






《Citation-Enhanced Generation for LLM-based Chatbots》ACL 论文阅读
论文链接:[2402.16063] Citation-Enhanced Generation for LLM-based Chatbots
1. 主要内容(不是论文中引言部分)
这篇论文提出了一种名为Citation-Enhanced Generation (CEG)的后处理方法,用于减少基于LLM的聊天机器人生成内容中的幻觉(hallucination)问题。幻觉问题指的是模型生成的回答中可能包含不真实或错误的信息。CEG框架通过结合检索增强和自然语言推理(NLI)技术,在生成内容后对其进行验证,并为每个生成的声明添加引用。如果发现生成的声明缺乏支持,模型会重新生成回答,直到所有声明都有引用支持。该方法是一个无需额外训练的即插即用插件,适用于各种LLM。
实验设计
-
数据集:实验使用了四个与幻觉相关的数据集:WikiBio GPT-3、FELM、HaluEval和WikiRetr。这些数据集分别用于评估幻觉检测和回答再生能力。
-
模型:实验主要基于GPT-3.5和GPT-4模型,并使用不同的检索模型(如SimCSE BERT、Sentence BERT等)来验证检索增强模块的效果。
-
模块:
-
检索增强模块:在生成回答后,检索与生成内容相关的文档。
-
引用生成模块:使用NLI技术评估生成的声明是否与检索到的文档一致。
-
回答再生模块:如果发现生成的声明有误,模型会基于检索到的文档重新生成回答。
-
-
评估指标:实验使用了AUC-PR、平衡准确率(Balanced Accuracy)等指标来评估模型在幻觉检测和回答再生任务中的表现。
实验结论
-
幻觉检测:CEG框架在WikiBio GPT-3和FELM数据集上的幻觉检测任务中表现优异,显著优于现有的最先进方法。
-
回答再生:在HaluEval数据集上,CEG框架在回答再生任务中也取得了最佳性能,尤其是在使用GPT-3.5-Turbo-Instruct时,准确率达到了69.45%。
-
模块有效性:通过消融实验,验证了检索增强模块和引用生成模块的有效性,表明这些模块对减少幻觉问题有显著贡献。
2. 相关工作
2.1 LLM中的幻觉控制
生成式AI取得了显著进展,但仍然面临幻觉问题。现有的策略可以分为两大类:训练时缓解和推理时缓解。对于第一类,LLM(如LLaMA2)通过使用高质量数据源进行广泛的训练周期,以增强预训练中的事实一致性。有人 在指令微调过程中缓解幻觉问题,采用高质量的人工标注内容来调节幻觉。一些研究还引入了对非事实性回答的惩罚,以在RLHF中减少幻觉。然而,所有这些方法都需要额外的训练和标注。
另一方面,研究人员尝试在推理时处理幻觉问题。推理时干预通过在推理过程中沿事实相关方向调整模型激活来缓解幻觉。检索增强生成(RAG)通过在生成前检索可靠文档来缓解幻觉。然而,这些方法由于缺乏生成后的验证,仍然会产生幻觉,并且无法提供引用来进行验证。
2.2 引用增强的LLM
在LLM领域,检索技术已成为关键组成部分,因为它提供了相关知识以生成更可靠的结果,同时也减少了幻觉的发生。先前的研究指出,由检索模型生成的引用是构建负责任和可问责的LLM的关键。
