







Life Long Learning LLL
能否每次都训练同一个神经网络, 而不是每个task 一个 神经网络
文章目录
 还有别的叫法
还有别的叫法
Continuous Learning, Never Ending Learning, Incremental Learning
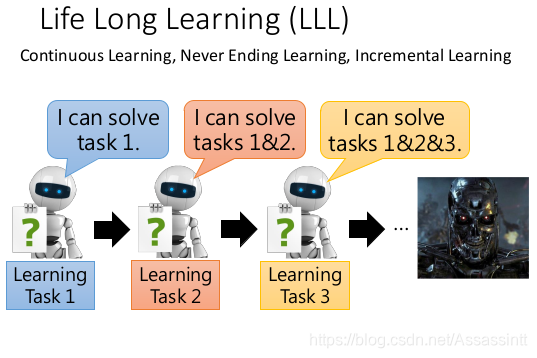
终身学习需要解决3个问题
1. 避免知识遗忘, 但不是妥协 Knowledge Retention
图像识别的例子
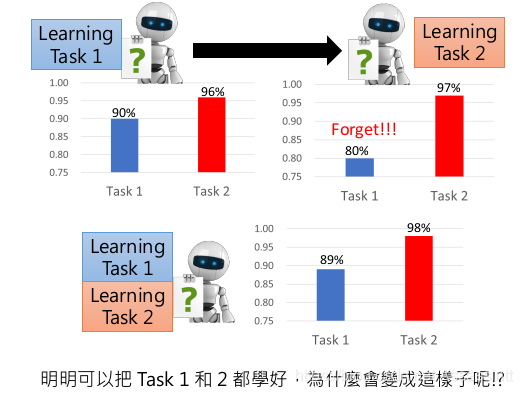
手写数字识别, task1 有噪点. task 没有.
 |  |
|---|---|
| 先训练task1, 再用task1 的结果训练task2,类似迁移学习. 最终模型task2的正确率变高了, 但是用模型再去检测, task1, 训练结果变差了. | 如果task1和task2的数据放在一起训练, 训练的结果是task1 和task2 的正确率都很高. 不会存在遗忘的问题. |
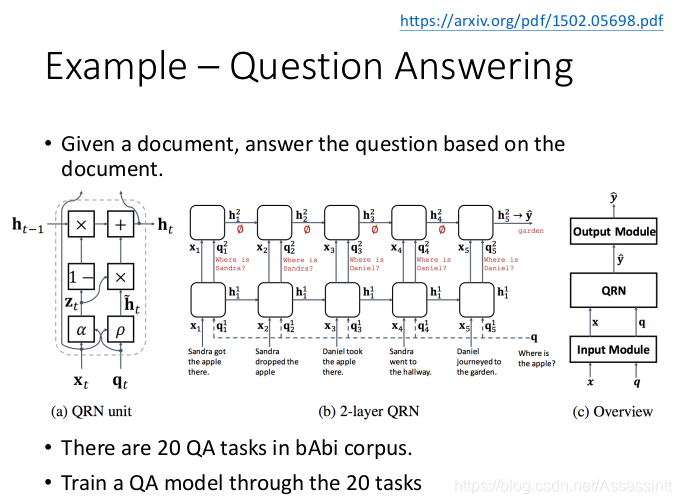
答题例子
输入一个文本, 训练出一个模型, 能回答不同的问题.
最常用的是babi的 corpus, 提供20种题型.
