







1.三类广义上的机器学习算法
· 监督学习。工作原理:该算法由一个目标/结果变量(或因变量)组成,该变量将从一组给定的预测变量(自变量)进行预测。使用这组变量,我们生成了一个将输入数据映射到所需输出的函数。训练过程将继续进行,直到模型在训练数据上达到所需的准确性水平。监督学习的例子:回归、决策树、随机森林、KNN、逻辑回归等。
·无监督学习。工作原理:在这个算法中,我们没有任何目标或结果变量来预测/估计(这称为未标记数据)。它用于推荐系统或对不同组中的种群进行聚类。聚类算法广泛用于将客户细分为不同的组以进行特定的干预。无监督学习的例子有:Apriori算法,K-means聚类。
·强化学习。工作原理:使用此算法,可以训练智能体做出特定的决策。智能体暴露在一个环境中,它通过反复试验不断地训练自己。智能体从过去的经验中学习,并试图获取最好的知识来做出准确的业务决策。加强学习示例:马尔可夫决策过程。
2.常用的机器学习算法
以下是常用的机器学习算法,这些算法几乎可以应用于任何数据问题:
-
线性回归
-
逻辑回归
-
决策树
-
支持向量机
-
朴素贝叶斯
-
kNN
-
K-均值
-
随机森林
-
降维算法
-
梯度提升算法
-
GBM
-
XGBoost
-
LightGBM
-
CatBoost
-
3.十大机器学习算法
1.线性回归
线性回归指的是根据连续变量估计实际值(房屋成本、通话次数、总销售额等)。在这里,我们通过拟合最佳拟合线来建立自变量和因变量之间的关系。这条最佳拟合线称为回归线,由线性方程 Y= a*X + b 表示。
示例1:理解线性回归的最好方法是重温童年的这种经历。假设你让一个五年级的孩子通过增加体重顺序来安排他班上的人而不问他们的体重。你认为孩子会怎么做?他可能会观察(视觉分析)人的身高和体型,并使用这些可见参数的组合来安排他们。这是现实生活中的线性回归。孩子实际上已经弄清楚身高和身材会通过关系与体重相关,这看起来像上面的等式。
在此等式中:
-
Y – 因变量
-
a – 斜率
-
X – 自变量
-
b – 偏置(截距)
这些系数 a 和 b 是基于最小化数据点与回归线之间距离的平方差之和得出的。
示例2:下面我们确定了线性方程 y=0.2811x+13.9 的最佳拟合线。现在使用这个等式,我们知道一个人的身高就可以找到对应的体重。
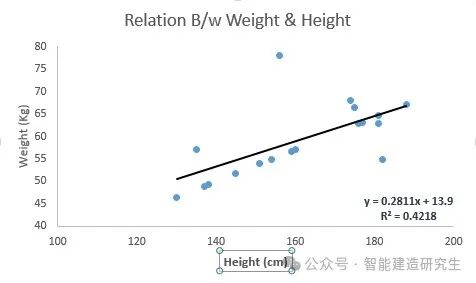
线性回归主要有两种类型:简单线性回归和多元线性回归。简单线性回归的特征是一个自变量。多元线性回归(顾名思义)的特征是多个(超过 1 个)自变量。在寻找最佳拟合线时,可以拟合多项式或曲线回归,这些被称为多项式或曲线回归。
from sklearn import linear_model # 从scikit-learn库中导入 linear_model 模块,该模块包含了线性回归等线性模型。
import numpy as np # 用于数值计算
x_train=np.random.rand(4,4) # 生成 4x4 的随机数组,这里的x_train和y_train是训练数据的输入和输出(或称为特征和目标)
print("训练集的输入:", x_train)
y_train=np.random.rand(4,4)
print("训练集的输出:",y_train)
# x_test 也是随机生成的 4x4 数组,用于测试模型
x_test=np.random.rand(4,4)
print("测试集的输入:",x_test)
# 创建一个线性回归对象
linear = linear_model.LinearRegression()
# 使用 linear.fit(x_train, y_train) 来训练模型,这实际上是计算线性回归的系数(也称为权重)和截距,以最小化预测值与实际值之间的平方误差
linear.fit(x_train, y_train)
linear.score(x_train, y_train) # 用于计算模型在训练数据上的决定系数(R^2 值), 这个值越接近 1,说明模型在训练数据上的拟合效果越好。
print('Coefficient模型权重: \n', linear.coef_) # 返回模型的系数(或称为权重),对于多元线性回归(多个输入特征),这是一个数组,每个元素对应一个特征的系数
print('Intercept模型的偏置: \n', linear.intercept_) # 返回模型的截距
predicted= linear.predict(x_test) # 使用 linear.predict(x_test) 对测试数据 x_test 进行预测,并返回预测值
print('predicted模型的预测值:\n',predicted)
# 输出结果:
'''
训练集的输入: [[0.20754042 0.25384413 0.22825499 0.57619701]
[0.57559759 0.29673635 0.4255568 0.4777517 ]
[0.10862619 0.90036591 0.45464787 0.172535 ]
[0.68197982 0.54844108 0.57867612 0.6864402 ]]
训练集的输出: [[0.95610395 0.16729992 0.17283568 0.42404863]
[0.02875033 0.25366368 0.19983908 0.39018791]
[0.43278431 0.38999408 0.02494574 0.06259235]
[0.1805258 0.58757488 0.60743324 0.24927747]]
测试集的输入: [[0.4405055 0.21761395 0.31916676 0.06118665]
[0.99743372 0.03209244 0.04725867 0.0013879 ]
[0.55770033 0.77004149 0.69764437 0.43791772]
[0.31754778 0.572482 0.72450059 0.87935267]]
Coefficient模型权重:
[[-1.69223839 0.29025176 -0.72312235 1.7704178 ]
[ 0.14544513 0.60746457 0.31486026 0.56220411]
[ 0.19368336 0.42893018 0.25579368 1.14936371]
[ 0.05912962 -0.48518575 -0.17305051 0.00680509]]
Intercept模型的偏置:
[ 0.37857994 -0.41289589 -0.69688898 0.57051697]
