







目录
常见问题类型
预测(有限时空或长远趋势)与变量关系
差分/微分方程(稳定性原理)
微分即求导数。
差分是一种数学操作,表示按特定顺序的连续观察值之间的差异。在时间序列分析中,差分常用来使非平稳数据变得平稳。
一阶差分的计算公式是:
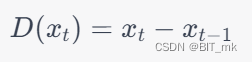
即当前时刻的值减去上一时刻的值。如果数据仍不平稳,可以继续进行二阶、三阶等高阶差分。
差分的目的是消除时间序列数据中的趋势和季节性模式,从而使得数据更容易进行建模和预测。
例子
使用ARIMA模型(一种常用的差分方程模型)来预测股票价格。
import yfinance as yf
# 获取Apple的股票数据
stock = yf.Ticker("AAPL")
data = stock.history(period="1y")
# 保存为CSV文件
data['Close'].to_csv('stock_prices.csv')import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# 读取股票价格数据
data = pd.read_csv('stock_prices.csv')
price = data['Close']
# 差分以使数据稳定
diff_price = price.diff().dropna()
# 拟合ARIMA模型
model = ARIMA(diff_price, order=(1,1,1))
fit_model = model.fit()
# 进行预测
forecast = fit_model.forecast(steps=5)
# 将预测的差分还原为原始价格
predicted_price = price.iloc[-1] + forecast.cumsum()
# 可视化结果
plt.plot(price, label='Actual')
plt.plot(range(len(price), len(price) + 5), predicted_price, label='Predicted')
plt.legend()
plt.show()
统计回归、时间序列模型(应用统计学)
-
统计回归:
- 作用: 通过分析自变量与因变量之间的关系来预测或解释一个或多个响应变量。
- 例子: 在房地产中,可以使用房屋的特性(如面积、房间数量等)作为自变量,来预测房价(因变量)。
- 方法: 常用的回归方法有线性回归、多项式回归等。
-
时间序列模型:
- 作用: 时间序列模型用于分析一系列按时间顺序排列的数据点,以捕捉潜在的趋势、季节性和周期性。
- 例子: 在股票市场分析中,可以使用时间序列模型来预测未来的股票价格。
- 方法: 常用的时间序列方法有ARIMA、季节性分解、指数平滑等。
随机过程
随机过程是一系列随机变量的集合,描述了随时间或空间变化的不确定或随机现象。
例子
以随机漫步模型来预测股价。
随机漫步模型是一种数学概念,用于描述一系列随机步骤构成的路径。在这个模型中,每一步的方向和长度都是随机确定的。它经常用于描述许多自然和社会现象,包括股票价格、物质粒子的运动等。
随机漫步模型的基本形式:
随机漫步模型的基本形式可以这样描述:
- 开始:从一个初始点或初始值开始。
- 步骤:在每个时刻,下一步的值是当前值加上一些随机变动。这个变动通常来自某个概率分布,如正态分布。
- 路径:通过不断重复这些随机步骤,产生一条随机路径。
数学上,随机漫步可以用以下公式表示:
其中,是在时间
的值,
是从某个概率分布(如正态分布)抽取的随机误差项。
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以便重现结果
np.random.seed(42)
# 模拟参数
n_steps = 200
initial_price = 100
volatility = 0.01 # 波动性或步长
# 随机漫步模拟
prices = [initial_price]
