






1. SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug-and-play Inference Acceleration
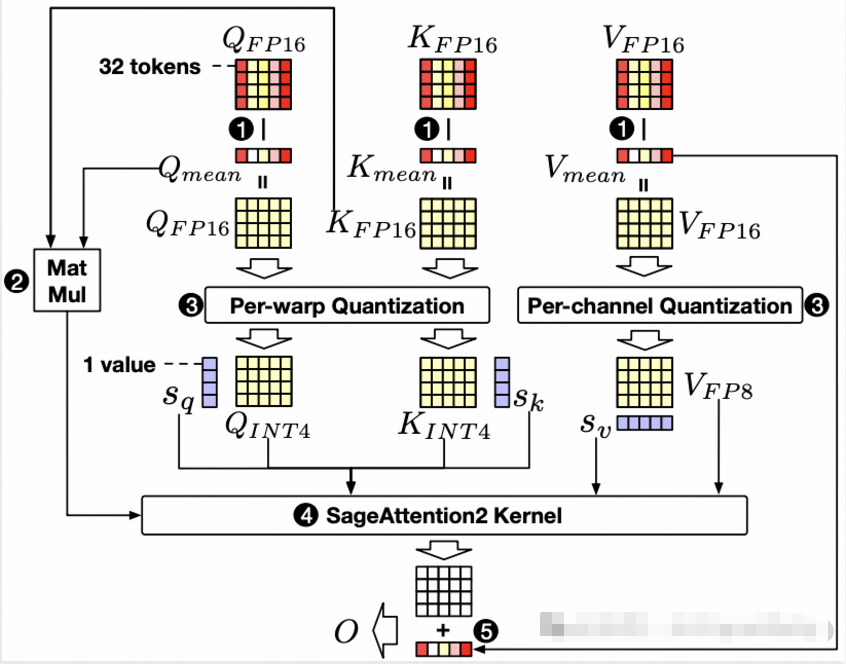
尽管线性层的量化已被广泛使用,但将其应用于加速注意力过程的应用仍然有限。SageAttention 利用了8位矩阵乘法、结合16位累加器的16位矩阵乘法,以及精度增强方法,实现了与 FlashAttention2 相比快2倍的准确内核。为了在保持精度的同时进一步提高注意力计算的效率,我们提出了 SageAttention2,它利用了显著更快的4位矩阵乘法(Matmul)以及额外的精度增强技术。首先,我们建议将矩阵(Q, K)在warp级粒度上量化为INT4,将矩阵(P), V)量化为FP8。其次,我们提出了一种方法来平滑 Q 和 V,以增强使用 INT4 QK 和 FP8 PV 的注意力的准确性。第三,我们分析了跨时间步和层的量化精度,然后提出了一个自适应量化方法,以确保各种模型的端到端指标。SageAttention2 的每秒操作数(OPS)在 RTX4090 上分别比 FlashAttention2 和 xformers 高约3倍和5倍。实验表明,我们的方法在各种模型中导致了可忽略不计的端到端指标损失,包括大语言处理、图像生成和视频生成等模型。代码可在 https://github.com/thu-ml/SageAttention 。
论文: https://arxiv.org/pdf/2411.10958
2. Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents
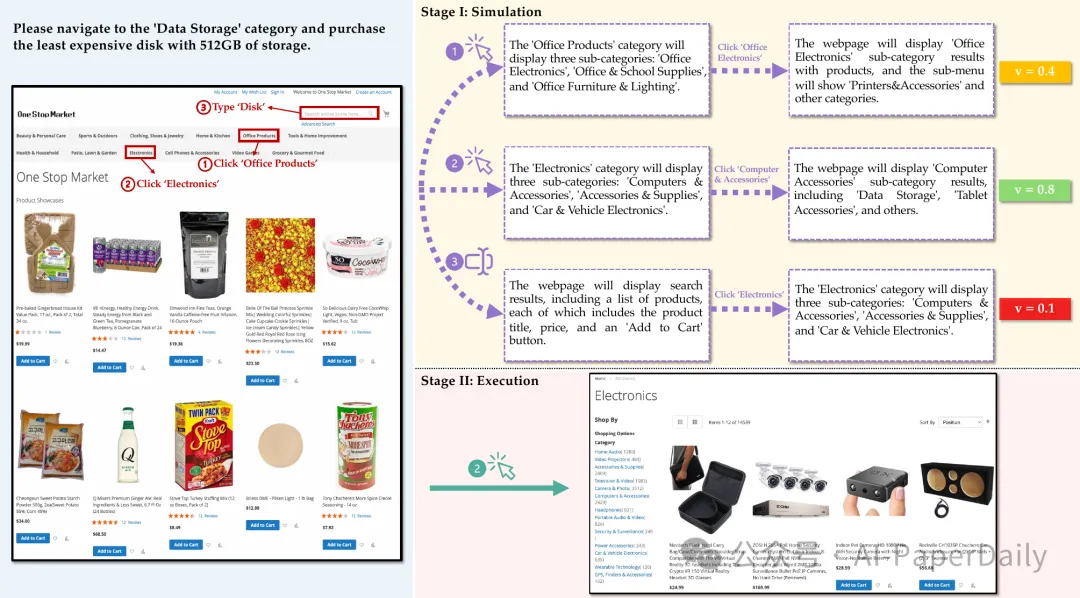
语言Agent在自动化网络任务方面展示了有前景的能力,然而它们目前的反应式方法仍然远不及人类的表现。虽然结合先进的规划算法,尤其是树搜索方法,可以增强这些Agent的表现,但在实时网站上直接实施树搜索会带来重大的安全风险和实际限制,因为这涉及到不可撤销的操作,如确认购买。本文提出了一种新的范式,该范式将模型驱动的规划与语言Agent相结合,在复杂网络环境中首次创新地使用大型语言模型(LLMs)作为世界模型。我们的方法WebDreamer基于一个关键洞察,即LLMs天生包含了关于网站结构和功能的全面知识。具体而言,WebDreamer使用LLMs模拟每个候选动作(例如,“如果我点击这个按钮会发生什么?”)的自然语言描述结果,并评估这些想象中的结果以确定每一步的最佳行动。在两个具有在线交互的代表性网络Agent基准测试——VisualWebArena和Mind2Web-live——上的实验证明,WebDreamer在反应式基线之上取得了显著的改进。通过证明LLMs作为网络环境中的世界模型的可行性,这项工作为自动化网络交互的范式转变奠定了基础。
