







算法面试必备-----推荐算法
算法面试必备-----推荐算法
推荐算法概述
1、基于流行度的推荐算法
比较简单粗暴,主要是对热点商品或者信息推荐。它主要是根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
优点是简单,适用于刚注册的新用户,能够解决对新用户进行推荐的冷启动问题。
缺点也很明显,它无法针对用户提供个性化的推荐。基于这种算法也可做一些优化,比如加入用户分群的流行度排序,例如把热榜上的体育内容优先推荐给体育迷,把政要热文推给热爱谈论政治的用户。
2、基于内容的推荐算法
是在推荐引擎出现之初应用最为广泛的推荐机制,它的核心思想是根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。这种推荐系统多用于一些资讯类的应用上,针对文章本身抽取一些tag作为该文章的关键词,继而可以通过这些tag来评价两篇文章的相似度。
优点在于:
-
易于实现,不需要用户数据因此不存在稀疏性和冷启动问题。
-
基于物品本身特征推荐,因此不存在过度推荐热门的问题。
缺点在于:
抽取的特征既要保证准确性又要具有一定的实际意义,否则很难保证推荐结果的相关性。豆瓣网采用人工维护tag的策略,依靠用户去维护内容的tag的准确性。
3、基于关联规则的推荐算法
更常见于电子商务系统中,并且也被证明行之有效。其实际的意义为购买了一些物品的用户更倾向于购买另一些物品。基于关联规则的推荐系统的首要目标是挖掘出关联规则,也就是那些同时被很多用户购买的物品集合,这些集合内的物品可以相互进行推荐。目前关联规则挖掘算法主要从Apriori和FP-Growth两个算法发展演变而来。
基于关联规则的推荐系统一般转化率较高,因为当用户已经购买了频繁集合中的若干项目后,购买该频繁集合中其他项目的可能性更高。
该机制的缺点如下:
-
计算量较大,但是可以离线计算,因此影响不大。
-
由于采用用户数据,不可避免的存在冷启动和稀疏性问题。
-
存在热门项目容易被过度推荐的问题。
4、基于协同过滤的推荐算法
协同过滤是一种在推荐系统中广泛采用的推荐方法。这种算法基于一个“物以类聚,人以群分”的假设,喜欢相同物品的用户更有可能具有相同的兴趣。基于协同过滤的推荐系统一般应用于有用户评分的系统之中,通过分数去刻画用户对于物品的喜好。协同过滤被视为利用集体智慧的典范,不需要对项目进行特殊处理,而是通过用户建立物品与物品之间的联系。
目前,协同过滤推荐系统被分化为两种类型:基于用户(User-based)的推荐和基于物品(Item-based)的推荐。
4.1、基于用户的推荐
基于用户的协同过滤推荐的基本原理是,根据所有用户对物品或者信息偏好(评分),发现与当前用户口味和偏好相似的“邻居”用户群,在一般应用中是采用计算K近邻的算法;基于这 K个邻居的历史偏好信息,为当前用户进行推荐。
优点:
在于推荐物品之间在内容上可能完全不相关,因此可以发现用户的潜在兴趣,并且针对每个用户生成其个性化的推荐结果。
缺点:
在于一般的Web系统中,用户的增长速度都远远大于物品的增长速度,因此其计算量的增长巨大,系统性能容易成为瓶颈。因此在业界中单纯的使用基于用户的协同过滤系统较少。

4.2、基于物品的推荐
基于物品的协同过滤和基于用户的协同过滤相似,它使用所有用户对物品或者信息的偏好(评分),发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。基于物品的协同过滤可以看作是关联规则推荐的一种退化,但由于协同过滤更多考虑了用户的实际评分,并且只是计算相似度而非寻找频繁集,因此可以认为基于物品的协同过滤准确率较高并且覆盖率更高。
优点:
同基于用户的推荐相比,基于物品的推荐应用更为广泛,扩展性和算法性能更好。由于项目的增长速度一般较为平缓,因此性能变化不大。
缺点:
无法提供个性化的推荐结果。