现在从第5个任务, 依次学习到第20个任务, 每次回去检测第5个题型的正确率. 正确率变差.
 | 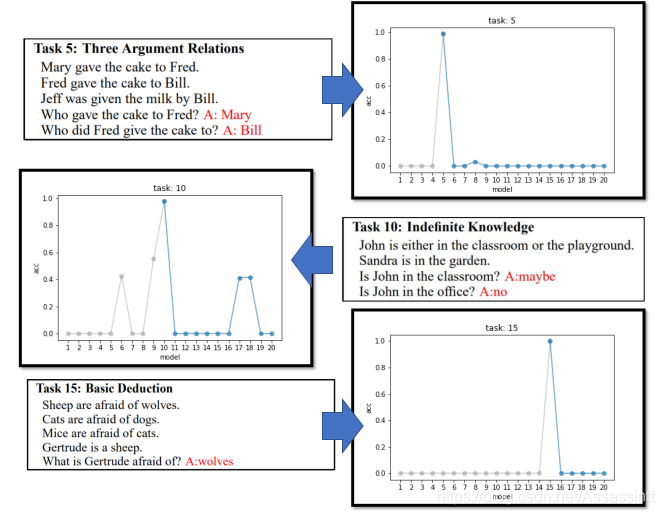 |
|---|---|
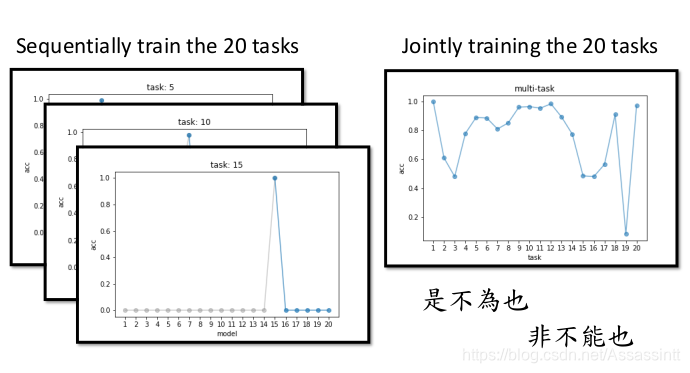 | 如果同一个NN, 同时学20 个任务, 每个题型都有一些正确率. |
这种现在称作Catastrophic Forgetting 灾难性遗忘.
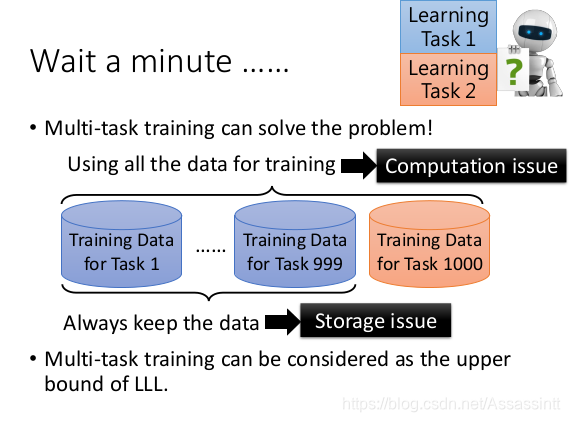
multi-task traning 可以解决这个问题, 但是, 当task 很多的时候, 有存储和计算能力的问题. 不能一直背负巨大的训练数据, 同时计算也更复杂.
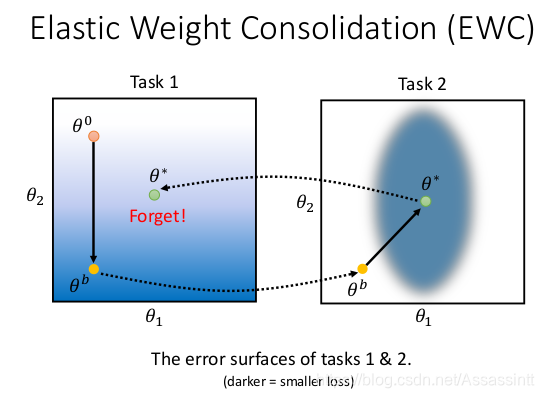
Elastic Weight Consolidation(EWC )
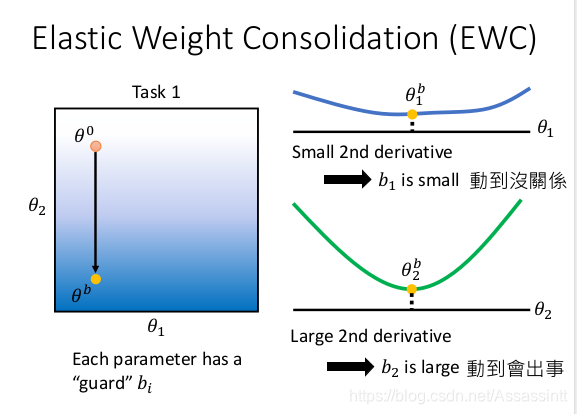
一种经典解法. EWC, 思想 , 过去学过的重要的weight , 不要改动, 只改动不重要的weight小的参数.
