







BranchyNet_chainer
基于提前退出部分样本原理而实现的带分支网络(supported by chainer)1
文章目录
一、摘要
深度神经网络是具有一定复杂程度的神经网络,可以定义为具有输入层、输出层和至少一个隐藏层之间的网络。每个层在一个过程中执行特定类型的分类和排序,这些复杂的神经网络的一个关键用途是处理未标记或未结构化的数据。一般来说,随着网络深度的增大,网络的性能也将会提升。但是,网络模型在数据集训练以及测试的时间也将变得越来越长,并且对机器资源的消耗需求也会增大。因此,我们提出了一种新的深度网络架构,通过在主网络中添加一个或多个分支网络,对退出点的样本置信度进行判断,从而可以提前退出部分样本,减少后继网络层的样本量。
本文我们使用几个比较常见的网络(LeNet, AlexNet, ResNet)和数据集(MNIST, CIFAR10)来研究该分支网络架构。首先我们在主网络上添加一个或多个分支网络,在数据集上进行训练,获取网络模型的总体准确率和损失函数值。然后在已经训练好的网络模型上进行测试,通过比较分析普通网络与添加分支后的网络测试效果,从而显示出该网络架构可以提高网络的准确性并且显著减少网络的推理时间。
二、实现过程
我们所建立的网络架构主要通过求解关联着退出点的损失函数加权和的联合优化问题进行训练,一旦训练好网络,则可以利用退出点让部分符合要求的样本提前退出,从而降低推理成本。在每个退出点,我们会利用分类结果的信息熵作为对预测的置信度度量,并设定每一个退出点的退出阈值。如果当前测试样本的熵低于退出阈值,即分类器 对预测结果有信心,则该样本在这个退出点待着预测结果退出网络,不会被下一层的网络处理。如果当前测试样本的上不低于退出阈值,则认为分类器对此样本的预测结果不可信,样本继续到网络的下一个退出点进行处理。如果样本已经到达最后一个退出点,也就是网络的最后一层,则将其直接退出。
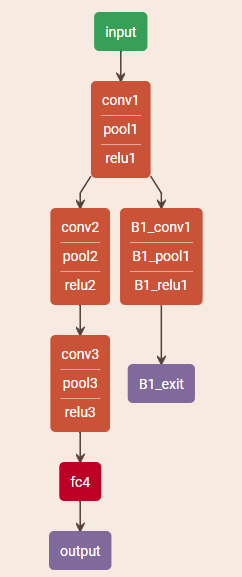
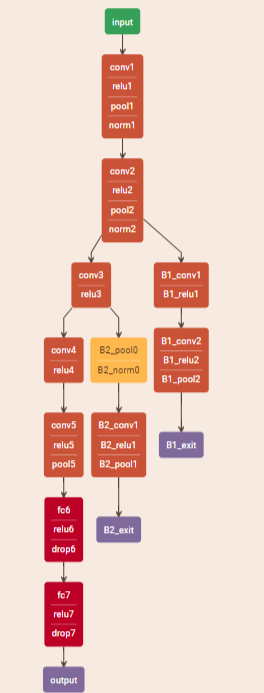
三、损失函数设定
交叉熵(cross entropy)是香农信息论中的一个重要概念,主要用于度量两个概率分布间的差异性信息,也就是交叉熵的值越小,两个概率分布越接近。在分支网络训练过程中,我们先通过 softmax 函数对网络层的输出值进行归一化处理,再对其归一化处理后的值进行计算得到交叉熵值,作为神经网络的损失函数。
我们将 x x x定义为一个输入样本, y y y定义为该输入样本的真实标签, y ^ \hat{y} y^定义为该输入样本的预测输出, S S S定义为所有可能的样本标签集合, θ \theta θ定义为一个分支网络层从入口点到退出点的参数集合, f e x i t n f_{exit_n} fexitn定义为网络层第n个退出点的输出,我们将损失函数 loss 用公式进行如下表达:
L ( y ^ , y ; θ ) = c r o s s _ e n t r o p y ( y ^ , y ) = − 1 ∣ S ∣ ∑ s ϵ S y s l o g y s ^ L(\hat{y},y;\theta)=cross\_entropy(\hat{y},y)=-\frac{1}{\left|S\right|}\sum_{s \epsilon S}y_slog\hat{y_s} L(y^,y;θ)=cross_en
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6
6

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









