







 本文介绍了如何利用Tushare接口获取A股股票的前复权数据,并通过Python进行处理,包括获取股票列表、历史与每日数据的合并、计算MACD等技术指标。此外,还提供了注意事项,如数据权限限制、文件夹结构和代码执行频率。最终生成的数据与同花顺一致,适合股票分析。
本文介绍了如何利用Tushare接口获取A股股票的前复权数据,并通过Python进行处理,包括获取股票列表、历史与每日数据的合并、计算MACD等技术指标。此外,还提供了注意事项,如数据权限限制、文件夹结构和代码执行频率。最终生成的数据与同花顺一致,适合股票分析。
【说明】
该方法需要开通Tushare的数据获取权限或个人积分大于2000分
【流程】
1.获取最新的A股已上市股票列表
【注1】该段代码正常只需执行1次,后续有新增的需要观测的股票,只需在生成的股票列表内新增对应的股票代码和股票名称等信息即可。
需要建一个Basic_Info的文件夹,并将该py代码文件与Basic_Info同级,当然亦可修改f_s路径
[代码1]
import tushare as ts
token='你的token' #在个人主页-接口TOKEN中
pro=ts.pro_api(token)
f_s='./Basic_Info/STK_List.csv'
df= pro.stock_basic(exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date')
df.to_csv(f_s,index=False,encoding='GBK')
[运行结果]
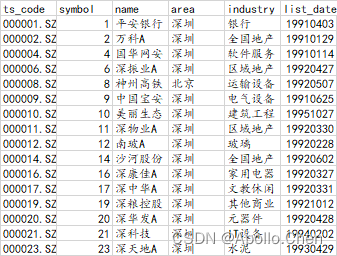
【注2】:可以手动剔除部分你不需要股票,如行业/板块等,如只看A股,则只留下SZ和SH的即可
2.根据股票列表获取前复权行情
此处需要注意的地方是由于2000积分档位的权限,单次仅能读取5000行的数据,一次对于发行较早的股票,则需要对其进行截断读取再合并后输出。注意需要在同级别处建立一个名为His_QFQ的文件夹
[代码2]
import time
import pandas as pd
import tushare as ts
token='你的token' #在个人主页-接口TOKEN中
pro=ts.pro_api(token)
f_0='./Basic_Info/STK_List.csv'
def read_data(data, skip_row, level, sht_name=0):
if data[-4:] == '.csv':
try:
d_u = pd.read_csv(data, header=0, chunksize=10000, encoding='gbk') # encoding='gbk',
except UnicodeDecodeError:
d_u = pd.read_csv(data, header=0, chunksize=10000, encoding='utf-8')
chunk_0 = [i for i in d_u]
df = pd.concat(chunk_0)
else:
if level == 0 or level == 1:
header = skip_row
else:
header = [skip_row + i for i in range(level)]
df = pd.read_excel(data, sheet_name=sht_name, header=header)
return df
df=read_data(f_0,0,0)
ts_code=list(df['ts_code'])
name=list(df['name'])
list_date=list(df['list_date'])
#以下两个日期的设置,如再过5-10年需要重新设置sep_date
date_1='20221101' #你想要获取的最新的日期
sep_date=20011009
for i in range(len(name)):
f_name=ts_code[i][: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