协同过滤算法总结
两种协同过滤:基于用户和基于物品两个策略中应该如何选择呢?其实基于物品的协同过滤推荐机制是Amazon 在基于用户的机制上改良的一种策略,因为在大部分的Web 站点中,物品的个数是远远小于用户的数量的,而且物品的个数和相似度相对比较稳定;同时基于物品的机制比基于用户的实时性更好。但也不是所有的场景都是这样的情况,在一些新闻推荐系统中,也许物品,也就是新闻的个数可能大于用户的个数,而且新闻的更新程度也有很快,所以它的相似度依然不稳定。所以,推荐策略的选择其实也和具体的应用场景有很大的关系。
基于协同过滤的推荐机制是现今应用最为广泛的推荐机制,它有以下几个显著的优点:
1.它不需要对物品或者用户进行严格的建模,而且不要求物品的描述是机器可以理解的,所以这种方法也是领域无关的。
2.这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好。
然后而它也存在以下几个问题:
1.方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题。
2.推荐的效果依赖于用户历史偏好数据的多少和准确性。
3.在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等。
4.对于一些特殊品味的用户不能给予很好的推荐。
5.由于以历史数据为基础,抓取和建模用户的偏好后,很难修改或者根据用户的使用演变,从而导致这个方法不够灵活。
5、基于模型的推荐算法
基于模型的方法有很多,主要是使用常用的机器学习算法对目标用户简历推荐算法模型,然后对用户的爱好进行预测推荐以及对推荐的结果打分排序等。
基于模型的算法特点十分明显:快速、准确。因此它比较适用于实时性比较高的业务如新闻、广告等。当然,而若是需要这种算法达到更好的效果,则需要人工干预反复的进行属性的组合和筛选,也就是我们常说的 特征工程。而由于新闻的时效性,系统也需要反复更新线上的数学模型,以适应变化。
6、混合算法
真正的现实应用中,其实基本上很少会使用单一的推荐算法去实现推荐任务。因此,大型成熟网站的推荐系统都是基于各种推荐算法的优缺点以及适合场景分析的情况下的组合使用的“混合算法”。当然,混合策略也会是十分丰富的,例如不同策略的算法加权、不同场景和阶段使用不同的算法等等。具体的怎么混合需要结合实际的应用场景进行分析与应用。
推荐算法详解
关联规则:基础概念
(1)事务和项

事务是行,项行中的项,项集则是0个或多个项组成的集合,频繁项集是出现次数较多的项集
(2)关联规则

X项集能推出与X无交集的Y项集则说明X是关联规则前提,Y是关联规则结果
(3)支持度


包含“豆奶”的事务数(行数)/总事务数(行数)
既包含“尿布”又包含“啤酒”的事务数(行数)/总事务数(行数)
(4)置信度


类似于条件概率
(5)关联规则性质

关联规则:Apriori算法
算法过程

举例


下面我们对Aprior算法流程做一个总结。
输入:数据集合D,支持度阈值𝛼
输出:最大的频繁k项集
1)扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁0项集为空集。
2)挖掘频繁k项集
(a) 扫描数据计算候选频繁k项集的支持度
(b) 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。如果得到的频繁k项集只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
(c) 基于频繁k项集,连接生成候选频繁k+1项集。
3) 令k=k+1,转入步骤2。
从算法的步骤可以看出,Aprior算法每轮迭代都要扫描数据集,因此在数据集很大,数据种类很多的时候,算法效率很低。
算法的不足