 |  |
|---|
b是before,
实际是做regularization, 规则化, 使得θi 接近 θb, bi 是守卫参数, bi = 0 , 新的θi 没有限制, 任意调整. bi越大, θi 越接近 θb
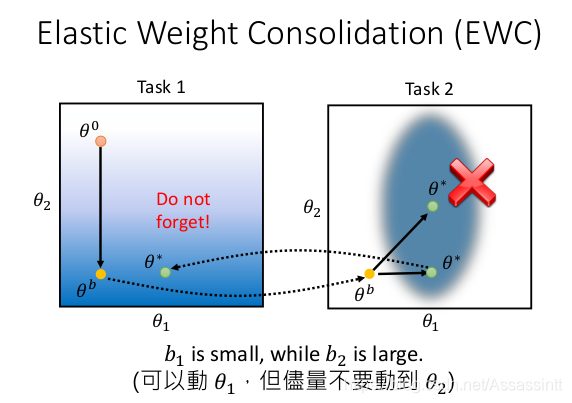
下面是ewc的图示例子, 先训练task1, 然后task2, 颜色越深, loss越小.
- 用gradient descent 方式, 再训练task2的时候, θ∗满足task2, 但是, 回到task1, loss 又变大了.
- 怎么计算守卫bi, 有很多种做法, 举个例子, 计算θ1 和 θ2 对Loss的二次微分, 看出山谷的每一个方向是宽敞还是狭窄, θ1宽敞, bi就小, θ2狭窄, bi大, 对loss 影响大.
- 用ewc的方式对task2 重新训练, 收敛在θ*, 回到task1, 没有遗忘task1的训练结果.
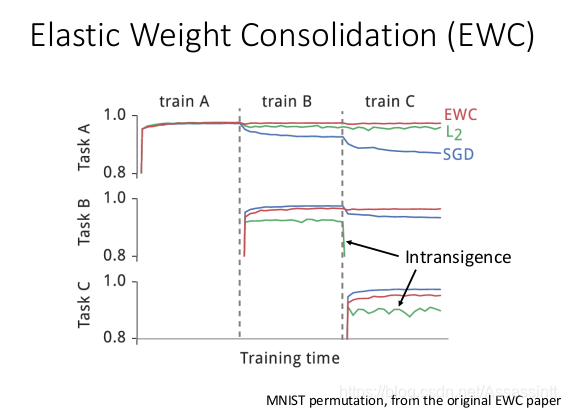
- 手写辨识的实验结果, 对图片做不同的破坏, 形成3个task. L2 的结果产生intransigence , L2的regulazaion 限制太大, 学不起来, 学不会会新的技能.
 |  |
|---|---|
 |  |
用不同的方法, 计算bi的方式,
• Elastic Weight Consolidation (EWC)
• http://www.citeulike.org/group/15400/article/14311063
• Synaptic Intelligence (SI)
• https://arxiv.org/abs/1703.04200
• Memory Aware Synapses (MAS) 最新
• Special part: Do not need labelled data, 只要x, 不要y
• https://arxiv.org/abs/1711.09601
generating data
multi-task learning 可以解决lifelong learning的遗忘的问题, 所以, 它一般作为LLL上限upperbound.
