







算法简称:GOTURN(Generic Object Tracking Using Regression Networks)
作者是斯坦福的David Held
文章以及附件: http://davheld.github.io/GOTURN/GOTURN.html
算法源码: https://github.com/autocyz/GOTURN
1、算法速度
当我第一眼看到文章题目时,真的被吓一跳,用深度网络做跟踪能达到100FPS?
are you kiding?
再一看, 哦,原来是在GPU上跑的。
But,即使是GPU这也还是很快啊,别的用深度网络做跟踪的能达到10FPS就very well了!
在看文章内容之前,咱们先看看这个算法的速度到底是怎样的。引用作者中的内容:
On an Nvidia GeForce GTX Titan X GPU with cuDNN acceleration, our tracker runs at 6.05 ms per frame (not including the 1 ms to load each image in OpenCV), or 165 fps. On a GTX 680 GPU, our tracker runs at an average of 9.98 ms per frame, or 100 fps. If only a CPU is available, the tracker runs at 2.7 fps.
好一点的GPU,能达到165fps;稍微逊色一点的GPU,能达到100fps;不用GPU呢,2.7fps(对于用CNN做跟踪的,的确是很不错的速度了,鄙人看过一个CNN做跟踪的算法用好的GPU,也才7fps)
最近亲自跑了一下,发现速度确实可喜!!!
2、算法整体框架:

图1 算法整体框架1
整个算法实现的框架如上图:作者将上一帧的目标和当前帧的搜索区域同时经过CNN的卷积层(Conv Layers),然后将卷积层的输出通过全连接层(Fully-Connected Layers),用于回归(regression)当前帧目标的位置。整个框架可以分为两个部分:
- 1、卷积层,用于提取目标区域和搜索区域的特征
- 2、全连接层,被当成一个回归算法,用于比较目标特征和搜索区域特征,输出新的目标位置
作者对网络的训练是offline的,在跟踪的时候没有online update的过程。这也是算法速度足够快的一个重要原因,把耗时的计算过程都离线做好,跟踪过程只有一个计算前馈网络的过程,