关联规则:FP-growth算法
算法概述
FP-growth(Frequent Pattern Tree, 频繁模式树),是韩家炜老师提出的挖掘频繁项集的方法,是将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或频繁项对,即常在一块出现的元素项的集合FP树。
FP-growth算法比Apriori算法效率更高,在整个算法执行过程中,只需遍历数据集2次,就能够完成频繁模式发现,其发现频繁项集的基本过程如下:
(1)构建FP树
(2)从FP树中挖掘频繁项集
算法流程
FP-growth的一般流程如下:
1:先扫描一遍数据集,得到频繁项为1的项目集,定义最小支持度(项目出现最少次数),删除那些小于最小支持度的项目,然后将原始数据集中的条目按项目集中降序进行排列。
2:第二次扫描,创建项头表(从上往下降序),以及FP树。
3:对于每个项目(可以按照从下往上的顺序)找到其条件模式基(CPB,conditional patten base),递归调用树结构,删除小于最小支持度的项。如果最终呈现单一路径的树结构,则直接列举所有组合;非单一路径的则继续调用树结构,直到形成单一路径即可。









协同过滤(CF)
算法概述
协同过滤算法是一种较为著名和常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。也就是常见的“猜你喜欢”,和“购买了该商品的人也喜欢”等功能。它的主要实现由:
●根据和你有共同喜好的人给你推荐
●根据你喜欢的物品给你推荐相似物品
●根据以上条件综合推荐
因此可以得出常用的协同过滤算法分为两种,基于用户的协同过滤算法(user-based collaboratIve filtering),以及基于物品的协同过滤算法(item-based collaborative filtering)。特点可以概括为“人以类聚,物以群分”,并据此进行预测和推荐。
基于用户的协同过滤算法(User-Based CF)
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图 2 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 – 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A

基本步骤
一、寻找用户间的相似度
1、Jaccard公式
Jaccard系数主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具体值的大小,只能获得“是否相同”这个结果,所以Jaccard系数只关心个体间共同具有的特征是否一致这个问题。如果比较X与Y的Jaccard相似系数,只比较xn和yn中相同的个数。
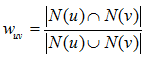
Jaccard公式
2、皮尔逊相关系数
皮尔逊相关系统是比欧几里德距离更加复杂的可以判断人们兴趣相似度的一种方法。它在数据不是很规范时,会倾向于给出更好的结果。
假定有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:
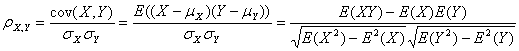
皮尔逊相关系数公式一
公式二:
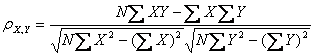
皮尔逊相关系数公式二
公式三:
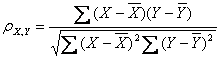
皮尔逊相关系数公式三
公式四:
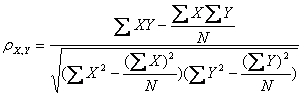
皮尔逊相关系数公式四
上述四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
3、欧几里德距离
假定两个用户X、Y,均为n维向量,表示用户对n个商品的评分,那么X与Y的欧几里德距离就是
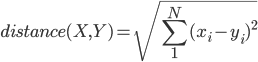
多维欧几里德距离公式
数值越小则代表相似度越高,但是对于不同的n,计算出来的距离不便于控制,所以需要进行如下转换:
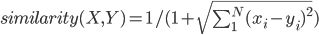
相似度公式
使得结果分布在(0,1]上,数值越大,相似度越高。
4、余弦距离
余弦距离,也称为余弦相似度,是用向量空间中两个向量余弦值作为衡量两个个体间差异大小的度量值。
与前面的欧几里德距离相似,用户X、Y为两个n维向量,套用余弦公式,其余弦距离表示为:
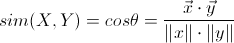
余弦距离公式
即两个向量夹角的余弦值。但是相比欧式距离,余弦距离更加注意两个向量在方向上的相对差异,而不是在空间上的绝对距离,具体可以借助下图来感受两者间的区别:

