






目录
一.模型评估总体介绍
1>模型评估的概念
在机器学习中,模型评估是指对训练好的机器学习模型进行性能测量的过程,以便了解模型对未见数据的泛化能力。对模型进行评估的主要目的是验证模型的预测准确性和适用性,并且从中获取有关模型表现的有价值的统计数据。
2>什么是训练集、验证集和测试集
- 训练集:用于训练模型的数据集。
- 验证集:用于调整模型的超参数和验证模型性能的数据集。
- 测试集:用于衡量模型泛化能力的数据集,它代表了模型在生产环境中将要面对的数据。
3>评估指标
概念:在机器学习中扮演着关键的角色,主要用来帮助我们衡量模型的性能和指导模型选择。
常见的评估指标:
准确率:正确分类的样本数占总样本数的比例。
精确率和召回率:适用于不平衡分类问题,Precision 表示正确预测为正例的样本数占预测为正例的样本数的比例,Recall 表示正确预测为正例的样本数占实际正例的样本数的比例。
F1 Score:精确度和召回率的调和平均数,综合考虑了二者之间的平衡。
ROC曲线和AUC:用于评估二分类模型性能的曲线和曲线下面积。
混淆矩阵:展示了分类模型预测结果的准确性,了解真正例、真负例、假正例和假负例的数量。
4>什么是交叉验证
一种用来评估模型泛化性能的统计学方法,通常会将训练集数据分成若干分,每次选取其中一份作为验证集,剩下的作为新的训练集。重复这个过程多次,最终将结果综合在一起作为模型性能的估计。
5>过拟合与欠拟合
在模型评估中,过拟合和欠拟合是两种常见的问题,它们影响着机器学习模型的泛化能力与性能。
(1)过拟合
定义:当模型在训练数据集上表现良好,但在测试数据集上表现较差时,我们称之为模型出现过拟合。
原因:过拟合通常是由模型过于复杂,以至于能够“记住”训练数据集中的细节和噪声,而无法泛化到新的数据样本上。
表现:当模型过拟合时,它可能在训练集上表现非常好,但在测试集上表现较差,因为它无法泛化到新的数据样本。
(2)欠拟合
定义:当模型在训练数据集和测试数据集上都表现较差时,我们称之为模型出现欠拟合。
原因:欠拟合通常是由模型过于简单,无法捕捉到数据中的复杂性和特征,亦或者是模型的容量(复杂度)不够大。
表现:当模型欠拟合时,它在训练集上和测试集上都表现较差,不能很好地拟合数据。
(3)如何应对过拟合和欠拟合
可以通过减小模型的复杂度(如减少特征数量,增加正则化项),引入更多的数据进行训练,或者使用集成学习等方法来解决。
可以通过增加模型复杂度(如增加特征数量,增加模型的容量),使用更复杂的模型(比如深度神经网络),或者改进特征工程等方法来解决。
二.评估指标详解
1>混淆矩阵
混淆矩阵是用于描述分类模型预测性能的矩阵。对于二分类问题来说,通常是一个2×2的矩阵。它的四个元素分别是True Positive(真阳性)、False Negative(假阴性)、False Positive(假阳性)、True Negative(真阴性),这些元素用来帮助计算模型的精确率、召回率以及计算许多其他评估指标。