for _ in range(n_steps):
price_change = np.random.normal(0, volatility) # 高斯噪声
prices.append(prices[-1] + prices[-1] * price_change)
# 预测未来一步
future_step = prices[-1] + prices[-1] * np.random.normal(0, volatility)
prices.append(future_step)
plt.plot(prices)
plt.title('Stock Price Simulation Using Random Walk')
plt.xlabel('Time')
plt.ylabel('Price')
plt.show()
print(f"Predicted price for the next step: {future_step}")
长期预测时要考虑机理分析,此时统计回归方法效果差
灰色预测
灰色预测是一种用于处理不完全、不准确和不确定信息的预测方法。
灰色预测中最常用的方法是灰色GM(1,1)模型。下面是该模型的基本步骤:
-
收集和准备数据:灰色预测可以用于小样本数据的分析,甚至在只有几个数据点的情况下也可以进行预测。
-
一次累加生成(1-AGO):将原始数据转换为累加序列,以消除数据的随机波动。
-
建立灰色微分方程:通过一次累加序列,建立灰色微分方程,并估计模型参数。
-
预测:使用建立的灰色微分方程进行预测,并将预测结果转换回原始数据的尺度。
-
模型检验:通过一些统计方法,例如残差分析,来验证模型的精度和可靠性。
灰色预测的主要优势在于它的简单性和灵活性。由于它不依赖于复杂的统计分布假设和大量的样本数据,因此特别适用于信息不完全或数据稀缺的情况。
例子
使用灰色GM(1,1)模型来预测一个时间序列数据。假设我们有一组产品销售数据,并想预测未来的销售趋势。
import numpy as np
import matplotlib.pyplot as plt
# 定义原始数据
data = np.array([100, 120, 130, 150, 180, 210])
# 一次累加生成(1-AGO)
data_ago = np.cumsum(data)
# 计算紧邻均值生成序列
Z = (data_ago[:-1] + data_ago[1:]) / 2.0
# 建立GM(1,1)模型
B = np.column_stack([-Z, np.ones(Z.shape)])
Yn = data[1:].reshape((data[1:].shape[0], 1))
a_hat = np.linalg.lstsq(B, Yn, rcond=None)[0]
# 微分方程参数
a, b = a_hat
# 恢复预测值
def predict(k):
return (data[0] - b/a) * np.exp(-a * k) + b/a
# 预测未来的销售数据
forecast = [predict(k) for k in range(len(data) + 3)] # 预测3个额外的点
# 绘图
plt.plot(data, label="Original data", marker="o")
plt.plot(forecast, label="Forecast", linestyle="--", marker="x")
plt.xlabel("Time")
plt.ylabel("Sales")
plt.legend()
plt.show()
灰色预测模型GM(1,1)的效果并不总是理想,尤其是在某些情况下,如数据趋势变化复杂、非线性或季节性波动显著等情况。在这种情况下,灰色预测可能不是最合适的方法。
该模型的一个关键优势是它可以在数据不完整或信息稀缺的情况下工作,但这可能导致预测准确性的降低。此外,GM(1,1)模型是一种线性模型,因此可能无法捕捉更复杂的非线性趋势。
函数拟合
