5 在实际编程任务中能够为开发者提供高效、准确的支持,无论是代码生成还是代码优化方面都具备显著优势。
多语言编程与竞赛编程:在 Aider-Polyglot 测试中,各模型在多编程语言任务中的表现有所不同,Qwen2.5 展现出良好的多语言编程适应性;而在 Codeforces 竞赛编程测试中,DeepSeek-V3 以 51.6% 的百分位数得分表现突出,体现出其在复杂编程挑战中的强大竞争力。
(三)数学能力测评
在数学领域的测试中,DeepSeek-V3 在多个测试中表现优异。AIME 2024(美国数学邀请赛风格问题测试)中,它以 39.2% 的 Pass@1 准确率领先;在 MATH-500(500 道高级数学问题精确匹配测试)和 CNMO 2024(复杂数值和数学问题基准测试)中也展现出强大的数学解题能力。这得益于其高效的架构和大量的数学知识学习,能够准确解析复杂的数学问题并给出正确答案。
(四)中文能力测评
中文理解与歧义消解:在 CLUEWSC(中文特定歧义消解任务评估)测试中,DeepSeek-V3 以 90.9% 的精确匹配率遥遥领先,在 C-Eval(中文多领域文本理解测试)中也取得了 86.5% 的高分。这充分证明了它在中文语言理解和歧义处理方面的卓越能力,能够深入理解中文语境中的微妙含义,准确完成任务。
中文简单问答:C-SimpleQA 测试中,各模型在中文简单问答任务上的表现也有所不同,DeepSeek-V3 同样展现出了良好的性能,能够快速准确地回答常见的中文问题,为中文用户提供便捷的交互体验。
三、模型特点与优势分析
- DeepSeek-V3
DeepSeek-V3的MoE架构使得其能够高效地利用参数资源。这种架构在处理多个领域任务时表现出了强大的泛化能力。DeepSeek-V3在英语基准测试、数学基准测试和中文基准测试中均取得了出色的成绩,这证明了其全面而强大的性能。此外,DeepSeek-V3还具有较高的灵活性和可扩展性,能够适应不同领域和任务的需求。
- Qwen2.5
Qwen2.5的Dense架构使得其在处理复杂任务时具有一定的优势。尽管Dense模型在计算资源消耗方面较大,但Qwen2.5通过优化算法和硬件加速等手段,有效地降低了计算成本。这使得Qwen2.5在处理编程问题和代码编辑等任务时表现出色。此外,Qwen2.5还具有强大的上下文理解能力和丰富的生成能力,能够满足不同领域和任务的需求。
- Llama3.1
Llama3.1同样是一款具有强大生成能力和上下文理解能力的Dense模型。其庞大的参数规模使得Llama3.1在处理自然语言任务时具有更高的准确性。然而,与Qwen2.5类似,Llama3.1在处理大量任务时也会面临计算资源消耗较大的问题。因此,在选择Llama3.1时,需要权衡其性能和计算成本之间的关系。
- Claude-3.5
Claude-3.5在英语问答领域表现出色。其独特的架构设计使得它在处理复杂问题、生成结构化响应以及严格遵循输入提示方面表现出色。这使得Claude-3.5成为许多英语QA应用的首选模型。此外,Claude-3.5还具有较高的可扩展性和灵活性,能够适应不同领域和任务的需求。然而,Claude-3.5在其他领域的性能表现相对一般,因此在选择时需要考虑其应用场景和任务需求。
- GPT-4o
GPT-4o是一款具有强大多语言能力的模型。它在处理多语言问答任务时表现出色,尤其在中文和其他语言的对比测试中,GPT-4o展现出了均衡的精确度和效率。这使得GPT-4o在多语言应用场景中具有广泛的应用前景。此外,GPT-4o还具有较高的灵活性和可扩展性,能够适应不同领域和任务的需求。然而,与DeepSeek-V3和Claude-3.5等模型相比,GPT-4o在某些特定领域的性能表现可能稍显不足。
本文通过对DeepSeek-V3、Qwen2.5、Llama3.1、Claude-3.5和GPT-4o这五个大型语言模型进行全面的比较分析,探讨了它们在不同领域的优势和劣势。研究发现,DeepSeek-V3以其高效的MoE架构和全面的性能表现脱颖而出,成为最佳通才模型。而Claude-3.5在英语问答领域表现出色,成为最佳英语QA模型。Qwen2.5则在编程和代码编辑等任务中展现出强大的性能,成为最佳编码模型。GPT-4o则以其强大的多语言能力在多语言应用场景中具有广泛的应用前景。未来,随着人工智能技术的不断发展,大型语言模型将在更多领域发挥重要作用。因此,我们需要继续深入研究大型语言模型的性能特点和优势劣势,以更好地满足相关领域的需求。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









