







 BranchyNet是一种新型的深度学习架构,它允许样本在预测置信度足够高时提前退出网络,从而减少推理时间并提高效率。通过在神经网络中添加早退分支,并联合优化所有分支,BranchyNet能够在保持或提高分类准确性的同时,显著加快平均推理速度。关键在于找到合适的退出阈值T,以平衡准确率和速度。实验表明,BranchyNet的分支结构和超参数选择对其性能有显著影响,并且可以与模型压缩技术结合使用。
BranchyNet是一种新型的深度学习架构,它允许样本在预测置信度足够高时提前退出网络,从而减少推理时间并提高效率。通过在神经网络中添加早退分支,并联合优化所有分支,BranchyNet能够在保持或提高分类准确性的同时,显著加快平均推理速度。关键在于找到合适的退出阈值T,以平衡准确率和速度。实验表明,BranchyNet的分支结构和超参数选择对其性能有显著影响,并且可以与模型压缩技术结合使用。
系列文章目录
文章目录
【阅读笔记】【DNN早退】BranchyNet: Fast Inference Via Early Exiting From Deep Neural Networks
ICPR 2016 哈佛
阅读笔记,非全文翻译
摘要
- 提出了BranchyNet,允许一些样本在已经拥有高预测置信度时提前退出网络
- 观察到,神经网络前面几层学习到的特征就已经足以用于分类
- 可以提升准确率和减少推理时间
1 引言
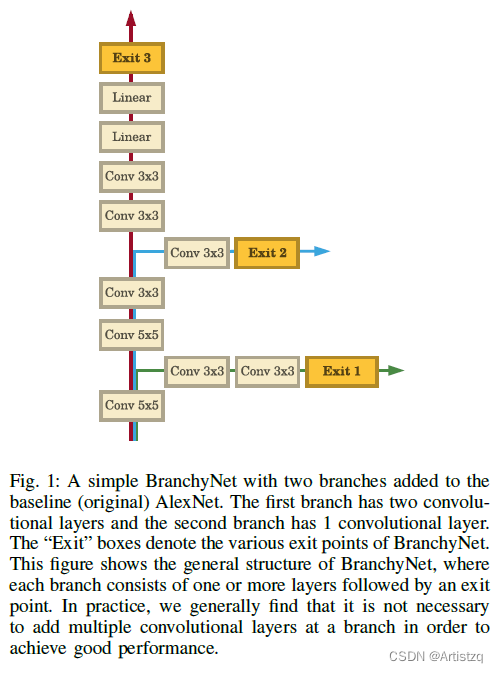
- 实验中发现,如果是为了提高性能,一个分支上没必要叠加很多卷积层
- Contributions:
- 早退分支可以快速推理
- 分支在联合优化中作为正则项
- 减缓梯度消失现象
2 背景和相关工作
- 剪枝没法用GPU加速
- 剪枝、低秩近似等压缩方法可以和本文的BranchyNet结合起来
- Panda等人提出了CDL,在每个卷
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2755
2755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