函数拟合是一种通过找到最佳逼近函数来描述数据集中的底层关系的过程。在预测场景中,函数拟合的主要目的是找到一个可以描述现有数据的数学函数,然后使用该函数来预测未来的值。
例子
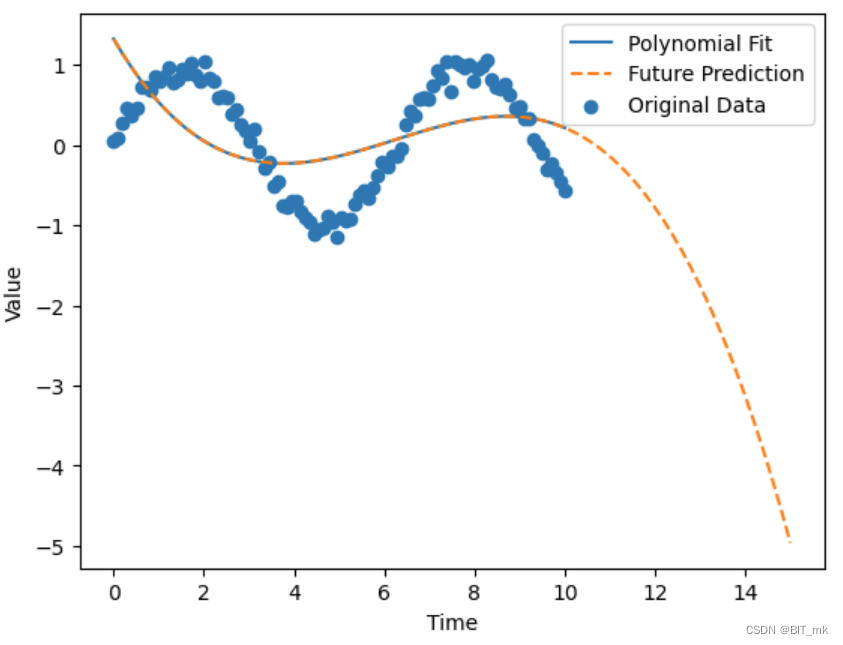
假设我们有一组与时间相关的数据,并且观察到其中的非线性趋势。我们将使用多项式回归来拟合这些数据。
import numpy as np
import matplotlib.pyplot as plt
from numpy.polynomial.polynomial import Polynomial
# 生成模拟数据
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = np.sin(X) + np.random.normal(0, 0.1, 100) # 正弦波加上噪声
# 拟合3阶多项式
polynomial_model = Polynomial.fit(X, y, 3)
# 预测
y_fit = polynomial_model(X)
X_future = np.linspace(0, 15, 150) # 扩展到未来
y_future = polynomial_model(X_future)
# 绘制原始数据和拟合曲线
plt.scatter(X, y, label='Original Data')
plt.plot(X, y_fit, label='Polynomial Fit')
plt.plot(X_future, y_future, label='Future Prediction', linestyle='--')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
插值方法
插值方法用于在已知数据点集合之间找到未知值。在预测中,插值可以用来估计已知数据点之间的值,但不常用于外推超出已知范围的未来值。
例子
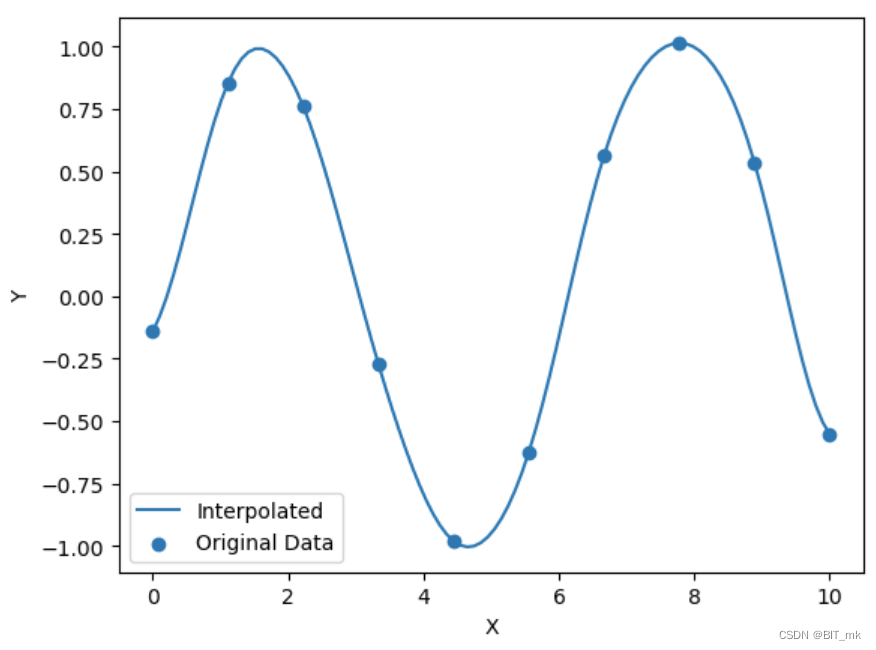
import numpy as np
from scipy.interpolate import Rbf
import matplotlib.pyplot as plt
# 创建模拟数据
x = np.linspace(0, 10, 10)
y = np.sin(x) + np.random.normal(0, 0.1, 10)
x_new = np.linspace(0, 10, 100)
# 使用RBF插值
rbf_interpolator = Rbf(x, y, function='gaussian')
y_new = rbf_interpolator(x_new)
# 绘图
plt.scatter(x, y, label='Original Data')
plt.plot(x_new, y_new, label='Interpolated')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()
拟合和插值的区别
插值和拟合是两种用于构建数据点之间关系的方法,但它们的目的和方式存在一些关键区别:
-
目的:
- 插值:旨在找到一个精确穿过所有给定数据点的函数。在已知数据点之间,插值方法能够准确重现这些点。
- 拟合:旨在找到一个近似描述给定数据点的整体趋势的函数。它可能不会穿过所有的数据点,而是试图捕捉整体趋势或模式。
-
灵活性与稳健性:
- 插值:由于插值方法必须穿过所有已知点,所以它对噪声和异常值非常敏感。这可能会导致在数据点之间的振荡和不稳定。
- 拟合:拟合方法允许一些偏差,并且更能抵抗噪声和异常值的影响。它更关注捕捉整体趋势,而不是精确复现每个点。
-
用途:
- 插值:通常用于估计已知数据范围内的未知值,不适用于外推或预测超出已知范围的未来值。
- 拟合:可以用于预测和外推,包括已知数据范围之外的值。拟合通常与回归分析、预测建模等相关联。
-
选择的函数类型:
- 插值:插值方法,如多项式插值或样条插值,通常有固定的形式,并且必须满足穿过所有数据点的约束。
