






 本文介绍了ViLT和ALBEF等简化版的视觉语言模型,强调了去除目标检测的必要性,以及这些模型在objectivefunction、架构优化和数据增强上的特点。文章还探讨了融合策略和网络结构的改进,如Mixture-of-Modality-Experts和统一理解与生成任务的处理。
本文介绍了ViLT和ALBEF等简化版的视觉语言模型,强调了去除目标检测的必要性,以及这些模型在objectivefunction、架构优化和数据增强上的特点。文章还探讨了融合策略和网络结构的改进,如Mixture-of-Modality-Experts和统一理解与生成任务的处理。
本文大部分内容是根据up主bryanyzhu讲解的小笔记,用于记录自己的学习,会有一些漏记误记的地方,请各位大佬在阅读的时候及时指正。
VLP模型普遍采用的Objective Function
ITC Loss
Image Text Contrastive。对比学习损失,正样本之间的距离越来越近,正负样本之间的距离越来越远。
ITM Loss
Image Text Matching。图文匹配任务,二分类任务,一般需要利用ITC loss采用Hard Negative策略得到负样本来训练。
MLM Loss
Mask Language Modeling。完形填空任务,如BERT采用。
LM Loss
Language Modeling。与MLM区别在于,LM给定前半句,然后续写后半句。
ViLT(64张32G卡训练3天)
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision (arxiv.org)
Motivation
把目标检测移除多模态视觉端。
Objective Function
ITM、MLM。
Contribution
①The simplest architecture by far,在运行时间(significant runtime)和参数量(parameter efficient)方面强大。
②尽管结构简单,但性能依旧不错。
③采用数据增强策略。a.文本,whole word masking;b.图像,randAugment,但是不采用color和cutout,是因为这两种策略可能会导致和文本不匹配。
传统VLP架构和本文网络架构对比
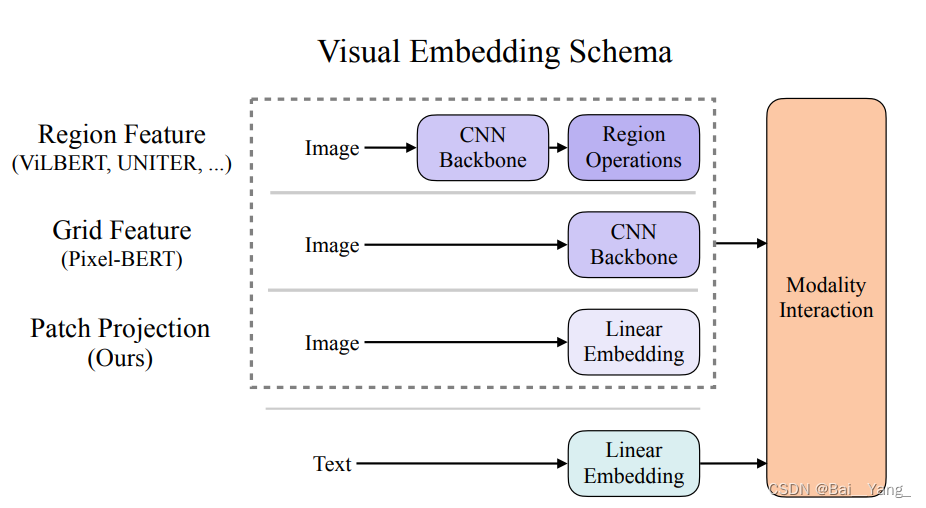
①之前的Region/Grid Feature在提取时很耗时,对于多模态任务来说,模态之间的融合才是关键。
②如果采用预选练好的模型提取特征,模型的表达能力受限。(如预训练好的模型中只有若干类别)