二、推荐物品
在选取上述方法中的一种得到各个用户之间相似度后,针对目标用户u,我们选出最相似的k个用户,用集合S(u,k)表示,将S中所有用户喜欢的物品提取出来并去除目标用户u已经喜欢的物品。然后对余下的物品进行评分与相似度加权,得到的结果进行排序。最后由排序结果对目标用户u进行推荐。其中,对于每个可能推荐的物品i,用户u对其的感兴趣的程度可以用如下公式计算:
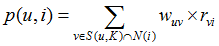
用户u对物品i感兴趣的程度
rvi表示用户v对i的喜欢程度,即对i的评分,wuv表示用户u和v之间的相似度。
三、 收集用户偏好
在一般应用中,我们提取的用户行为一般都多于一种,关于如何组合这些不同的用户行为,基本上有以下两种方式:
(1)将不同的行为分组:一般可以分为“查看”和“购买”等等,然后基于不同的行为,计算不同的用户 / 物品相似度。类似于当当网或者 Amazon 给出的“购买了该图书的人还购买了 …”,“查看了图书的人还查看了 …”
(2)根据不同行为反映用户喜好的程度将它们进行加权,得到用户对于物品的总体喜好。一般来说,显式的用户反馈比隐式的权值大,但比较稀疏,毕竟进行显示反馈的用户是少数;同时相对于“查看”,“购买”行为反映用户喜好的程度更大,但这也因应用而异。
收集了用户行为数据,我们还需要对数据进行一定的预处理,其中最核心的工作就是:减噪和归一化。
(1)减噪:用户行为数据是用户在使用应用过程中产生的,它可能存在大量的噪音和用户的误操作,我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪音,这样可以是我们的分析更加精确。
(2)归一化:如前面讲到的,在计算用户对物品的喜好程度时,可能需要对不同的行为数据进行加权。但可以想象,不同行为的数据取值可能相差很大,比如,用户的查看数据必然比购买数据大的多,如何将各个行为的数据统一在一个相同的取值范围中,从而使得加权求和得到的总体喜好更加精确,就需要我们进行归一化处理。最简单的归一化处理,就是将各类数据除以此类中的最大值,以保证归一化后的数据取值在 [0,1] 范围中。
进行的预处理后,根据不同应用的行为分析方法,可以选择分组或者加权处理,之后我们可以得到一个用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值。
基于物品的协同过滤算法(Item-Based CF)
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。图 3 给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。

