







【前沿进展】训练参数规模万亿的预训练模型,对于超级计算机而言是不小的挑战。如何提升超算的计算效率,实现更大规模的参数训练,成为近年来研究者探索的课题。在近日举办的Big Model Meetup第二期活动中,清华大学长聘副教授,智源青年科学家翟季冬做特邀报告,介绍了在国产超级计算机上训练百万亿参数的超大规模预训练模型解决方案。智源社区对内容进行了整理。
活动回看地址:https://event.baai.ac.cn/activities/175
演讲人:翟季冬
整理人:李栋栋
审校:赵万铖、戴一鸣

01
背景
近几年,如果大家经常关注科技新闻,就能发现大规模预训练模型在很多领域都有较强的影响力,如谷歌最新的推荐系统、搜索引擎、国内阿里的淘宝等,它们的一些图像生成任务都采用了预训练模型。下图中右侧的牛油果形状的扶手椅的小图是在网上找的,这些图片本来是不存在的,都是通过预训练模型来生成的。

从计算的角度来考虑,预训练模型的核心主要是Transformer,该模型主要的计算集中在嵌入层、注意力层还有前馈网络。如果从底层的计算来看,这些问题的核心都是矩阵乘法,而在高性能计算领域,实际上对矩阵乘法已经开展了大量的优化工作。
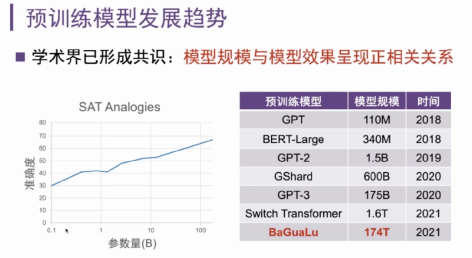
02
预训练模型的发展趋势
上面图片可以看到横坐标是模型的参数量,从最早的GPT大约是1.1亿个参数,然后到最新的GPT-3和Switch Transformer达到了上万亿的参数。至少从目前来看,探索更大参数量的模型仍具有很重要的意义。从计算的角度来看,模型规模在变的越来越大、训练数据逐步增多,此时,单机就无法满足非常大规模模型的训练。
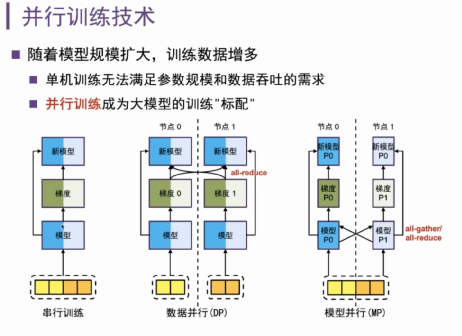
比如说最经典的串行训练,在训练过程中,每一轮迭代会产生梯度,然后去更新模型,这个过程不断重复迭代,最后会达到收敛的状态。当这个模型变得很大的时候,会有一些典型的并行策略来处理模型,最常见的是数据并行和模型并行。
数据并行是把输入数据进行拆分,然后模型在不同节点上有都会有一个完整的拷贝。数据并行过程中,节点两边各得到部分梯度,经过一次all-reduce的通信,交互之后更新模型,并产生全局通信。
模型并行,就是当模型很大,可以把模型中间切一刀,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 12
12











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