作者提出极简化的model
①文本:采用transformer,在2017年以来,transformer“一统江湖”,后面基本采用这种方法。
②图像:要把像素转为语义,而之前的方法都基于目标检测。受vit启发,把图像打成patch,用Linear Projection层把patch变成Embedding。
文中提到的一些背景知识
①一种分类VLP的方法:a.文本、图像的表达力度是否平衡,依据参数量和计算量来评判;b.融合策略。
②一种分类融合策略的方法:a.single-stream,即图像、文本输入后进行concat;b.dual-stream,图像、文本先各自处理,然后融合。
③抽取特征:a.文本,pre-trained BERT;b.图像,i.backbone(如ResNet101)→抽roi→NMS→ROI head,ii.Grid Feature,iii.用一层Patch Projection抽特征(本文)。
ALBEF(单机8卡训练3天)
代码:
https://github.com/salesforce/ALBEF
论文:
Motivation
①图像端的模型大于文本端,融合部分的模型也需要尽可能大,可能会有更好的效果。
②ViLT训练时间太久。
Objective Function
ITC、ITM、MLM。
Contribution
①Align Before Fuse,即不用已经训练好的目标检测器,因为这可能不与文本匹配,使用Contrastive Loss,即ITC,这也是CLIP采用的loss。
②Momentum Distillation,是self-training的,生成一些伪标签,用于解决noisy web data问题。
Network Architecture
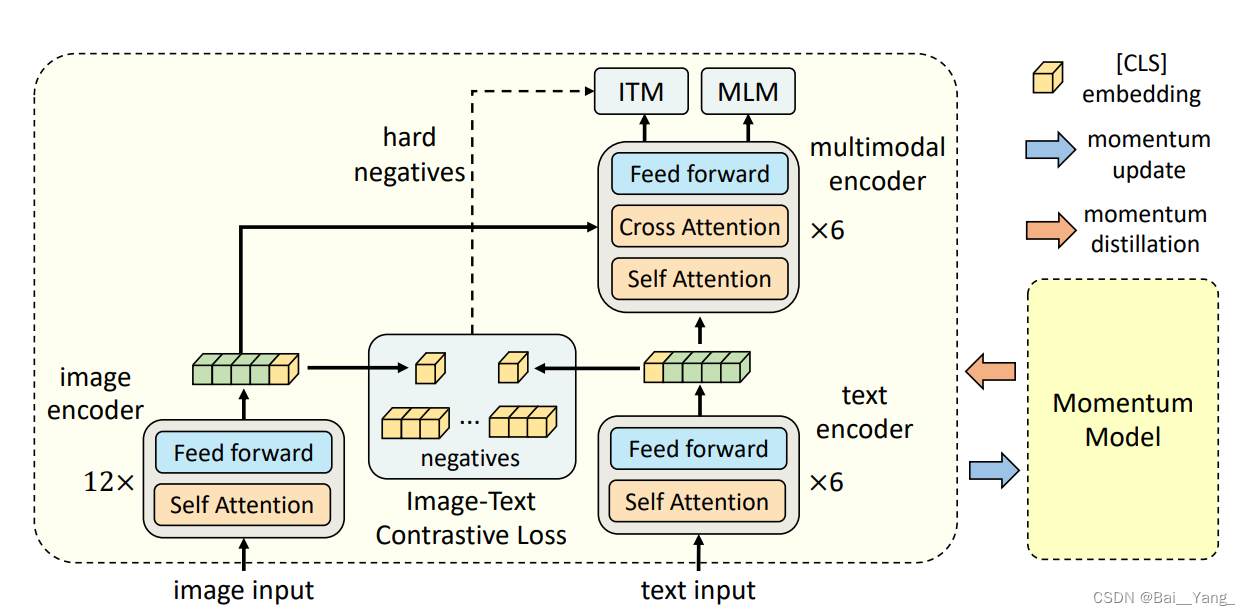
从网络架构可看到,图像部分image encoder(12层)确实比文本部分text encoder(6层)大,融合部分multimodal encoder(6层)也较大,与CLIP等方法不同,此处不是简单的点乘。
VLMo(64张卡2天)
Motivation
主流的模型结构有:
①dual-encoder,即双塔结构,在交互时采用Cosine Similarity,如CLIP、ALIGN等,优点是针对检索任务好用、速度快,缺点是无法做难的任务,如VR、VE、VQA等。
②a fusion encoder,即单塔结构,文本、图像先分开处理,然后用Transformer Encoder做模态交互。
那么能否对二者进行融合呢?
