







一、什么是One-Hot
One-Hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。将类别变量转换为机器学习算法易于利用的一种形式的过程,这个向量的表示为一项属性的特征向量,也就是同一时间只有一个激活点(不为0),这个向量只有一个特征是不为0的,其他都是0,特别稀疏。几乎是最早的用于提取文本特征的方法。
二、One-Hot的优缺点
优点:
1.解决了分类器不好处理离散数据的问题
2.在一定程度上起到了扩充特征的目的。比如性别本身是一个特征,经过one hot编码以后,就变成了男或女两个特征,将离散特征通过one-hot编码映射到欧式空间,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算都是非常重要的。
3.将离散型特征使用one-hot编码,可以会让特征之间的距离计算更加合理。
缺点:
1.没有考虑到词与词之间的顺序
2.词汇鸿沟。即默认假设词与词之间是没有关系的,而这显然是不显示的。
3.维度灾难。对于特征的特征值数目特别多,特征向量就会非常大,且非常稀疏。即每个词都是一堆一堆一堆0中唯一的那个1。
三、什么情况下适合用One-Hot
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
四、One-Hot在提取文本特征上的应用
说了这么多还是十分抽象,不太能理解其中的过程。下面通过两个例子来详细说明。
1.假设语料库中有这样两句话:
我们需要通过One-Hot对其编码:
首先分词并编号:
(实际上’也’其实算是停用词可以去掉,但此处是否去掉影响不大)
然后用One-Hot对每段话提取特征向量:
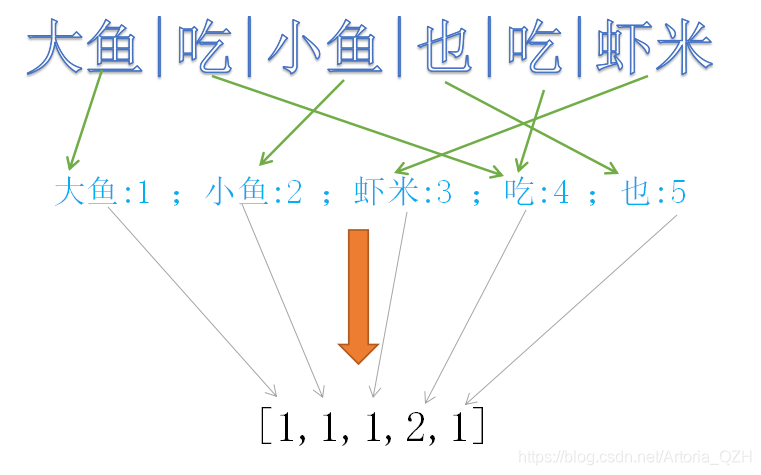

这样,语料库中“大鱼吃小鱼也吃虾米,小鱼吃虾米”这一段话,就转移成了特征向量:
五、通过sklearn实现One-Hot
接下来通过sklearn来实现这个过程:
from sklearn.feature_extraction.text import CountVectorizer
countvec = CountVectorizer(token_pattern='(?u)\\b\\w+\\b')
x = countvec.fit_transform(['大鱼 吃 小鱼 也 吃 虾米','小鱼 吃 虾米'])
x.todense()
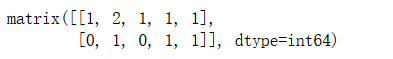
需要注意的是,默认token_pattern='(?u)\\b\\w\\w+\\b',即默认取两个字符以上,所以即使stop_words=None还是会去掉也和吃这两个向量。想要不去掉,token_pattern少一个\\w就行。
countvec.vocabulary_
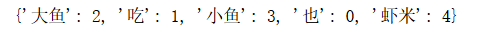
对比可以看到,和我们自己用One-Hot编码的结果是一致的。
参考
[1] https://blog.csdn.net/AZRRR/article/details/90293578
[2] https://blog.csdn.net/qq_32793161/article/details/93408802
[3] https://blog.csdn.net/mawenqi0729/article/details/80698780















 1919
1919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