- 拟合:拟合方法可以是线性的、非线性的或任何可以描述数据整体趋势的模型。例如,线性回归、多项式回归、逻辑回归等。
总体而言,插值关注的是重现已知数据点,而拟合关注的是捕捉整体趋势或模式。插值可能更适用于数据完整、噪声低的情况,而拟合可能更适用于存在噪声或更关注整体趋势的情况。
评价
相关分析、主成分分析(先来找出主要的指标)
相关性分析主要用于分析和衡量变量之间的线性关系,为特征选择、风险管理等提供依据。
主成分分析则是一种强大的降维工具,可以用于数据可视化、特征降维、噪声过滤和关系识别。
例子
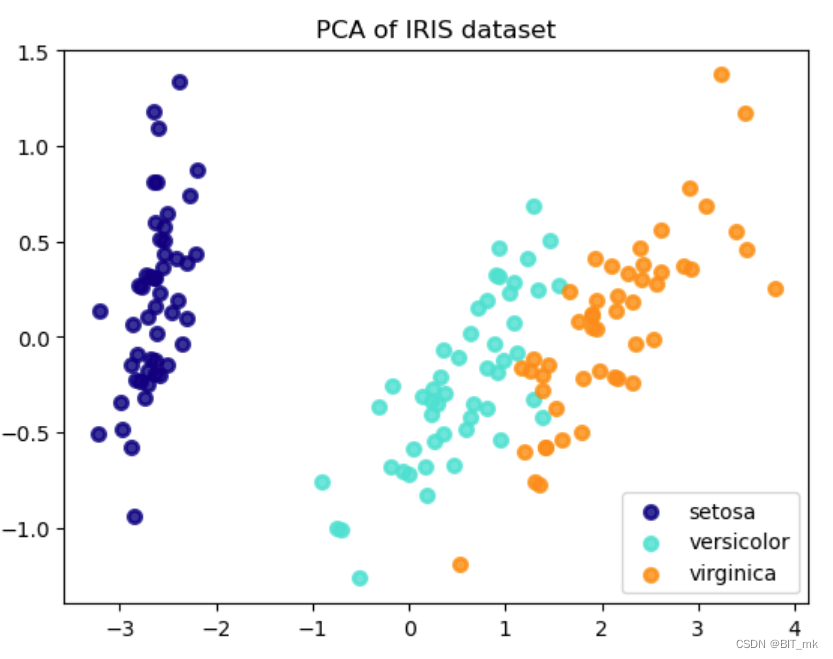
假设我们有一个具有多个特征的数据集,例如Iris数据集,我们想通过PCA降低其维度并可视化结果。
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 执行PCA并保留2个主成分
pca = PCA(n_components=2)
X_r = pca.fit_transform(X)
# 可视化PCA结果
plt.figure()
colors = ['navy', 'turquoise', 'darkorange']
lw = 2
for color, i, target_name in zip(colors, [0, 1, 2], iris.target_names):
plt.scatter(X_r[y == i, 0], X_r[y == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('PCA of IRIS dataset')
plt.show()
层次分析
层次分析是一种有效且灵活的评价方法,能够处理多准则和主观判断的复杂情况。通过组织问题结构、进行成对比较、计算权重和进行一致性检验,AHP提供了一种全面的方式来评估和对比不同的备选方案,并支持更明智和均衡的决策。
例子
假设我们想要选择最佳智能手机,考虑三个标准:性能、相机和价格。我们有三个手机选项:手机A、手机B和手机C。
import numpy as np
def ahp(matrix):
n = matrix.shape[0]
eigenvalues, eigenvectors = np.linalg.eig(matrix)
max_eigenvalue = max(eigenvalues)
eigenvector = eigenvectors[:, eigenvalues.argmax()]
eigenvector = eigenvector / eigenvector.sum()
return eigenvector.real
# 创建标准层成对比较矩阵
criteria_matrix = np.array([
[1, 2, 0.5],
[0.5, 1, 0.25],
[2, 4, 1]
])
# 创建选项层成对比较矩阵
options_matrices = [
np.array([
[1, 0.5, 2],
[2, 1, 4],
[0.5, 0.25, 1]
]),
np.array([
[1, 2, 0.5],
[0.5, 1, 0.25],
[2, 4, 1]
]),
np.array([
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]
])
]
# 计算标准层权重
criteria_weights = ahp(criteria_matrix)
# 计算每个选项的总分
final_scores = np.zeros(3)
for i, matrix in enumerate(options_matrices):
options_weights = ahp(matrix)
final_scores += options_weights * criteria_weights[i]
# 输出结果
options = ["手机A", "手机B", "手机C"]
for option, score in zip(options, final_scores):