User CF vs. Item CF
下面我们分几个不同的角度深入看看它们各自的优缺点和适用场景:
(1)计算复杂度
Item CF 和 User CF 是基于协同过滤推荐的两个最基本的算法,User CF 是很早以前就提出来了,Item CF 是从 Amazon 的论文和专利发表之后(2001 年左右)开始流行,大家都觉得 Item CF 从性能和复杂度上比 User CF 更优,其中的一个主要原因就是对于一个在线网站,用户的数量往往大大超过物品的数量,同时物品的数据相对稳定,因此计算物品的相似度不但计算量较小,同时也不必频繁更新。但我们往往忽略了这种情况只适应于提供商品的电子商务网站,对于新闻,博客或者微内容的推荐系统,情况往往是相反的,物品的数量是海量的,同时也是更新频繁的,所以单从复杂度的角度,这两个算法在不同的系统中各有优势,推荐引擎的设计者需要根据自己应用的特点选择更加合适的算法。
(2)适用场景
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。比如在购书网站上,当你看一本书的时候,推荐引擎会给你推荐相关的书籍,这个推荐的重要性远远超过了网站首页对该用户的综合推荐。可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏览的重要手段。同时 Item CF 便于为推荐做出解释,在一个非社交网络的网站中,给某个用户推荐一本书,同时给出的解释是某某和你有相似兴趣的人也看了这本书,这很难让用户信服,因为用户可能根本不认识那个人;但如果解释说是因为这本书和你以前看的某本书相似,用户可能就觉得合理而采纳了此推荐。
相反的,在现今很流行的社交网络站点中,User CF 是一个更不错的选择,User CF 加上社会网络信息,可以增加用户对推荐解释的信服程度。
(3)推荐多样性和精度
研究推荐引擎的学者们在相同的数据集合上分别用 User CF 和 Item CF 计算推荐结果,发现推荐列表中,只有 50% 是一样的,还有 50% 完全不同。但是这两个算法确有相似的精度,所以可以说,这两个算法是很互补的。
关于推荐的多样性,有两种度量方法:
第一种度量方法是从单个用户的角度度量,就是说给定一个用户,查看系统给出的推荐列表是否多样,也就是要比较推荐列表中的物品之间两两的相似度,不难想到,对这种度量方法,Item CF 的多样性显然不如 User CF 的好,因为 Item CF 的推荐就是和以前看的东西最相似的。
第二种度量方法是考虑系统的多样性,也被称为覆盖率 (Coverage),它是指一个推荐系统是否能够提供给所有用户丰富的选择。在这种指标下,Item CF 的多样性要远远好于 User CF, 因为 User CF 总是倾向于推荐热门的,从另一个侧面看,也就是说,Item CF 的推荐有很好的新颖性,很擅长推荐长尾里的物品。所以,尽管大多数情况,Item CF 的精度略小于 User CF, 但如果考虑多样性,Item CF 却比 User CF 好很多。
如果你对推荐的多样性还心存疑惑,那么下面我们再举个实例看看 User CF 和 Item CF 的多样性到底有什么差别。首先,假设每个用户兴趣爱好都是广泛的,喜欢好几个领域的东西,不过每个用户肯定也有一个主要的领域,对这个领域会比其他领域更加关心。给定一个用户,假设他喜欢 3 个领域 A,B,C,A 是他喜欢的主要领域,这个时候我们来看 User CF 和 Item CF 倾向于做出什么推荐:如果用 User CF, 它会将 A,B,C 三个领域中比较热门的东西推荐给用户;而如果用 ItemCF,它会基本上只推荐 A 领域的东西给用户。所以我们看到因为 User CF 只推荐热门的,所以它在推荐长尾里项目方面的能力不足;而 Item CF 只推荐 A 领域给用户,这样他有限的推荐列表中就可能包含了一定数量的不热门的长尾物品,同时 Item CF 的推荐对这个用户而言,显然多样性不足。但是对整个系统而言,因为不同的用户的主要兴趣点不同,所以系统的覆盖率会比较好。
从上面的分析,可以很清晰的看到,这两种推荐都有其合理性,但都不是最好的选择,因此他们的精度也会有损失。其实对这类系统的最好选择是,如果系统给这个用户推荐 30 个物品,既不是每个领域挑选 10 个最热门的给他,也不是推荐 30 个 A 领域的给他,而是比如推荐 15 个 A 领域的给他,剩下的 15 个从 B,C 中选择。所以结合 User CF 和 Item CF 是最优的选择,结合的基本原则就是当采用 Item CF 导致系统对个人推荐的多样性不足时,我们通过加入 User CF 增加个人推荐的多样性,从而提高精度,而当因为采用 User CF 而使系统的整体多样性不足时,我们可以通过加入 Item CF 增加整体的多样性,同样同样可以提高推荐的精度。
(4)用户对推荐算法的适应度
前面我们大部分都是从推荐引擎的角度考虑哪个算法更优,但其实我们更多的应该考虑作为推荐引擎的最终使用者 — 应用用户对推荐算法的适应度。
对于 User CF,推荐的原则是假设用户会喜欢那些和他有相同喜好的用户喜欢的东西,但如果一个用户没有相同喜好的朋友,那 User CF 的算法的效果就会很差,所以一个用户对的 CF 算法的适应度是和他有多少共同喜好用户成正比的。
Item CF 算法也有一个基本假设,就是用户会喜欢和他以前喜欢的东西相似的东西,那么我们可以计算一个用户喜欢的物品的自相似度。一个用户喜欢物品的自相似度大,就说明他喜欢的东西都是比较相似的,也就是说他比较符合 Item CF 方法的基本假设,那么他对 Item CF 的适应度自然比较好;反之,如果自相似度小,就说明这个用户的喜好习惯并不满足 Item CF 方法的基本假设,那么对于这种用户,用 Item CF 方法做出好的推荐的可能性非常低。















 2439
2439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









