







多变量线性回归
n变量的线性回归估计函数
n个变量的线性回归估计函数为 h(X)=k0+k1x1+k2x2+….+knxn
每个训练样本的n个变量构成一个n维向量X,为方便,在第一个位置添加一个x0=1,(与常数项k0相乘),这样就构成了一个n+1维向量。
同时k0~kn这个n+1个参数构成了另一个n+1维向量K。
那么估计函数就等于 K的转置*X
评价函数
多变量线性回归中,对于不同的参数向量K,同样有一个评价函数,形如:
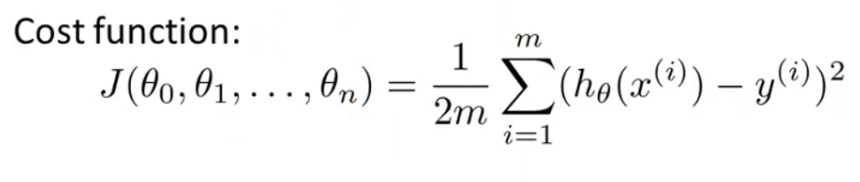
同样对于每个ki,先求出它的偏导数,再一直像相反方向移动,直到到达一个极小值点。
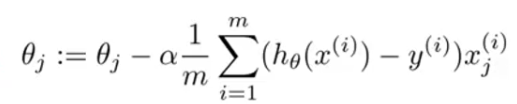
feature scaling(数据规范化)
由于对于所有变量迭代时的步长(a)是一样的,当两个变量的取值范围相差较大时,迭代会产生误差,所以最好将所有变量的取值范围变成接近 ( -1 , 1 )。
方法是:
xi = ( xi - ui ) / si
ui是变量xi在训练集中的平均数,si是xi在训练集中的最大值-最小值。
这样做完后使得数据的均值是0,方差是1。
si可以用标准差代替(Octave 函数std()) ,效果更好,避免了边界的一个点对整体造成巨大影响。
验证gradient descent(梯度下降)正确性的方法:
画一张图,横坐标是迭代次数,纵坐标是估价函数的值J(K),曲线应是下降的,而且趋近于一条直线。
如果曲线出现了上升部分,可以尝试将步长a变小。
normal equation(正规方程)
梯度下降外的另一种回归方法。
要求的是Θ,使得X*Θ=Y
step1:先把θ左边的矩阵变成一个方阵。通过乘以XT可以实现,则有
XTX · θ = XTY
step2:把θ左边的部分变成一个单位矩阵,这样就可以让它消失于无形了……
(XTX)-1(XTX) · θ = (XTX)-1XTY
所以θ = (XTX)-1XTY。
normal equation中X是不需要做数据规范化的。
和梯度下降的区别:
1.不需要迭代。
2.需要计算矩阵的逆,当n很大时这一步非常慢(O(n3)的时间复杂度),通常n<1000时会考虑使用normal quation。















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