print(f"{option}: {score}")

熵权法
熵权法是一种多属性决策分析方法,用于确定各个评价指标的权重。它基于信息熵的概念来量化各个评价指标的混乱程度或信息含量。信息熵越高,表示该指标的变化越大,不确定性越高,因此应给予较低的权重。反之,信息熵越低,表示该指标的变化较小,信息量较大,因此应给予较高的权重。
import numpy as np
def entropy_weight(data):
# 归一化数据
P = data / data.sum(axis=0)
# 计算每个指标的信息熵
E = np.nan_to_num(-(P * np.log(P)).sum(axis=0))
# 计算冗余度
d = 1 - E / np.log(data.shape[0])
# 计算权重
weights = d / d.sum()
return weights
# 示例数据,每一列代表一个评价指标,每一行代表一个评价对象
data = np.array([
[300, 60, 5],
[400, 50, 3],
[100, 80, 4]
])
# 计算权重
weights = entropy_weight(data)
# 输出结果
print("权重:", weights)
![]()
模糊综合评价法
在传统逻辑中,一个陈述要么是真(1)要么是假(0)。而在模糊逻辑中,真值可以是介于0和1之间的任何实数,代表了事物属于某个集合的程度。例如,对于“这个苹果是红色的”这一陈述,在模糊逻辑中,真值可以是0.8,表示这个苹果是红色的程度为0.8。
在模糊综合评价法中,模糊性的概念用于处理不确定或模棱两可的评价信息。通过将评价指标的量化结果转换为模糊数量,可以捕捉和描述这些信息的模糊特性。例如,可以用模糊数量来描述一个产品的质量,如“质量非常好”、“质量较好”等,这些描述可以映射到具体的模糊隶属度,如0.9、0.7等。
例子
import numpy as np
# 权重向量
weights = np.array([0.4, 0.3, 0.3])
# 模糊评价矩阵(每一列代表一个评价指标,每一行代表一个模糊评价等级)
fuzzy_evaluation_matrix = np.array([
[0.1, 0.6, 0.3],
[0.7, 0.3, 0.4],
[0.2, 0.1, 0.3]
])
# 模糊综合评价
fuzzy_comprehensive_evaluation = weights.dot(fuzzy_evaluation_matrix)
# 输出结果
print("模糊综合评价向量:", fuzzy_comprehensive_evaluation)
![]()
TOPSIS方法
TOPSIS(Technique for Order Preference by Similarity to Ideal Solution)是一种决策支持和评价类任务中常用的多属性决策分析方法。该方法通过比较每个备选方案与理想解和负理想解的相似度来对方案进行排序和评价。
可以将其比喻为一个赛跑比赛场景:
- 理想解:终点线,所有选手的目标。
- 负理想解:起点线,所有选手的起始位置。
- 距离计算:每个选手距离终点和起点的距离。
- 相对接近度:表示选手离终点的接近程度,越接近终点(理想解)的选手,其成绩越好。
例子
import numpy as np
def topsis(decision_matrix, weights, beneficial_criteria):
# 标准化决策矩阵
standardized_matrix = decision_matrix / np.sqrt((decision_matrix**2).sum(axis=0))
# 构建加权标准化决策矩阵
weighted_matrix = standardized_matrix * weights
# 确定理想解和负理想解
ideal_solution = np.where(beneficial_criteria, weighted_matrix.max(axis=0), weighted_matrix.min(axis=0))
