







目录
准备
这次要爬取的是京东一款养生茶的评论,并制作词云图。我是为了做项目临时学习的(包括pyhton语言),学习程度不深,文章内容比较基础,其中也有一些不成熟的东西,欢迎指正。本篇文章为我的学习笔记。需要源码的可以直接跳转到文章末尾,改个商品ID、添加一个停词表就可以直接套用了。
关于爬虫的原理,可以看这篇(不看其实也不影响写这个项目,因为用到的不多):python爬虫入门(一) - requests库与re库,一个简单的爬虫程序-CSDN博客
需要用到的库有:
import json
import requests
import pandas as pd
import time
import random
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt可以提前准备。
获取数据
url
由于京东的反爬机制,抓包得到的url访问不了,我研究了老半天没搞懂怎么解决,就跟着大家一起用这个url了
url用下面这个:
url=f"https://club.jd.com/comment/productPageComments.action?" \
f"callback=fetchJSON_comment98&productId={product_id}" \
f"&pageSize=10&score=0&sortType=5&isShadowSku=0&fold=1&page={page}"其中,productId为要爬取评论的商品的ID;page为评论的页码,通过page的变换可以实现翻页;pageSize=10表示每页显示10条评论;score是评分过滤条件,score=0表示所有评分评论,score=1表示一星评论。可以按照自己的需求作其他设置。
productID从商品详情页的网址获取:
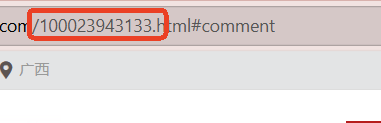
获取数据
product_id=100109439187
page=1
url = f"https://club.jd.com/comment/productPageComments.action?" \
f"callback=fetchJSON_comment98&productId={product_id}" \
f"&pageSize=10&score=0&sortType=5&isShadowSku=0&fold=1&page={page}"
#发起响应,获取JSON数据。
respone=requests.get(url)
#打印响应的text文本
print(respone.text)打印响应的结果,可以发现我们需要的内容前面多了一行:
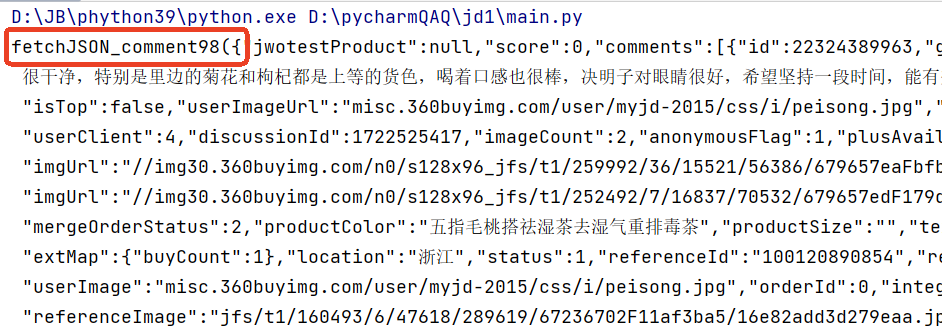
其实京东返回的JSON数据格式可以理解为:fetchJSON_co
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