现有的引用增强策略可以分为两类:参数化方法和非参数化方法。参数化方法指的是从训练数据中内部化的信息,通常会导致不准确的标注文档,因为标注过程本身可能会引发幻觉。非参数化方法涉及从外部语料库中查询相关信息并无缝整合检索到的内容,从而提供更可靠的引用。因此,大多数先前的研究都是非参数化的,但它们是基于预生成的方式。例如,Gao et al. (2023a) 采用检索过程来促进模型生成输出中的文档标注。然而,它们的预生成标注策略无意中将问答任务的复杂性提升为生成回答和同时标注的双重挑战。与现有的引用增强研究不同,文章提出了一种不同的策略,利用检索模型以后处理的方式生成引用。
3. 方法
CEG框架的三个核心模块:
- 检索增强模块:生成回答后,检索与生成内容相关的文档,确保每个声明都有支持。
- 引用生成模块:使用NLI技术评估生成的声明是否与检索到的文档一致,并为每个声明生成引用。
- 回答再生模块:若发现生成的声明有误,模型会基于检索到的文档重新生成回答。
3.1 概述
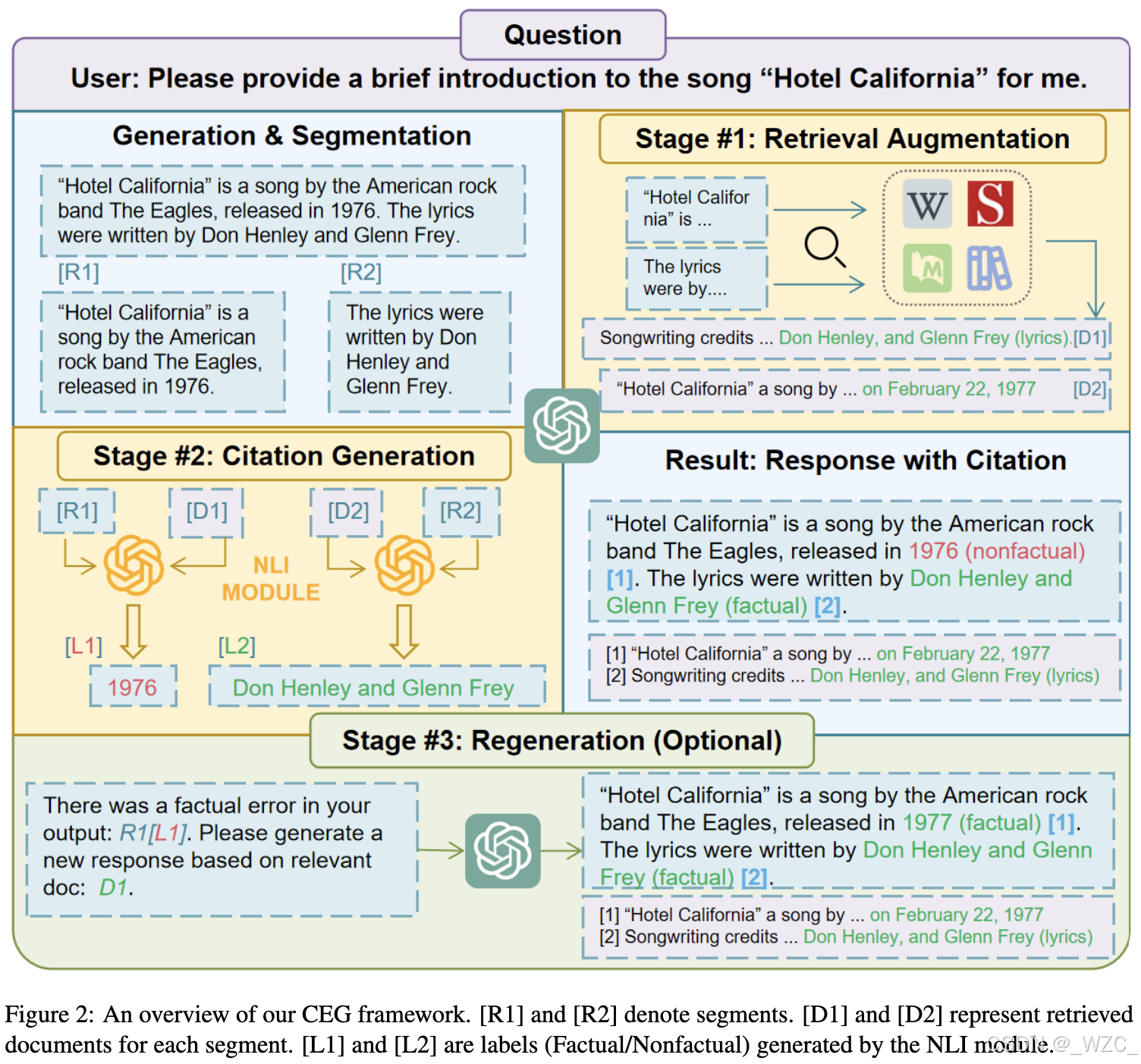
如图2所示,CEG框架包含几个关键模块:
-
检索增强模块:该模块用于搜索与原始回答R相关的文档 Dj。如果回答过长,可以将其分解为多个子声明R={R1,R2,...,Rn}。
-
引用生成模块:该模块评估检索到的文档Dj是否支持回答中的声明{Ri}。
-
回答再生模块:该模块负责生成一个新的提示,该提示结合了原始用户查询和检索到的关键信息,以便LLM生成更可靠的回答R′。
注意,CEG是一个后处理框架,并且高度适用于不同的LLM,因为它不需要任何额外的训练或微调。因此,作者在这里没有指定特定的LLM。
3.2 检索增强模块
检索增强的目标是在生成回答前检索文档作为证据(问题作为查询),文章提出在生成后以后处理的方式进行检索增强,以验证生成的声明Ri的正确性(声明作为查询)。由于已有多种关于如何检索最相关文档的研究,作者使用了一种简单但有效的密集检索策略来验证CEG框架的性能。
查询:对于回答R,如果需要,可以将其分割为多个声明,得到 R={R1,R2,...,Rn}。在这里,使用NLTK句子分词器进行启发式分割。NLTK句子分词器是一种性能良好且广泛使用的分词器,在大多数情况下能够正确分割文本。将R分割为符合用户阅读习惯的合理声明Ri,然后逐个将 Ri作为查询。
语料库(候选文档):主要关注基于知识的问答领域,使用了2023年10月20日的维基百科快照,将其分割为大约100字的候选文档,每个文档以句号或换行符分隔。注意,可将其替换为任何其他语料库,这里使用它是因为大多数幻觉基准数据集都基于维基百科。
检索器:近年来,基于密集向量的检索技术展示了强大的性能,并且广泛用于现有的RAG模型中。采用了SimCSE BERT作为查询和文档编码器。候选文档根据以下公式计算的余弦相似度得分进行排序:
其中e()是SimCSE BERT编码器,dj是语料库中的候选文档。由于更多的文档需要在后续模块中进行更多的计算,因此选择前k个相似度较高的文档形成参考文档集Di。添加了一个额外的阈值t来过滤掉余弦相似度较低的检索文档。除了前1个文档外,如果 Sim(Ri,dj)<t,则 dj不会包含在 Di 中。这些文档随后被连接起来,形成最终的检索内容Di以供进一步计算。
3.3 引用生成模块
在为每个回答片段Ri获取参考文档Di后,下一步是生成标签和引用来验证Ri的正确性。提出采用NLI方法来确定每个声明-文档对(Ri,Di)之间的关系。一般来说,这种关系可以分为三种类型:支持、独立和矛盾。但在幻觉相关场景中,为了遵循之前的研究,这里只使用两种类别:(1)事实性,即Di作为Ri的参考,从而支持该声明。(2)非事实性,即Di提出了与Ri相反的声明。