图2 算法整体框架2
3、算法实现细节
3.1、算法输入输出形式
输入:
在第t-1帧中,假设目标所在位置为(cx,cy),其大小为(w,h),则提取一块大小为(2w,2h)的图像块输入到CNN中。
在第t帧中,也以(cx,cy)为中心,提取大小为(2w,2h)的图像块,输入到CNN中。
输出:
输出目标在第t帧中左上角和右下角的坐标。
3.2、网络结构
见图1。
网络的卷积层采用的是CaffeNet的前五层(caffenet:
https://github.com/BVLC/caffe/tree/master/models/bvlc_reference_caffenet)。
并在imagenet上进行了预训练。
后面是3层全连接层,每层都有4096个结点,全连接层之后是一个只有四个结点的输出层,用于输出目标左上、右下的坐标。
3.3、网络的训练过程
这篇文章的训练方法比较有意思,在看他如何训练前,先看作者的一些关于跟踪视频序列性质的研究:
对于跟踪问题,一般的当前帧目标的位置和尺度都与上一帧是有关系,这个关系到底是怎么样的暂时没人分析过,作者通过对视频序列中的groundtruth进行研究发现,当前帧目标的位置和尺度变化与上一帧的目标存在着某种分布关系,具体分析如下:
上述公式可以写成如下形式:
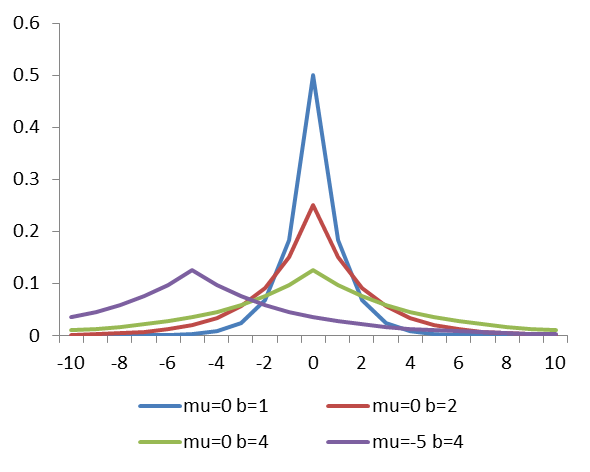
图3 laplace分布示意图
作者通过统计实验发现上述的四个参数的分布图像如下:
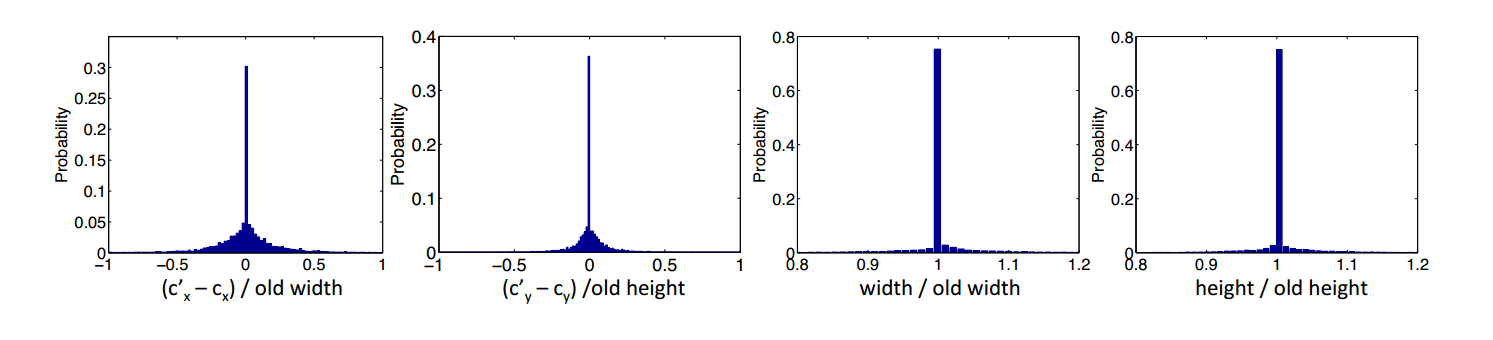
图4 作者实验验证laplace分布
观察上述分布可以发现, Δx 和 Δy 符合均值为0,尺度为1/5的laplace分布, γw 和 γh 符合均值为1,尺度为1/15的laplace分布。
有了上述发现,作者在训练网络时,对数据进行了人工扩充(data augmentation),如图4,在训练阶段,对目标的位置和尺度添加符合上述分布的转换(shift),为了避免尺度变化过大对网络造成不利影响,其限制了尺度变化范围 γw,γh∈(0.6,1.4) 。

图5 video data augmentation
另外,他不仅对视频序列进行训练,还对一些单帧图像也进行了训练,实现方法类似于上述的视频数据的data augmentation过程,其对标有groundtruth的图片随机进行位置和尺度的变换,变换的参数也符合上述的laplace分布

图6 image data augmentation
4、扩充实验
作者做了非常多且非常细致、严谨的实验,每个实验都有理有据,实验设置的条件也合情合理,且每个实验都验证了不同的条件或者情形。
一、data augmentation对算法的影响

