







0,原文链接:
http://blog.sina.com.cn/s/blog_859fc6960101agew.html
https://wenku.baidu.com/view/3fe9a7a4dd3383c4bb4cd293.html (值得收藏)
1,CAN报文是Intel格式还是Motorola格式,只在单个信号跨字节时解析才有区别
当一个信号的数据长度不超过 1 个字节(8 位)时,Intel 与 Motorola 两种格式的编码结果没有什么不同,完全一样。当信号的数据长度超过 1 个字节(8 位)时,两者的编码结果出现了明显的不同
(1) 信号的高位,即最能表达信号特性的因子,比如:车速信号 500km/h 按照给定的公 式,转换成十六进制数为 0x6A5,因为 6 代表的数量级最大(16^²),那么其中 6 就 是其信号的高位。
(2)信号的低位,即最不能表达信号特性的因子,比如:车速信号 500km/h 按照给定的公式,转换成十六进制数为 0x6A5,因为 5 代表的数量级最小(16^º),那么其中 5 就是其信号的低位。
(3)信号的起始位,一般来讲,主机厂在定义整车 CAN 总线通信矩阵时,其每一个信号都从其最低位开始填写,这样也符合使用习惯。所以信号的起始位就是信号的最低位。这也与 CANoe 中 CANdb++的定义 Startbit 含义一致。
- Intel 格式
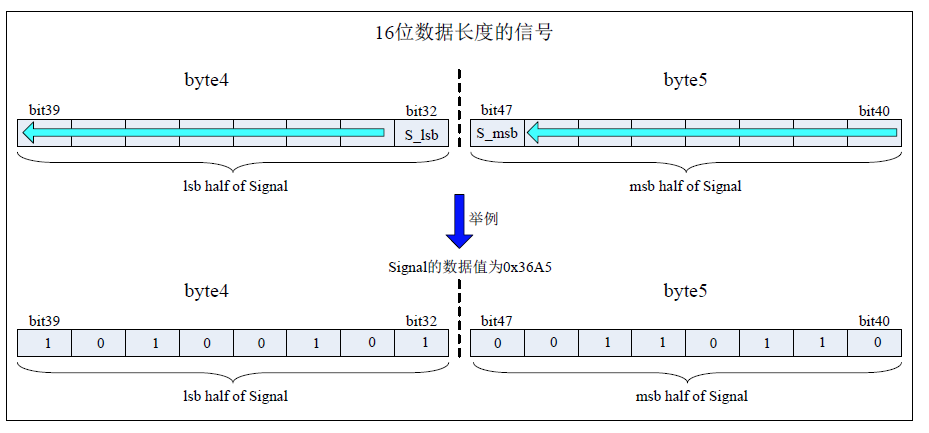
当一个信号的数据长度超过1 个字节(8 位)或者数据长度不超过一个字节但是采用跨字节方式实现时,该信号的高位(S_msb)将被放在高字节(MSB)的高位,信号的低位(S_lsb)将被放在低字节(LSB)的低位。这样,信号的起始位就是低字节的低位。
CAN ⇆ ETH:{
数据输入开始解包时,低字节放字节低位,高字节放字节高位;
数据输出重新组包时,先取低字节再取高字节。
}
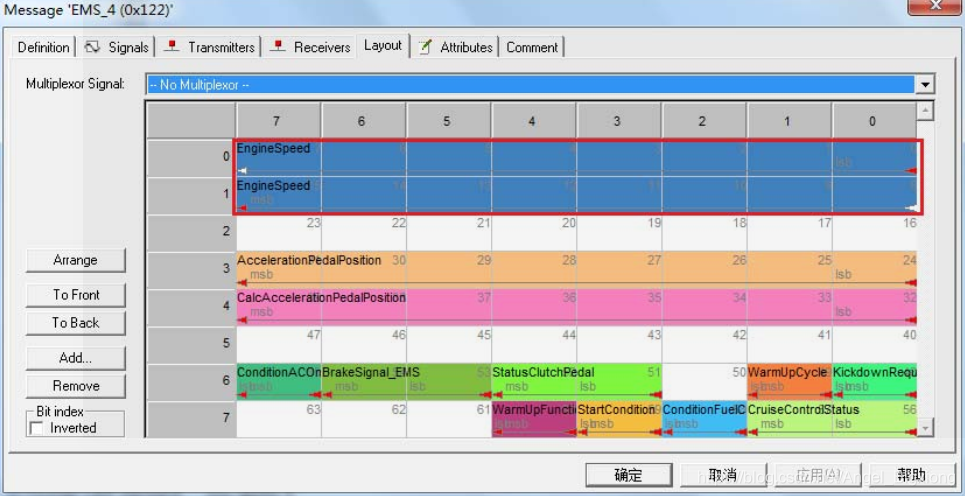