predicted模型的预测值:
[[-0.42616822 -0.08174143 -0.36626264 0.43616512]
[-1.33171744 -0.23266884 -0.47625358 0.60575536]
[-0.07086098 0.60185145 0.42320209 0.11213277]
[ 1.04029636 0.70354454 0.80618827 0.19214222]]
'''
2.逻辑回归
不要被它的名字误导!实际上,逻辑回归(Logistic Regression)是一种分类算法,而非回归算法。它用于根据一组给定的自变量来估计离散值(通常是二进制值,如0/1、是/否、真/假)。简而言之,逻辑回归通过将数据拟合到逻辑函数(也称为sigmoid函数)来预测事件发生的概率。因此,它有时也被称为 logit 回归。由于它预测的是概率,所以其输出值介于0和1之间,正如我们所预期的。
为了更直观地理解逻辑回归,让我们通过一个简单的例子来探讨。
假设你的朋友给你出了一个谜题来解。结果只有两种可能——要么你解开了,要么你没有解开。现在想象一下,你被提供了一系列不同主题的谜题或测验,目的是了解你擅长哪些科目。这项研究的结果可能是这样的——如果你被问到一个基于三角函数的问题,你有70%的可能性解开它。而如果你面对的是五年级的历史问题,那么你答对的概率可能只有30%。这正是逻辑回归能够为你提供的。
在数学上,逻辑回归是通过将预测变量的线性组合转化为结果的对数几率(也就是事件发生与不发生的概率之比的自然对数)来实现分类功能的。这样,我们就可以根据给定的自变量来预测某一事件发生的概率了。
odds= p / (1-p) = probability of event occurrence / probability of not event occurrence
ln(odds) = ln(p/(1-p))
logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk
上面 p 是存在目标特征的概率,它选择的参数是使观察样本值的最大化,而不是最小化平方误差之和的参数(如在普通回归中)。
以下是一个简单的逻辑回归的例子:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 创建虚拟数据
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
y = np.array([0, 0, 1, 1, 1]) # 0表示负样本,1表示正样本
# 将数据拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建逻辑回归模型对象
model = LogisticRegression()
# 使用训练数据拟合模型
model.fit(X_train, y_train)
# 输出模型系数和截距
print('Coefficient of model :', model.coef_)
print('Intercept of model', model.intercept_)
# 在训练集上进行预测
predict_train = model.predict(X_train)
print('Target on train data', predict_train)
# 计算训练集的准确率
accuracy_train = accuracy_score(y_train, predict_train)
print('accuracy_score on train dataset : ', accuracy_train)
# 在测试集上进行预测
predict_test = model.predict(X_test)
print('Target on test data', predict_test)
# 计算测试集的准确率
accuracy_test = accuracy_score(y_test, predict_test)
print('accuracy_score on test dataset : ', accuracy_test)
# 绘制训练集和测试集的散点图
plt.figure(figsize=(10, 5))
# 绘制训练集
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='coolwarm', label='Train Set')
# 绘制测试集
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap='coolwarm', marker='x', label='Test Set')
# 绘制决策边界
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.1), np.arange(x2_min, x2_max, 0.1))
Z = model.predict(np.c_[xx1.ravel(), xx2.ravel()])
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap='coolwarm')
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Logistic Regression Decision Boundary')
plt.legend()
plt.show()
# 输出结果:
'''
Coefficient of model : [[0.62622224 0.62622516]]
Intercept of model [-2.90191064]
Target on train data [1 1 0 1]
accuracy_score on train dataset : 1.0
Target on test data [1]
accuracy_score on test dataset : 0.0
'''
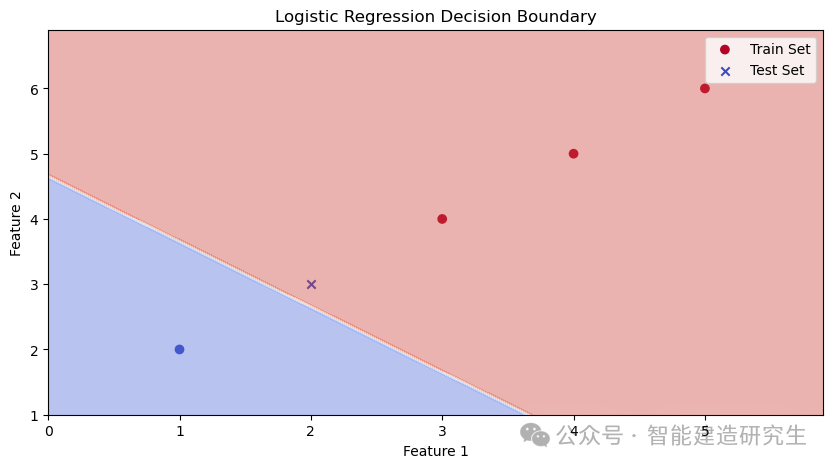
逻辑回归模型通过对输入特征进行线性加权求和,然后将结果通过一个sigmoid函数进行转换,得到样本属于正类的概率。当概率超过阈值时,模型将样本归为正类;否则,归为负类。
决策边界就是在特征空间中,将模型预测为正类和负类的样本分开的线或者超平面。对于二维特征空间,决策边界就是一条直线;对于多维特征空间,决策边界是一个超平面。参见原文:2024 年将使用的 10 大机器学习算法 (analyticsvidhya.com)
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