图7 data augmentation对算法的影响
作者发现,batch size取50,augmented data的个数可以去取0~49,至少保留一个真实样本(因为augmented data都是从这个真实样本变换得来的)。观察上图可发现,性能最好的是batch中有49个augmented data只有一个real data,但是实际上当augmented data的数量高于20的时候,性能基本保持不变了。
作者文章使用的batch size是50,作者对每个图像进行了10倍的data augmentation。
二、全连接层个数对算法的影响
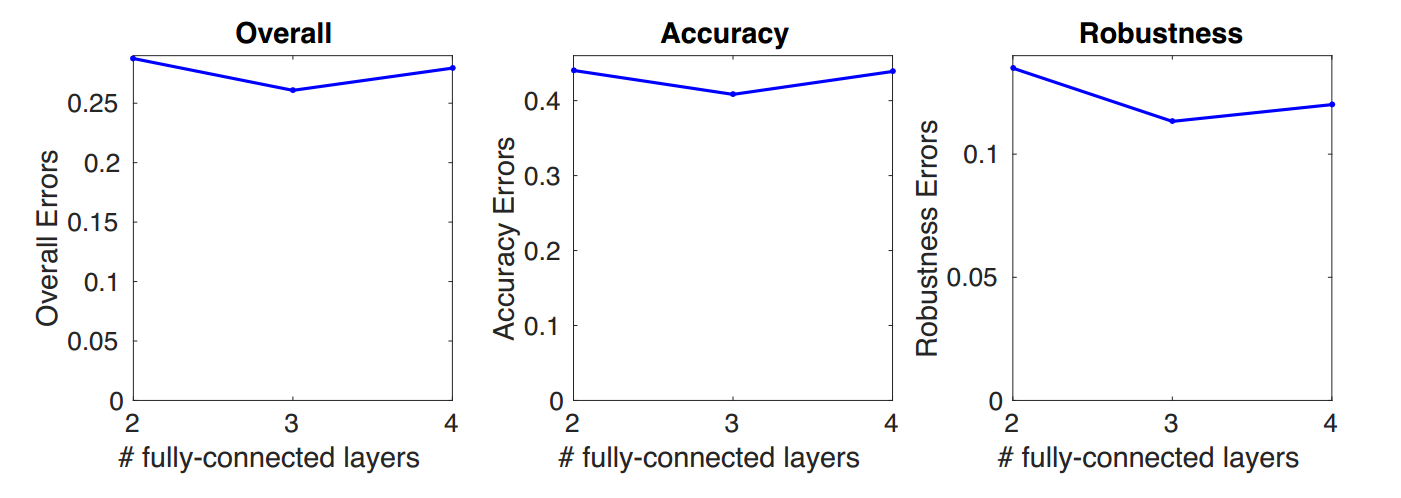
图8 全连接层个数对算法的影响
实验发现,全连接层个数为3时,效果最好。(这说明作者全连接层个数不是乱取的,是有理有据的)
三、多个因素对整体效果的影响
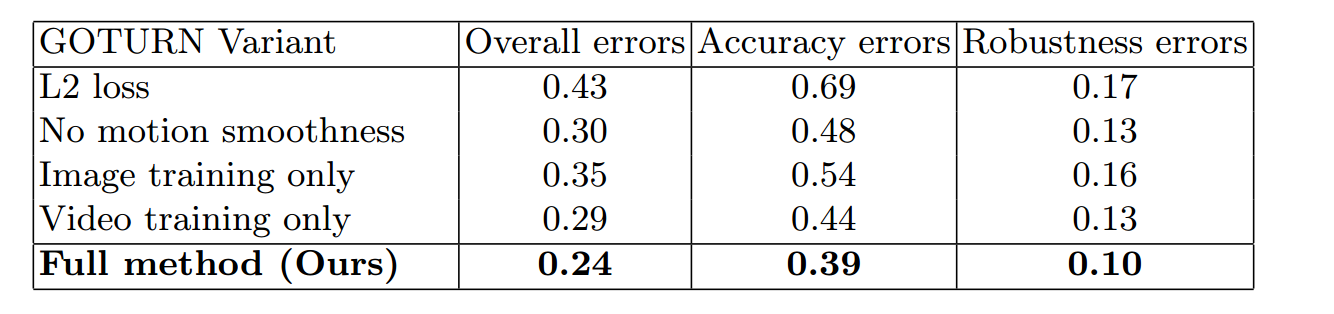
图9 多个因素对整体效果的影响
作者还做了损失函数、motion smoothness (data augmentation)、image data对整体性能的影响,最后发现使用L1 loss + motion smothness + image training + video training是效果最好的。
四、泛化性能实验

图10 泛化性能实验
随着训练视频的增加,算法的泛化性能越好。
参考资料:
1、Learning to Track at 100 FPS with Deep Regression Networks
2、Learning to Track at 100 FPS with Deep Regression Networks - Supplementary Material
3、拉普拉斯分布















 2113
2113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