negative_ideal_solution = np.where(beneficial_criteria, weighted_matrix.min(axis=0), weighted_matrix.max(axis=0))
# 计算距离
d_positive = np.sqrt(((weighted_matrix - ideal_solution) ** 2).sum(axis=1))
d_negative = np.sqrt(((weighted_matrix - negative_ideal_solution) ** 2).sum(axis=1))
# 计算相对接近度
closeness = d_negative / (d_positive + d_negative)
return closeness
# 示例决策矩阵
decision_matrix = np.array([
[7, 9, 9],
[8, 7, 8],
[9, 6, 8]
])
# 权重
weights = np.array([0.3, 0.5, 0.2])
# 有益性标准(指标越大越好则为True,反之为False)
beneficial_criteria = [True, True, True]
# 执行TOPSIS
result = topsis(decision_matrix, weights, beneficial_criteria)
# 输出结果
print("相对接近度:", result)
![]()
秩和比方法
秩和比(Rank Sum Ratio,简称RSR)方法是一种多属性决策分析方法,适用于评价类任务。它主要通过对每个方案的各属性进行排序,然后使用秩的和来计算比值,从而实现对方案的评价和排序。
例子
import pandas as pd
# 创建数据框
data = {'选手': ['A', 'B', 'C'],
'项目1': [90, 80, 70],
'项目2': [5, 6, 4]}
df = pd.DataFrame(data)
# 对项目1进行秩排序(越高越好)
df['项目1秩'] = df['项目1'].rank(ascending=False)
# 对项目2进行秩排序(越低越好)
df['项目2秩'] = df['项目2'].rank()
# 计算秩和
df['秩和'] = df['项目1秩'] + df['项目2秩']
# 计算秩和比
total_rank_sum = df['秩和'].sum()
df['秩和比'] = df['秩和'] / total_rank_sum
# 打印结果
print(df)

数据包络分析
数据包络分析(Data Envelopment Analysis,简称DEA)是一种线性规划方法,用于评估多个具有相似特性的决策单元(Decision Making Units,DMUs)的效率。在评价任务中,它常用于衡量组织或单位在使用给定输入产生输出的效率。
DEA的基本思想是通过构建一条最优的“包络”面,将所有决策单元的效率进行评价。它考虑了多个输入和输出,而不仅是一个单一的效率比率。
形象化解释:
-
决策单元(DMUs):想象有几家不同的餐馆(DMUs)。每家餐馆都使用相同的输入(例如原材料和员工),但产出(例如销售额)可能不同。
-
效率前沿:在一个图表上,你可以将每家餐馆作为点来绘制,其中x轴表示输入,y轴表示输出。最有效的餐馆将定义一个“效率前沿”——想象它是一个弯曲的线,紧贴那些最有效的点。
-
效率和无效率的餐馆:在效率前沿上的餐馆是最有效的,因为它们使用给定的输入产生了最多的输出。不在前沿上的点则不是最有效的。
-
投影和改进方向:对于不在效率前沿上的餐馆,你可以找到最近的效率前沿点,这个点就是一个“目标”或“基准”。你可以将它想象成一个虚拟餐馆,如果现有餐馆改进,就可以达到这个效率水平。
-
多个输入和输出:虽然我们使用了一个二维图来解释,但DEA能够处理多个输入和输出。你可以将这想象成一个多维空间,其中效率前沿是一个多维的表面。
