






一、FlashMLA
今天DeepSeek开源周第一天,开放了FlashMLA仓库,1小时内星标2.7k!

FlashMLA 是一个高效的 MLA 解码内核,专为 Hopper GPU 优化,适用于可变长度序列。该项目目前发布了 BF16 和具有 64 块大小分页 kvcache 的功能。在 H800 SXM5 上,使用 CUDA 12.6,内存受限配置下可达 3000 GB/s,计算受限配置下可达 580 TFLOPS。
Github仓库地址:https://github.com/deepseek-ai/FlashMLA
这里提到两个比较关键的功能就是BF16精度计算以及Paged kvcache缓存技术
好巧不巧,近期DeepSeek 发布了一篇新论文,提出了一种改进版的注意力机制 NSA,即Native Sparse Attention,可以直译为「原生稀疏注意力」;但其实就在同一天,月之暗面也发布了一篇主题类似的论文,提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。注意机制最近这么火爆的背景下,不妨我们趁机复习下Kv Cache相关概念以及相关注意力机制模型。
二、KV Cache简介
这部分主要参考LLM推理算法简述,可以快速回顾下KV Cache概念,关于更多LLM推理算法讲解大家可以阅读https://zhuanlan.zhihu.com/p/685794495。
LLM 推理服务的吞吐量指标主要受制于显存限制。研究团队发现现有系统由于缺乏精细的显存管理方法而浪费了 60% 至 80% 的显存,浪费的显存主要来自 KV Cache。因此,有效管理 KV Cache 是一个重大挑战。
什么是KV Cache?
Transformer 模型具有自回归推理的特点,即每次推理只会预测输出一个 token,当前轮输出 token 与历史输入 tokens 拼接,作为下一轮的输入 tokens,反复执行多次。该过程中,前后两轮的输入只相差一个 token,存在重复计算。KV Cache 技术实现了将可复用的键值向量结果保存下来,从而避免了重复计算。如下图所示,展示了有无 kv cache 的流程:

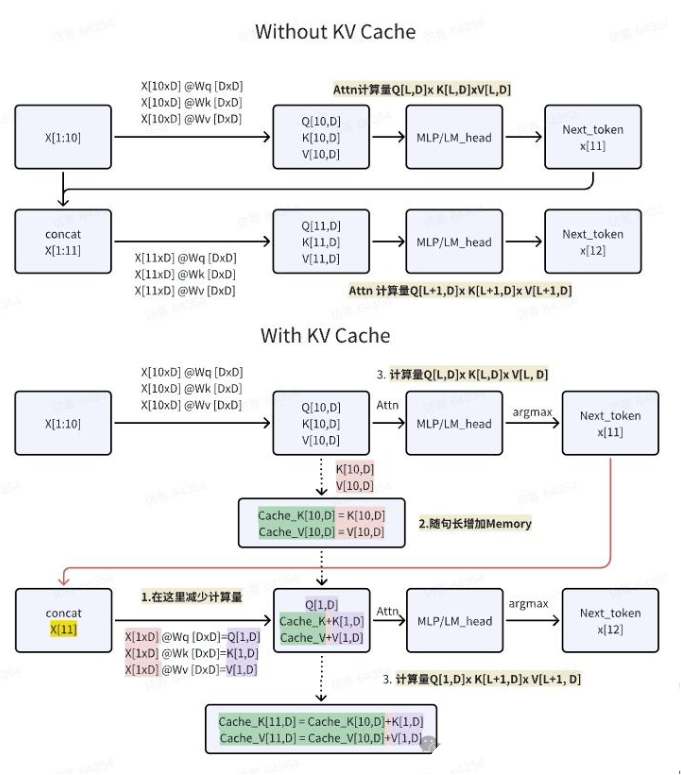
如何优化KV cahce?
KV cache的峰值显存占用大小计算公式:2 x Length x batch_size x [d x n_kv_heads] x Layers x k-bits,由此我们可以看出影响KV cache的具体因素:
-
k-bits: 数据类型,FP16 占2个bytes。(量化)
-
2: 代表 Key/Value 两个向量现
-
Length: 输入输出序列的长度(循环队列管理窗口KV,减少长度kv)
-
Layers:模型层数
-
d x n_kv_heads:kv维度(MQA/GQA通过减少KV的头数减少显存占用)
-
batch_size : KV Cache 与 batchsize 度呈线性关系,随着 batch size 的增大,KV cache 占用的显存开销快速增大,甚至会超过模型本身。
-
操作系统管理:现GPU的KV Cache的有效存储率较低低 (page-attention)