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目。
每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目;每一列中的数值表示真实数据被预测为该类的数目。
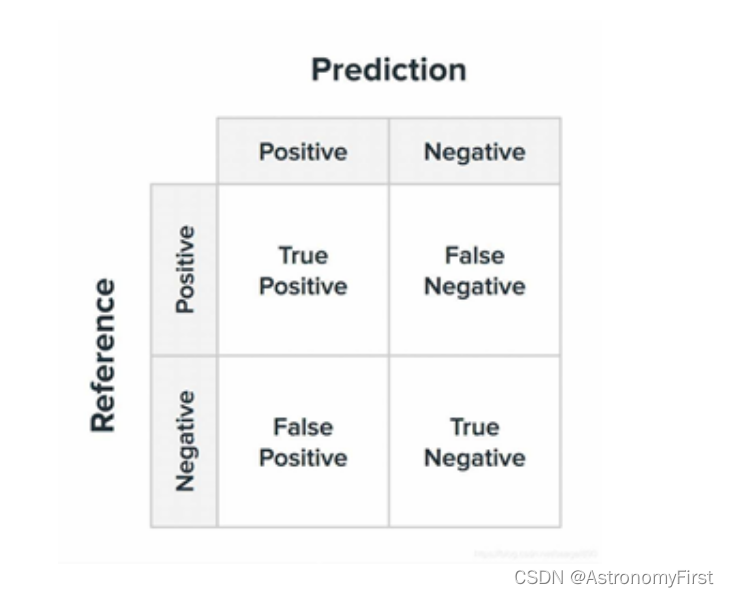
True Positive(TP):真正类。样本的真实类别是正类,并且模型识别的结果也是正类。
False Negative(FN):假负类。样本的真实类别是正类,但是模型将其识别为负类。
False Positive(FP):假正类。样本的真实类别是负类,但是模型将其识别为正类。
True Negative(TN):真负类。样本的真实类别是负类,并且模型将其识别为负类。
下面通过一个例子来加深对混淆矩阵的了解:
假设我们有一个二分类模型,用于预测病人是否患有某种疾病。对于这个疾病预测问题,我们的混淆矩阵可能如下所示:

在这个疾病预测问题中,我们采用了以下缩写:
- True Positive (TP):模型将患有疾病的病人正确地预测为患病的数量。
- True Negative (TN):模型将没有患有疾病的病人正确地预测为健康的数量。
- False Positive (FP):模型将没有患有疾病的病人错误地预测为患病的数量。
- False Negative (FN):模型将患有疾病的病人错误地预测为健康的数量。
然后我们对该混淆矩阵加入数据如下图:

从而通过该混淆矩阵,我们可以从中计算出精确度、召回率、F1 Score等指标,从而全面地评估我们的模型在预测疾病情况时的表现。
2>准确率
在分类问题中,是正确分类的样本数占总样本数的比例。表达式为:
准确率=TP+TN / TP+TN+FP+FN
TP:表示模型将正类别样本正确地预测为正类别的数量,即实际为正例,模型也预测为正例的数量。
TN:表示模型将负类别样本正确地预测为负类别的数量,即实际为负例,模型也预测为负例的数量。
FP:表示模型将负类别样本错误地预测为正类别的数量,即实际为负例,模型错误地预测为正例的数量。
FN:表示模型将正类别样本错误地预测为负类别的数量,即实际为正例,模型错误地预测为负例的数量。
3>精确率
在分类问题中,表示正确预测为正例的样本数占所有预测为正例的样本数的比例;用于衡量模型预测为正例的准确性。通常该指标适用于处理有严重后果的问题。(下面以医疗诊断中的阳性结果为例)
 假设我们在医疗诊断中使用机器学习模型来预测一种罕见疾病。现在我们假设该模型预测了100个样本为患有这种疾病,其中有80个样本是真正患有这种疾病,而剩下的20个样本是错误的预测。
假设我们在医疗诊断中使用机器学习模型来预测一种罕见疾病。现在我们假设该模型预测了100个样本为患有这种疾病,其中有80个样本是真正患有这种疾病,而剩下的20个样本是错误的预测。
在这种情况下,我们计算模型的精确率(Precision):
Precision = TP / (TP + FP) = 80 / (80 + 20) = 80%
