







前言
如果只需要代码可以跳转到最后一步(记着更换商品ID和评论页的的页数)
话不多说,直接开干!

文章所提供的代码不能用于商业用途 仅建议学习交流使用 否则后果自负
部分代码来源于网络 如有侵权私我立删 谢谢
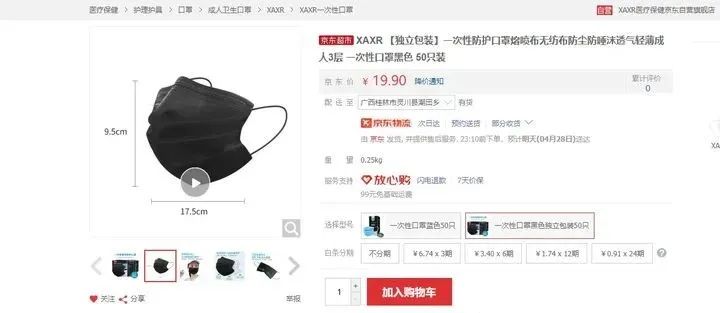
今天要干的活
京东某口罩产品的全部评价,要爬取的数据
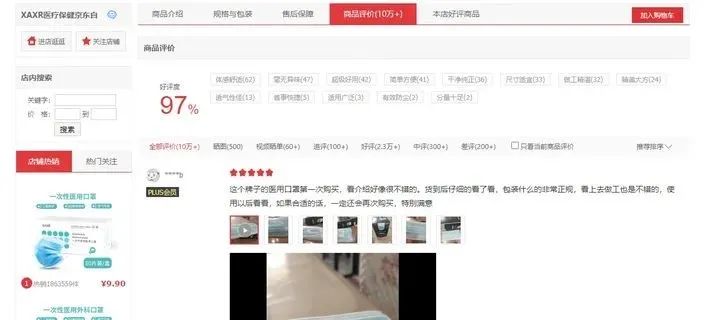
最终结果
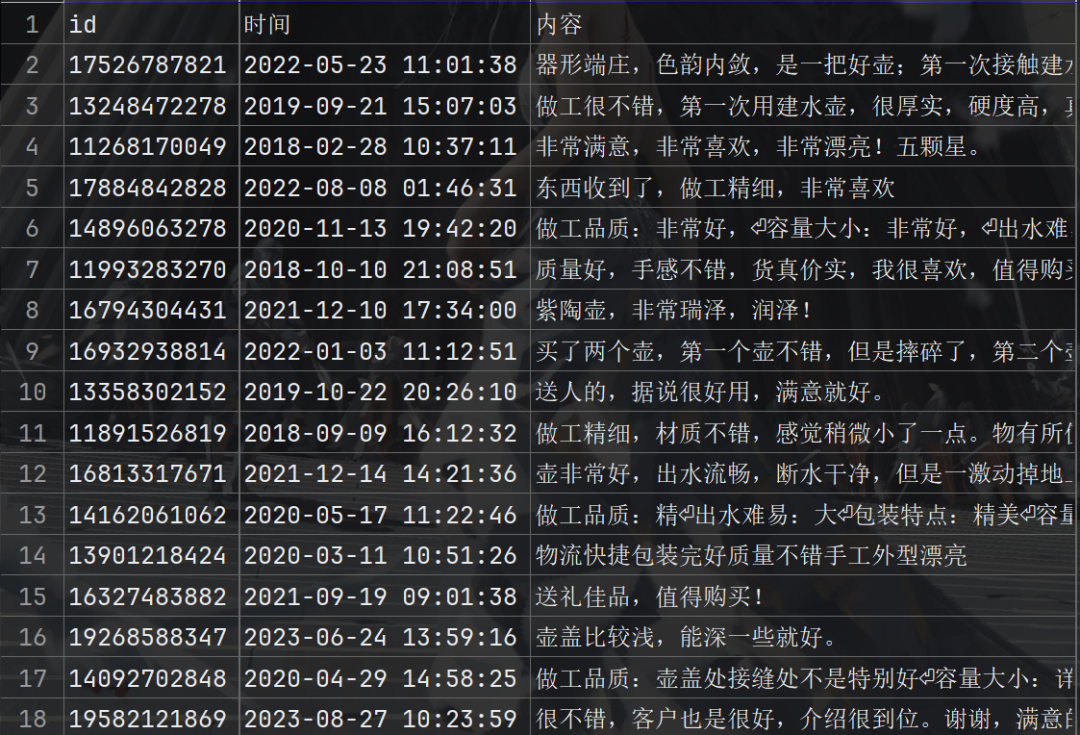
遇到问题(重点!!)
今天使用的方法就是用requests请求获取页面数据 返回并且分析其结果。
今天的重点在于京东商品全部评价的问题。我们今天要爬取的这个商品评论显示的数据为10w+的 但是我们会发现 一个页面只有10条 就算显示全部页面也只有100页 那么就是1000多条 那么!剩下的数据 去了哪里呢??你品 你细品??
我在网上查阅了很多资料 发现很多博主都是直接爬取100页 这样将会导致数据的不完整。最终我在csdn网站上一位博主的文章下面发现了此问题的解决方法(真的很强)
链接:https://blog.csdn.net/hgjiayou/article/details/109777572.
我总结下此文章的内容!
假如一个商品全部评论数据为20w+ 默认好评15w+ 这15w+的默认好评就会不显示出来。那么我们可以爬取的数据就只剩下5w+ 接下来 我们就分别爬取全部好评 好评 中评 差评 追加评价 但是就算这些数据加起来 也仍然不足5w+ 上文的博主猜测可能有两点原因:
1.出现了数据造假,这个数字可能是刷出来的(机器或者水军)
2.真的有这么多的评论,但这时候系统可能只显示其中比较新的评论,而对比较旧的评论进行了存档。
在博主理论的基础上我也进行了很多相应的测试,就是说无论如何 我们最终都爬不到剩下的5w条数据 只能爬取一部分但这一部分数据也将
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