-
包络:效率前沿的形状就像一个包围着所有餐馆的“包络”,因此得名“数据包络分析”。
-
灵活性:通过选择不同的模型,这个包络可以有不同的形状,以反映不同的假设(例如,是否有规模经济效益)。
DEA就像一位“效率侦探”,可以帮你找出在多个方面都表现得很好的餐馆,并找出那些不太有效的餐馆可以改进的方向。
包络面的图示
from sklearn.linear_model import LinearRegression
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
import matplotlib.pyplot as plt
# 示例输入和输出数据
inputs1 = np.array([4, 8, 6, 3, 7])
inputs2 = np.array([3, 6, 4, 2, 5])
outputs = np.array([10, 15, 12, 6, 13])
# 重新整理输入数据
inputs = np.vstack((inputs1, inputs2)).T
# 创建并拟合模型
model = LinearRegression()
model.fit(inputs, outputs)
# 创建输入的范围来画出效率前沿
x_range = np.linspace(min(inputs1), max(inputs1), 100)
y_range = np.linspace(min(inputs2), max(inputs2), 100)
x_mesh, y_mesh = np.meshgrid(x_range, y_range)
# 使用模型预测输出
z_mesh = model.predict(np.c_[x_mesh.ravel(), y_mesh.ravel()])
z_mesh = z_mesh.reshape(x_mesh.shape)
# 创建三维图形
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 绘制效率前沿表面
surf = ax.plot_surface(x_mesh, y_mesh, z_mesh, alpha=0.5, rstride=10, cstride=10, cmap='viridis')
fig.colorbar(surf, ax=ax, shrink=0.5, aspect=10)
# 将点画在图上
ax.scatter(inputs1, inputs2, outputs, c='r', s=50, marker='o')
ax.set_xlabel('Input 1')
ax.set_ylabel('Input 2')
ax.set_zlabel('Output')
# 设置视角
ax.view_init(elev=14, azim=20)
plt.show()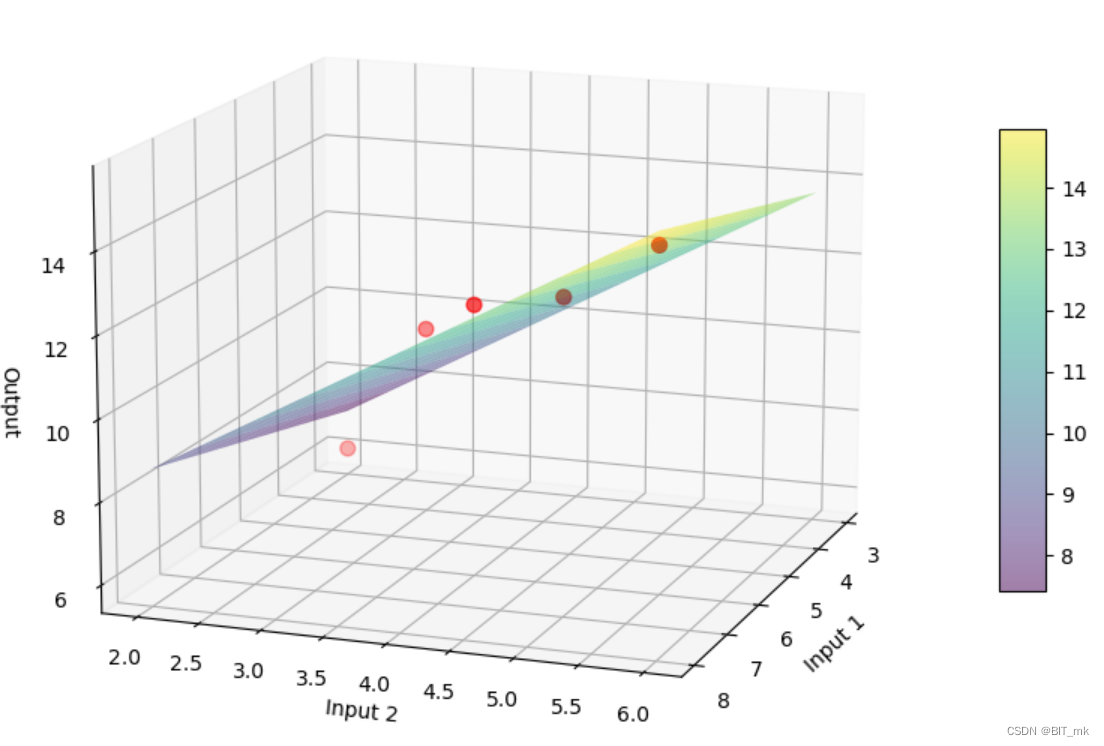
决策
运筹学
随机规划与模糊规划
随机规划:
随机规划是考虑不确定性或随机性的优化方法。在许多实际决策问题中,某些参数可能是不确定的或随机的。例如,未来需求、股票价格、汇率等。
模糊规划:
模糊规划则是当某些参数是模糊或不精确的时候的优化方法。这些模糊性可能来源于测量错误、主观判断或语言描述的不精确性。
随机性是可以通过概率来精确描述的不确定性,而模糊性则涉及到因缺乏明确信息或语言不精确而产生的不确定性。在决策和规划过程中,这两种类型的不确定性可能需要不同的数学工具和方法来处理。
模糊规划例子
假设你是一个销售人员,要确定产品的售价,以最大化利润。你知道更高的价格会降低需求量,但你对需求的价格弹性不确定,可以用模糊数来描述。
import numpy as np
from scipy.optimize import minimize
# 定义成本
cost_per_unit = 50
# 定义模糊需求函数
def fuzzy_demand(price):