这意味着在这个特定的例子中,该医疗诊断的模型预测为患有特定疾病的患者中,有80%的患者确实患有此疾病。在医疗诊断中,精确率尤为重要,因为它衡量了模型在疾病确诊时的准确性。高精确率意味着模型更准确地识别出真正患病的患者,有助于医生更加可靠地做出诊断。
4>召回率
在分类问题中,表示正确预测为正例的样本数占实际正例的样本数的比例;用于衡量模型发现正例的能力。(下面以校园安全系统为例)

假设在一个校园安全系统中,我们使用机器学习模型来预测孩子是否潜在受到欺凌的危险。假设在100个孩子中,有50个孩子实际上受到了欺凌,而我们的模型成功地识别了30个受到欺凌的孩子,并且错过了20个受到欺凌的孩子。
在这种情况下,我们计算模型的召回率(Recall):
Recall = TP / (TP + FN) = 30 / (30 + 20) = 60%
这意味着在这个特定的例子中,模型成功地识别了60% 受到欺凌的孩子。换句话说,模型能够及时发现 60% 的受到欺凌的孩子,也就是说,对受到欺凌的孩子的覆盖率为60%。在校园安全系统中,高召回率意味着模型能够更全面地发现可能受到欺凌的孩子,这对于及时进行干预、保护学生安全至关重要。
5>F1 Score
精确度和召回率的调和平均数,综合考虑了这两者的平衡情况。
公式为:F1=2(Precision * Recall) / (Percision * Recall)
F1 Score在分类问题中的主要用途:
(1)综合衡量精确率和召回率:
F1 Score综合考虑了精确率和召回率,协助我们全面地理解模型的分类性能。对于不平衡数据集或关注样本不均的情况下,F1 Score可以提供更准确的评估。
(2)平衡模型的性能:
F1 Score对于平衡精确率和召回率的提升有所帮助。它的权重对精确率和召回率是相等的,因此能够在模型性能评估过程中对二者进行平衡地考量。
(3)适用于二分类问题:
尤其适用于二分类问题,例如垃圾邮件识别、疾病诊断等场景。例如,在垃圾邮件识别中,F1 Score可以帮助我们全面地理解模型在识别垃圾邮件时的准确性和召回率表现。
6>ROC曲线与AUC
ROC曲线是一种用来评估二分类模型在各种分类阈值下的性能的图形化工具。横轴是假阳率(False Positive Rate),纵轴是真阳率(True Positive Rate)。AUC(Area Under the Curve)代表ROC曲线下的面积,AUC的取值范围在0到1之间,用来量化分类器的优劣,AUC值越高,分类器性能越好。
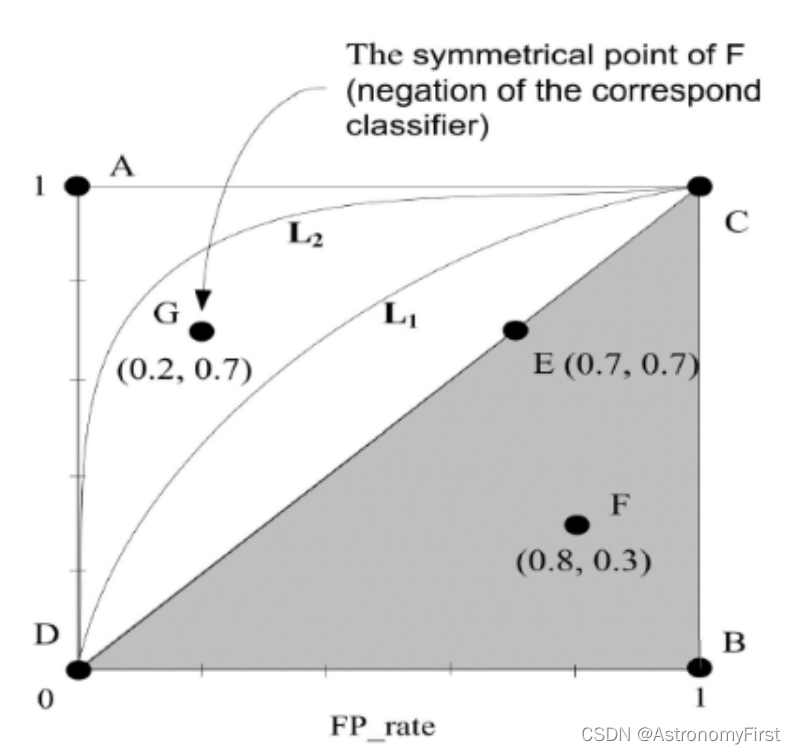
由上图解释图中的四个点以及曲线以及真阳率和假阳率:
A点:这是一个完美的分类器 B点:最糟糕的分类器
C点:分类器全部输出正样本 D点:分类器全部输出负样本
纵轴是真阳率:表示所有实际阳性样本被正确预测为阳性的比例
横轴是假阳率:假阳性率表示在所有阴性样本中,被错误地预测为阳性的比例