在bf16格式下的13B模型中,我们只有大约10G的空间来存储kv cache。
KV Cache 的引入也使得推理过程分为如下两个不同阶段,进而影响到后续的其他优化方法。
-
预填充阶段 (Prefill):发生在计算第一个输出 token 过程中,计算时需要为每个 Transformer layer 计算并保存 key cache 和 value cache;FLOPs 同 KV Cache 一致,存在大量 GEMM (GEneral Matrix-Matrix multiply) 操作,属于 Compute-bound 类型计算。
-
解码阶段 (Decoder):发生在计算第二个输出 token 至最后一个 token 过程中,这时 KV Cache 已存有历史键值结果,每轮推理只需读取 KV Cache,同时将当前轮计算出的新 Key、Value 追加写入至 Cache;GEMM 变为 GEMV (GEneral Matrix-Vector multiply) 操作,FLOPs 降低,推理速度相对预填充阶段变快,这时属于 Memory-bound 类型计算。
三、解码中的KV Cache
我们下面用一个例子更加详细的解释什么是KV Cache,了解一些背景的计算问题,以及KV Cache的概念。
无论是encoder-decoder结构,还是现在我们最接近AGI的decoder-only的LLM,解码生成时都是自回归auto-regressive的方式。也就是说,解码的时候,先根据当前输入,生成下一个token,然后把生成的token拼接在后面,获得新的输入,再用生成,依此选择,直到生成结果。
比如我们输入“窗前明月光下一句是”,那么模型每次生成一个token,输入输出会是这样(方便起见,默认每个token都是一个字符)
step0: 输入=[BOS]窗前明月光下一句是;输出=疑
step1: 输入=[BOS]窗前明月光下一句是疑;输出=是
step2: 输入=[BOS]窗前明月光下一句是疑是;输出=地
step3: 输入=[BOS]窗前明月光下一句是疑是地;输出=上
step4: 输入=[BOS]窗前明月光下一句是疑是地上;输出=霜
step5: 输入=[BOS]窗前明月光下一句是疑是地上霜;输出=[EOS]
(其中[BOS]和[EOS]分别是开始和结束的标记字符)
我们看一下在计算的过程中,如何输入的token “是” 的最后是hidden state如何传递到后面的类Token预测模型,以及后面每一个token,使用新的输入列中最后一个时刻的输出。
我们可以看到,在每一个step的计算中,主要包含了上一轮step的内容,而且只在最后一步使用(一个token)。那么每一个计算也就包含了上一轮step的计算内容。
从公式来看是这样的,回想一下我们attention的计算:
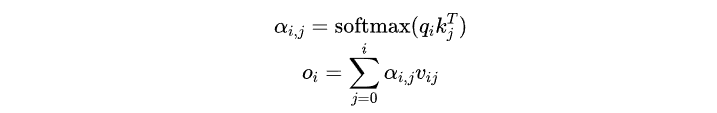
注意对于decoder的时候,由于mask attention的存在,每个输入只能看到自己和前面的内容,而看不到后面的内容。
假设我们当前输入的长度是3,预测第4个字,那么每层attention所做的计算有:
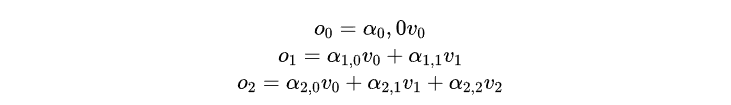
预测完第4个字,放到输入里,继续预测第5个字,每层attention所做的计算有:
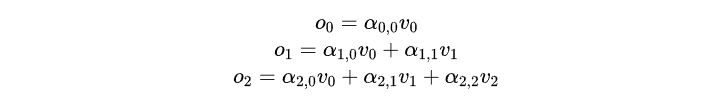
可以看到,在预测第5个字时,只有最后一步引入了新的计算,而到的计算部分是完全重复的。
但是模型在推理的时候可不管这些,无论你是否只是要最后一个字的输出,它都会把所有输入计算一遍,给出所有输出结果。
也就是说中间有很多我们不需要的计算,这样就造成了浪费。
而且随着生成的结果越来越多,输入的长度也越来越长,上面这个例子里,输入长度是step0的10个, 每步骤,直接step5到15个。如果输入的instruction是规范型任务,那么可能有800个step。这个情况下,step0就变得有800次,step1被重复了799次——这样浪费的计算资源显然不可忍受。
有没有什么方法可以重利用上一个step里已经计算过的结果,减少浪费呢?
答案就是KV Cache,利用一个缓存,把需要重复利用的时序计算结果保存下来,减少重复计算。
而和就是需要保存的对象。
想一想,下图就是缓存的过程,假设我们第一次输入的输入长度是3个,我们第一次预测输出预测第4个字,那么由于下图给你看的是每个输入步骤的缓存,每个时序步骤都需要存储一次,而我们依旧会有些重复计算的情况。则有:

kv_cache下标l表示模型层数。在进行第二次预测时,也就是预测第5个字的时候,在第l层的时候,由于前面我们缓存了每层的,值,那层就不需要算新的,而不再算,。因为第l层的,本来经过FFN层之后进到层,再经过新的投影变换,成为层的,值,但是是层的,值就已经保留了!
然后我们把本次新算出来的,值也存储起来。
然后我们再做下一次计算出的结果:
这样就节省了attention和FFN的很多重复计算。
transformers中,生成的时候传入use_cache=True就会开启KV Cache。
也可以简单看下GPT2中的实现,中文注释的部分就是使用缓存结果和更新缓存结果
Class GPT2Attention(nn.Module):
...
...
def forward(
self,
hidden_states: Optional[Tuple[torch.FloatTensor]],
layer_past: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = False,
output_attentions: Optional[bool] = False,
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
if encoder_hidden_states isnotNone:
ifnot hasattr(self, "q_attn"):
raise ValueError(
"If class is used as cross attention, the weights `q_attn` have to be defined. "
"Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`."
)
query = self.q_attn(hidden_states)
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
attention_mask = encoder_attention_mask
else:
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
# 过去所存的值
if layer_past isnotNone:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2) # 把当前新的key加入
value = torch.cat((past_value, value), dim=-2) # 把当前新的value加入
if use_cache isTrue:
present = (key, value) # 输出用于保存
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
attn_output = self.c_proj(attn_output)
attn_output = self.resid_dropout(attn_output)
outputs = (attn_output, present)
if output_attentions:
outputs += (attn_weights,)
return outputs # a, present, (attentions)
总的来说,KV Cache是以空间换时间的做法,通过使用快速的缓存存储,减少了重复计算。(注意,只能在decoder结构的模型可用,因为有mask attention的存在,使得前面的token可以不用关照后面的token)
但是,用了KV Cache之后也不是立刻万事大吉。
我们简单计算一下,对于输入长度为,层数为,hidden size为的模型,需要缓存的参数量为

这些参数的大小是batch size=1的情况,如果batch size增大,这个值是很容易就超过1G。
四、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