Objective Function
ITC、ITM、MLM。
Contribution
①Mixture-of-Modality-Experts。
②分阶段的模型预训练。
Network Architecture

从图中可以看到,在预训练时,先训练图像vision experts;接下来训练文本language experts,注意,此时将Multi-Head Self-Attention冻住了;然后在多模态数据做pre-training。
BLIP
代码:
论文:
以下三段借鉴了哔站用户“壁橱里的小男孩”的笔记。
本文可以认为是吸收了VLMo思想的ALBEF,训练的loss和技巧和ALBEF类似,是ALBEF的后续工作。关键的改进:
1. 模型结构上整合了 ALBEF 和和 VLMo。VLMo 参数共享,但是不存在单独编码器;ALBEF 存在单独编码器但是部分参数不共享。这篇论文存在单独的 vision encoder 和 text encoder。多模态的参数是以 cross-attention 模块插入到文本编码器实现的,cross-attention 模块享受文本编码器的参数。
2. 增加了解码器,为了做生成任务。解码器拿到视觉特征和未掩码的语言特征,过一个 casual self-attention 层,做 GPT 用的 LM Loss 任务。这里区别于 MLM 的那种 mask 机制,是通过 causal self-attention 来实现因果推理的。
Motivation
①模型角度,encoder-based model不适用于Image captioning任务,即生成任务;encoder-decoder-based model不适用于Image-Text retrieval任务。
②数据角度,训练数据有噪声noise,如果数据集足够大,可以弥补这个噪声,但是不是最优解。作者提出Captioner(Cap)和Filter(Filter),分别用于生成字幕和过滤。