论文: https://arxiv.org/pdf/2411.06559
3. VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models
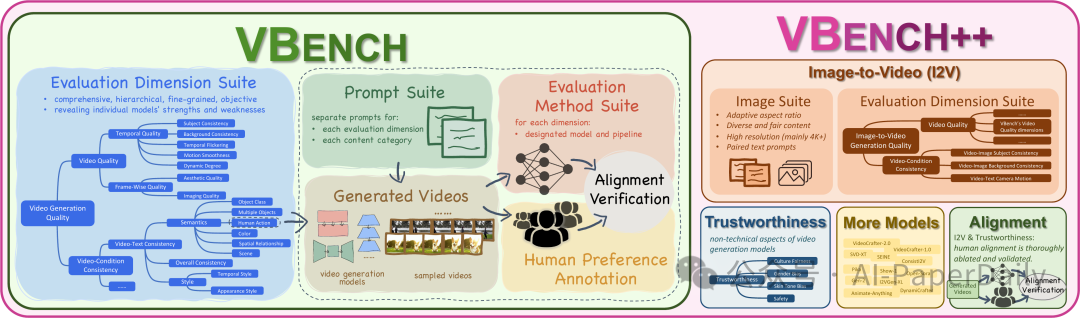
视频生成已经发生了显著的进步,然而评估这些模型仍然是一项挑战。一个全面的视频生成评估基准至关重要:1)现有的指标未能完全与人类感知对齐;2)理想的评估系统应该提供见解以指导视频生成的未来开发。为此,我们提出了VBench,这是一个全面的基准套件,将“视频生成质量”分解为具体、层次化和分离的维度,每个维度都有定制的提示和评估方法。VBench有几个吸引人的特性:1)全面的维度:VBench包括视频生成的16个维度(例如,主体身份不一致性、运动流畅性、时间闪烁和空间关系等)。精细粒度的评估指标揭示了各个模型的优势和劣势。2)人类对齐:我们还提供了一个人类偏好注释数据集,以分别验证我们的基准与每个评估维度的人类感知对齐。3)有价值的见解:我们研究了当前模型在各种评估维度和不同内容类型上的能力,并调查了视频和图像生成模型之间的差距。4)多功能基准测试:VBench++支持评估文本到视频和图像到视频。我们提出了一个高质量的图像套件,具有自适应纵横比,以在不同的图像到视频生成设置中实现公平的评估。除了评估技术质量,VBench++还评估了视频生成模型的可信度,提供了一个更全面的模型性能视图。5)全面开源:我们全面开源了VBench++,并不断向我们的排行榜添加新的视频生成模型,以推动视频生成领域的进步。
论文: https://arxiv.org/pdf/2411.13503
4. VideoAutoArena: An Automated Arena for Evaluating Large Multimodal Models in Video Analysis through User Simulation
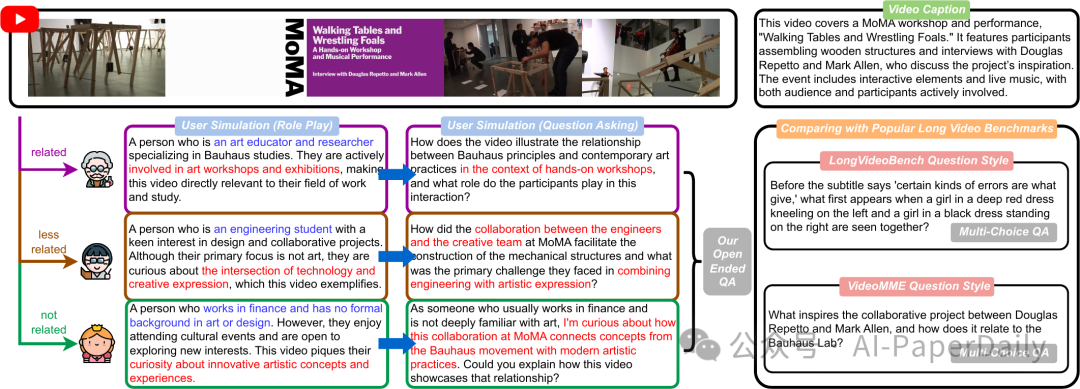