为了解决multi-task 存储数据多和训练复杂的问题 , 可以存一个model , 可以产生task的data . 通过使用生成模型生成伪数据进行多任务学习.
训练一个generator 可以学会产生 task1的data, 然后和task2的data加在一起, 可以训练生成一个generator 可以产生task1, task2 的data.
有些任务生成高清类影像. 在实用上能不能训练起来, 有待研究.
以上例子是手写辨识的例子,只是不同的task 加了noise. 可以用一个NN来训练.
有时不同的任务需要不同的network structure, 如task1 分类10个, task2 分类20个. 在life long learning 怎么做? 以下参考
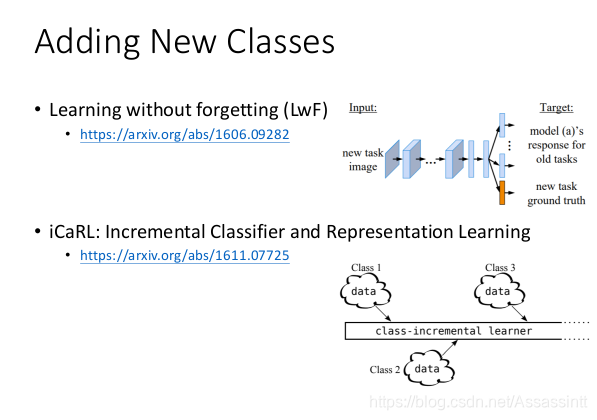
2. 知识迁移 Knowledge Transfer
希望不同任务的咨询可以互通有无. 而不是每个task 一个模型.
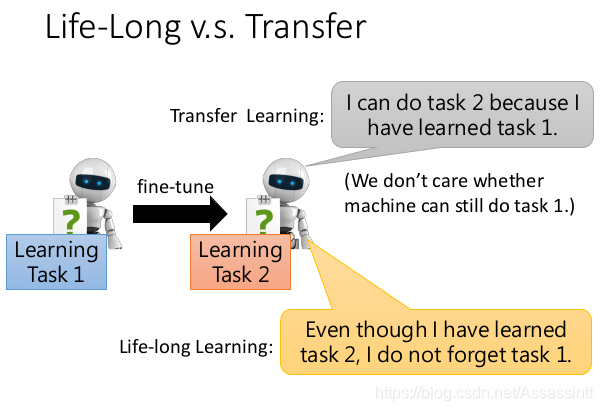
Life-Long v.s. Transfer
transfer learning , 要求, 学完任务1, 在任务2上做的更好.
life long learning , 要求, 任务1,任务2, 都要做的好. knowledge 既要迁移 也要rentension保留.
evaluate
evaluate 一个LLL的model.
 backward transfer, 计算机器有多不会遗忘.
backward transfer, 计算机器有多不会遗忘.
forward transfer, 计算机器还没有训练的T, 对此的预测.