下图,每一行是一个字节,从0行(低字节)→7行(高字节)。↓
- Motorola 格式
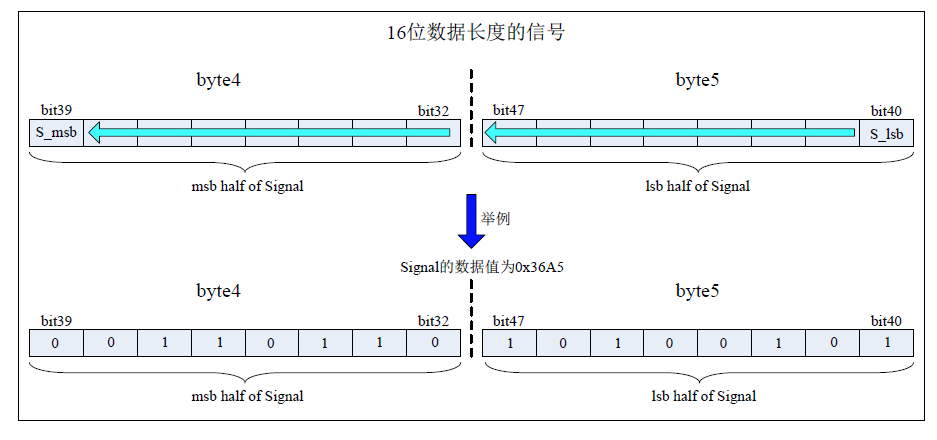
当一个信号的数据长度超过 1 个字节(8 位)或者数据长度不超过一个字节但是采用跨字节方式实现时,该信号的高位(S_msb)将被放在低字节(MSB)的高位,信号的低位(S_lsb)将被放在高字节(LSB)的低位。这样,信号的起始位就是高字节的低位。
CAN ⇆ ETH:{
数据输入开始解包时,低字节放字节低位,高字节放字节高位;//CAN → ETH
数据输出重新组包时,先取高字节再取低字节。//ETH → CAN
}
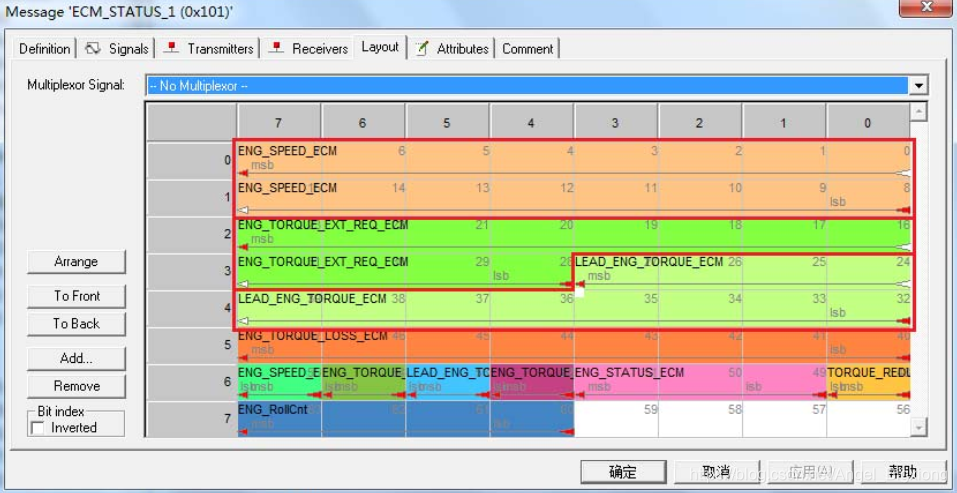
下图,每一行是一个字节,从0行(低字节)→7行(高字节)。↓
非常感谢大佬的图。
总结:
(1)当一个信号的数据长度不超过 1 个字节(8 位)时,Intel 与 Motorola 两种格式的编码结果没有什么不同,完全一样。
单字节时,程序中结构体的定义都是从字节的低位到字节的高位。
(2)当一个信号的数据长度超过1 个字节(8 位)或者数据长度不超过一个字节但是采用跨字节方式实现时,两者的编码结果出现了明显的不同:
跨字节时,Intel格式,程序中结构体的定义都是从低字节到高字节;
跨字节时,Motorola格式,程序中结构体的定义都是从高字节到低字节。
以上,定义均是从信号的低位→信号的高位,即S_lsb → S_msb!!
Intel是信号的高位在高字节的高位,信号的低位在低字节的低位;
Motorola是信号的高位在低字节的高位,信号的低位在高字节的低位;
其中:
信号的高位:(S_msb);
信号的低位(S_lsb);
字节的高位:(MSB);
字节的低位(LSB);

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