因此,真阳率越大,假阳率越小,曲线越靠近左上角,说明该分类器的性能越好。
三.ROC曲线的绘制以及相关代码
这里通过sklearn的内置数据库,来初始化并训练k近邻分类器,实现ROC曲线的绘制
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc, roc_auc_score
import matplotlib.pyplot as plt
# 加载乳腺癌数据集
cancer = datasets.load_breast_cancer()
X = cancer.data
y = cancer.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 初始化k近邻分类器
knn = KNeighborsClassifier(n_neighbors=5)
# 训练分类器
knn.fit(X_train, y_train)
# 预测概率
y_score = knn.predict_proba(X_test)[:, 1]
# 计算ROC曲线的真阳性率和假阳性率
fpr, tpr, thresholds = roc_curve(y_test, y_score)
# 计算AUC值
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange', lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc="lower right")
plt.show()
# 输出AUC值作为模型性能指标
print(f"AUC Score: {roc_auc_score(y_test, y_score)}")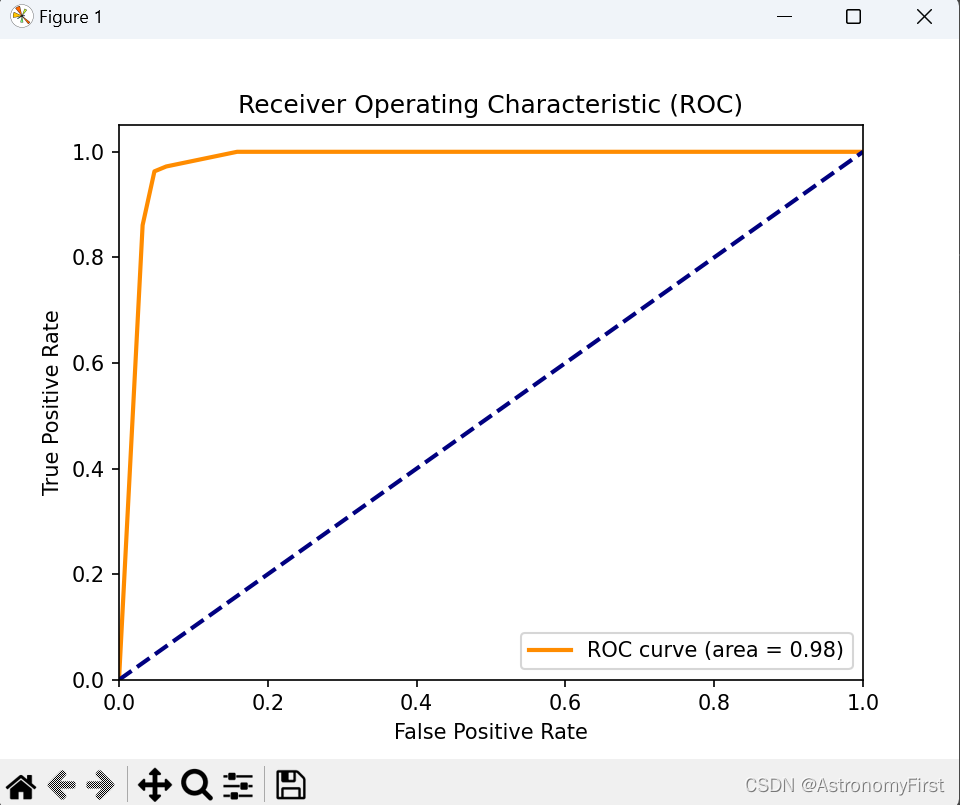
四.本次实验总结
通过本次实验我意识到了模型评估是机器学习中的关键环节,用于量化模型的性能。在评估过程中,数据通常分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整超参数,而测试集则用于最终评估模型的泛化能力。也是通过本次的实验,我对于这些特有名词的概念有了更深的认识。
同时,评估指标中,我也认识到了混淆矩阵是基础,包括真正例、假正例、真反例和假反例,进而衍生出准确率、精确率、召回率和F1 Score等指标。准确率衡量整体分类正确性,但可能受类别不平衡影响。精确率关注预测为正例的可靠性,而召回率衡量找到所有正例的能力。F1 Score是精确率和召回率的调和平均,更全面地评估模型性能。
最后,通过本次的实验,我对于什么是ROC曲线与AUC有了更多的认识,学会了ROC曲线通过不同阈值下的真正例率和假正例率展示模型性能,AUC则量化ROC曲线下的面积,用于比较不同模型。这些工具和指标共同构成模型评估的完整框架,都可以帮助我们选择和优化模型。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