# 需求可能是模糊的,这里使用三个不同的需求曲线
demand_scenarios = [1000 - 5 * price, 800 - 3 * price, 600 - 2 * price]
return demand_scenarios
# 定义模糊利润函数
def fuzzy_profit(price):
# 计算三种情况下的利润
profits = [d * (price - cost_per_unit) for d in fuzzy_demand(price)]
# 返回最小利润,以保守估计
return -min(profits)
# 设置售价边界
price_bounds = (cost_per_unit, 2 * cost_per_unit)
# 优化模糊利润函数
result = minimize(fuzzy_profit, x0=[cost_per_unit + 10], bounds=[price_bounds])
# 打印最优售价和对应的模糊利润
optimal_price = result.x[0]
print(f"Optimal Price: ${optimal_price:.2f}")
print(f"Fuzzy Profits: {[-fuzzy_profit(optimal_price) for _ in range(3)]}")

在这个例子中,模糊性体现在需求对价格的响应上。需求的不确定性被描述为三个可能的需求曲线,分别反映了不同的价格弹性。通过考虑这三个需求曲线,模糊利润函数返回这三种情况下利润的最小值,作为保守的估计。
差分/微分方程
最优控制理论
最优控制理论是一种数学方法,用于寻找可以控制系统状态的最优解。在决策过程中,它用于确定在给定约束和性能标准下使某一特定准则最小化或最大化的控制策略。
最优控制理论的主要组成部分包括:
- 状态方程:描述系统动态的方程。
- 控制变量:可以调整的参数。
- 性能指标:一个与状态和控制变量相关的标量函数,用于衡量系统性能。
- 约束条件:可能的实际限制,如物理、经济或技术限制。
例子
我们考虑一个简单的一维运动问题,目标是将一辆小车从起始位置移动到目标位置,同时最小化时间和能量消耗。
from scipy.optimize import minimize
import numpy as np
# 参数
start_position = 0
end_position = 10
mass = 1
time_step = 0.1
total_steps = 100
# 目标函数: 最小化时间和能量消耗
def objective(control):
position = start_position
velocity = 0
total_energy = 0
for u in control:
acceleration = u / mass
velocity += acceleration * time_step
position += velocity * time_step
total_energy += np.abs(u) * time_step
# 添加对目标位置的惩罚
return total_energy + 1000 * (position - end_position) ** 2
# 约束条件: 确保速度和加速度在合理范围内
bounds = [(-1, 1)] * total_steps
initial_guess = [0] * total_steps
# 优化
result = minimize(objective, initial_guess, bounds=bounds)
# 打印结果
if result.success:
print("Optimal control found!")
else:
print("Optimal control not found:", result.message)
![]()















 2207
2207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