多模态模型(LMMs)具有先进视频分析能力。然而,大多数评估仍然依赖于基准如VideoMME和LongVideoBench中的传统方法,如多项选择题,这些方法容易缺乏深度,无法捕捉现实世界用户复杂的需求。为了解决这一局限性——由于视频任务的人工标注成本高昂且耗时——我们提出了VideoAutoArena,这是一种借鉴LMSYS Chatbot Arena框架的竞技场式基准,旨在自动评估LMMs的视频分析能力。VideoAutoArena利用用户模拟生成开放式的、自适应的问题,以严格评估模型在视频理解方面的表现。该基准包括一个自动化的评估框架,结合了修改后的ELO评分系统,以实现公平且持续的多LMMs之间的比较。为了验证我们的自动评判系统,我们构建了一个“黄金标准”,使用精心筛选的人工标注子集,证明我们的竞技场与人类判断高度一致,同时保持可扩展性。此外,我们提出了一种故障驱动的进化策略,逐步增加问题的复杂性,促使模型处理更具有挑战性的视频分析场景。实验结果表明,VideoAutoArena有效地区分了最先进的LMMs,提供了关于模型优势和改进领域的见解。为了进一步简化评估,我们提出了VideoAutoBench作为辅助基准,在VideoAutoArena的某些战斗中,人类注释员标记胜者。我们使用GPT-4o作为裁判,将模型的回答与这些人类验证的答案进行比较。结合VideoAutoArena和VideoAutoBench,提供了一种成本效益高且可扩展的框架,用于评估用户为中心的视频分析中的LMMs。
论文: https://arxiv.org/pdf/2411.13281
5. Stylecodes: Encoding Stylistic Information For Image Generation
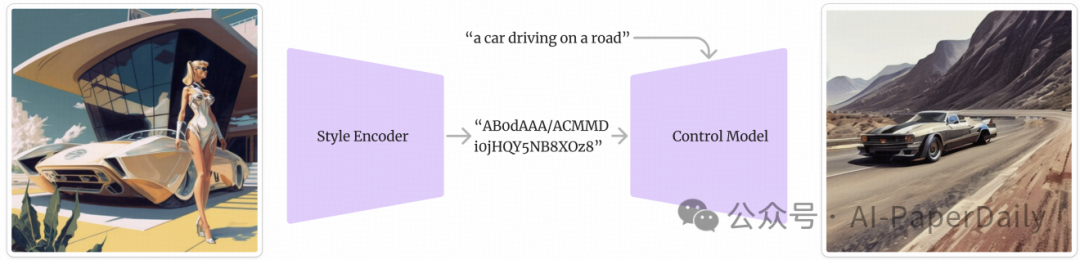
扩散模型在图像生成方面表现优异,但控制它们仍然是一项挑战。我们专注于风格条件下的图像生成问题。尽管示例图像有效,但使用起来不便:MidJourney的srefs(风格参考代码)通过用简短的数字代码表达特定的图像风格解决了这个问题。由于它们易于分享且允许使用图像进行风格控制,无需发布源图像,这些代码在社交媒体上得到了广泛采用。然而,用户无法从自己的图像生成srefs,而且底层训练过程也不公开。我们提出StyleCodes:一种开源且开放研究的风格编码架构,以20个字符的base64代码来表达图像风格。我们的实验表明,我们的编码与传统图像到风格的技术相比,质量损失很小。
论文: https://arxiv.org/pdf/2411.12811
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