Objective Function
ITC、ITM、LM。
Contribution
①Booststrapping,先用网上数据训练,然后生成一些干净的数据继续训练。
②Unified Understanding and Generation,做了一个统一工作,同时完成两个任务。
Network Architecture
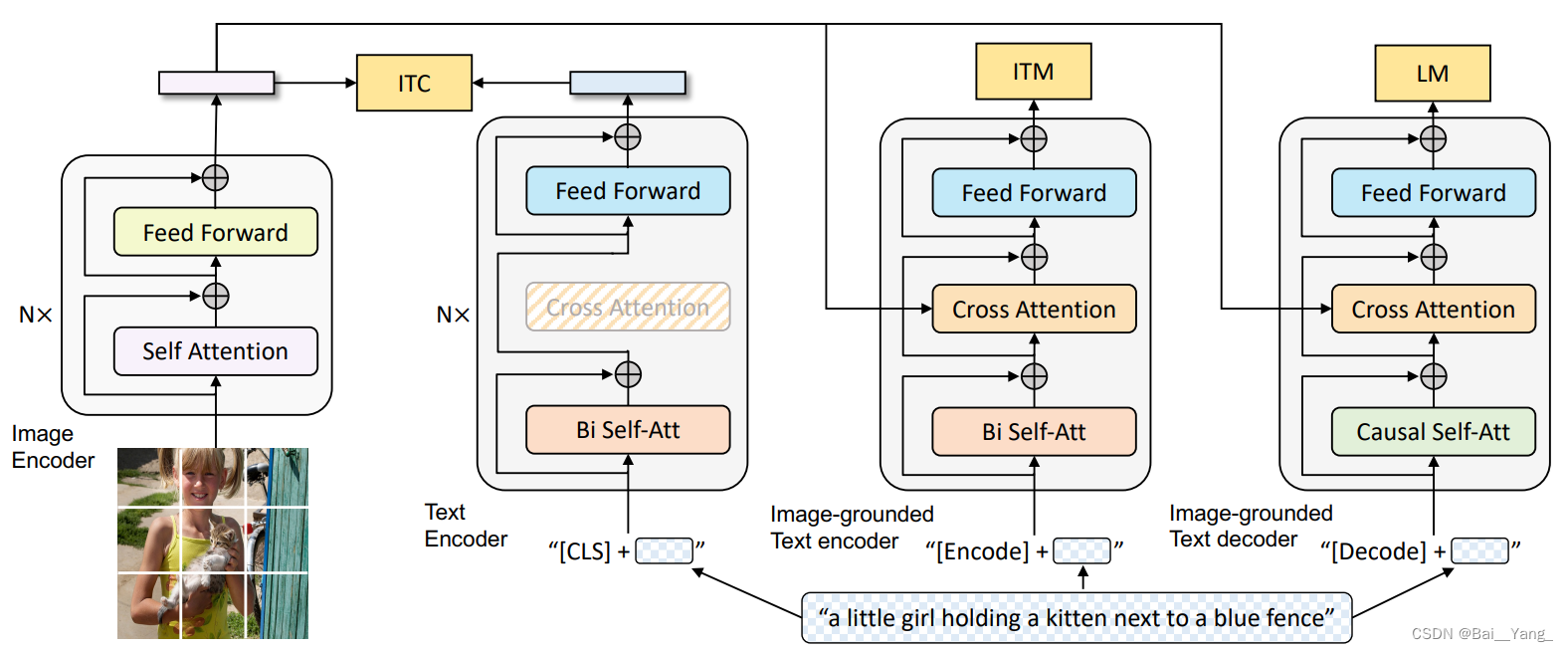
Cap Filt Model
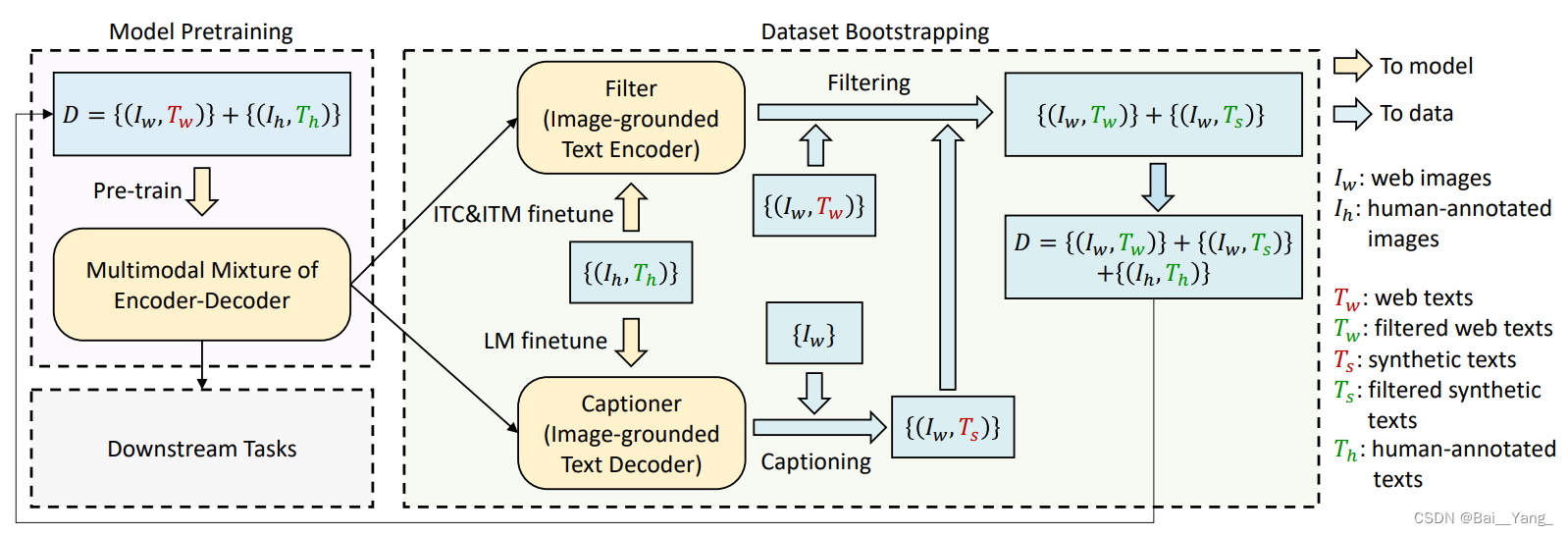
由于网络中的数据集可能不是很好,是noisy的,这个模块用于解决noisy web data的问题。
图中左侧MED模块(Multimodal Mixture of Encoder-Decoder)已经训练好,在Coco数据集上做过滤(Filter);用MED的Decoder生成的文本,充当新的数据集,并进行过滤。以上两种过滤得到的图像重新参与训练MED,不断迭代。
BLIP2
借鉴了BLIP-2:使用冻结图像编码器和大型语言模型的语言-图像预训练 - 知乎 (zhihu.com)
Motivation
目前都是大模型、大数据量的预训练,得到了很好的效果,但是很耗时,能否通过冻结的方式进行训练?
Network Architecture
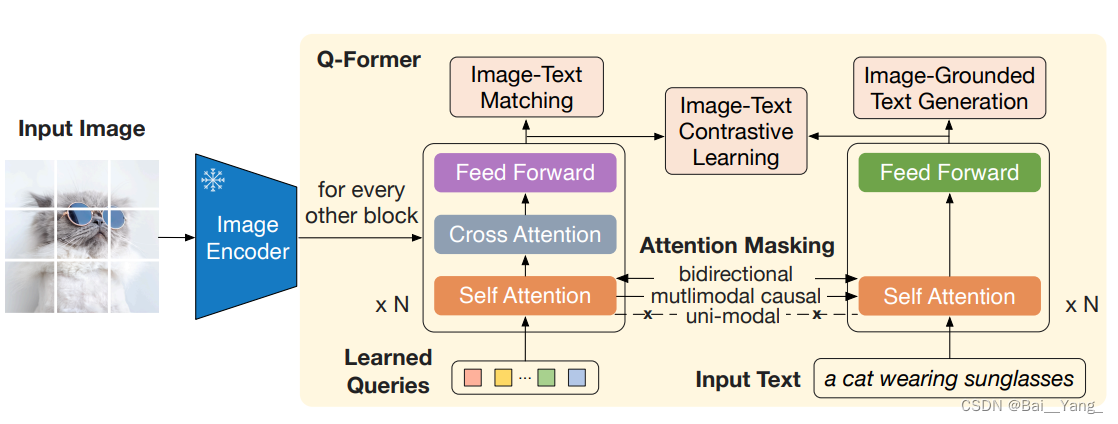
BLIP-2通过一个轻量级的查询Transformer弥补了模态之间的差距,该Transformer分两个阶段进行预训练。第一阶段从冻结图像编码器引导视觉语言表示学习。第二阶段将视觉从冻结的语言模型引导到语言生成学习。

















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