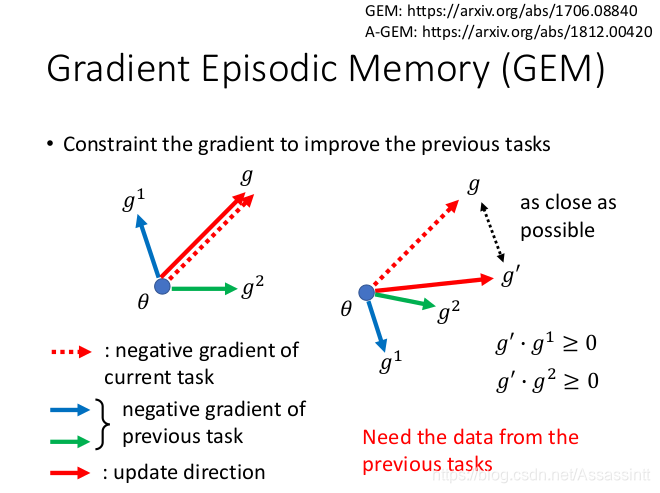
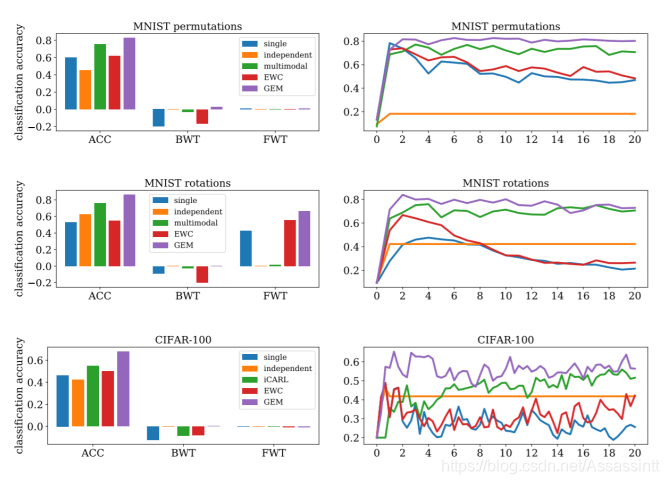
GEM
GEM Gradient Episodic Memory (渐变情景记忆, backward transfer 是> 0)
存之前的gradient, 在计算新的task的gradient的时候修改方向, 保持和之前的gradient 方向乘积为正, 对过去的task 有帮助, 移动gradient, g–> g’
3. Model Expansion
 真实场景下的机器学习系统,最终都会变成终身学习系统(Lifelong learning system),不断的有新数据,通过新的数据改善模型,刚开始数据量小,我们使用小的网络,可以防止过拟合并加快训练速度,但是随着数据量的增大,小网络就不足以完成复杂的问题了,这个时候我们就需要在小网络上进行扩展变成一个大网络了
真实场景下的机器学习系统,最终都会变成终身学习系统(Lifelong learning system),不断的有新数据,通过新的数据改善模型,刚开始数据量小,我们使用小的网络,可以防止过拟合并加快训练速度,但是随着数据量的增大,小网络就不足以完成复杂的问题了,这个时候我们就需要在小网络上进行扩展变成一个大网络了
任务太多, network已经到了极限, 让network 自动扩张model大小.
有效率的扩张, model 扩张的速度要比任务进来的速度慢. 不然model成长速度过快,没法存下来.
这是尚在研究的问题.以下是相关例子.
progressive NN
思路就是说我不能忘记第一个任务的网络,同时又能使用第一个任务的网络来做第二个任务。
task越来越多, 参数也会越来越多, 无法学太多task. 多一个任务, 多一个model

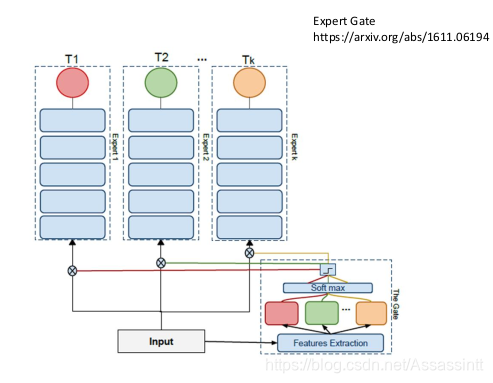
Expert Gate
简言之,希望通过一个auto-encoder gate来确定新的task所要用的expert network,从而选出与新任务相似性最高的旧任务,再进行进一步训练。
Net2Net

https://blog.csdn.net/cFarmerReally/article/details/80927981
左右network做的事情一模一样, 2个Nerual 变3个,input 一样, output 减半, network变宽, 但不会忘记已经学到的东西. 为了避免这两个nerual 一样, 给参数加上小小的noise ,让他们看上去不同在去做训练.
任务的顺序,对学习的记忆的保留和准确率有影响, 对于怎么为学习的顺序进行排序也是未来研究的方向.















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