NLI(自然语言推理)是自然语言处理中的一项任务,旨在判断两个句子之间的逻辑关系(如蕴含、矛盾、中立)。
在CEG框架中,NLI模型用于评估生成的声明是否与检索到的文档一致。
尽管许多模型能够执行NLI方法,但CEG框架希望充分利用LLM的语言理解能力。因此,更倾向于使用带有预定义提示(predefined prompt)的LLM来执行NLI方法。
当LLM输出为“事实性”时,文档Di被识别为声明Ri的有效参考。因此,可以将此引用添加到原始回答中。如果检索到的前k个文档中没有支持声明Ri的文档,或者有文档反对该声明,这里将此声明标记为非事实性(潜在的幻觉),以提醒用户仔细阅读。基于这两个模块,可以检测回答中是否存在幻觉。
3.4 回答再生模块
在前面的模块中,CEG提供了一种后处理的方法来进行引用增强的验证,可靠的回答会被添加引用。进而,提出了一个回答再生模块来解决潜在的幻觉问题。假设LLM生成了原始回答R,CEG框架将提供一个新提示用于再生。该提示不仅包含原始查询,还结合了检索到的文档和标注的非事实性片段。
在收到再生回答后,可以启动一个新的引用增强生成过程。如果回答被判定为没有事实性错误,它将成为最终回答并展示给用户。然而,如果新的回答仍然包含幻觉,再生循环将重复进行。为了节省API资源并减少等待时间,可以设置一个预定义的参数T来限制最大再生尝试次数。
4. 实验设置(为了方便分析,加一些5.实验结果)
| 实验目的 | 数据集 | 基线方法 | 评估指标 | 实验重点 |
|---|---|---|---|---|
| 评估幻觉检测能力 只用CEG框架中的前两个模块 | WikiBio GPT-3 | HalluDetector、Focus、SelfCheckGPT(w/BERTScore、w/NLI、w/Prompt) | AUC-PR、平衡准确率(Balanced Accuracy) | 验证CEG框架在检测生成文本中幻觉(非事实性声明)的能力,对比不同预检索和后处理方法的性能差异。 |
| 多场景幻觉检测 只用CEG框架中的前两个模块 | FELM | Vicuna-33B、ChatGPT、GPT-4的普通提示(Vanilla)、CoT、带参考文档的提示(Link、Doc) | 非事实性准确率、事实性准确率、平衡准确率 | 测试CEG在不同LLM(如ChatGPT、GPT-4)上的通用性,验证细粒度文档利用的有效性。 |
| 评估回答再生能力 用CEG的完整框架 | HaluEval | Vanilla、CoT、Pre-Retrieval(基于All-mpnet-base-v2检索器) | 准确率(选择正确答案 vs. 幻觉答案) | 验证CEG在检测到幻觉后,通过结合检索文档重新生成回答的能力。 |
| 分析检索与引用生成 | WikiRetr | SimCSE BERT、Sentence BERT、All-mpnet-base-v2 | Recall@k(原始文档是否在Top-k中)、Precision@k(声明是否被Top-k文档支持) | 验证不同检索模型在后处理任务中的性能,评估NLI模型(如True-9B、GPT系列)在引用生成中的准确性。 |
4.1 概述
为了验证CEG框架的有效性,在实验中采用了四个与幻觉相关的数据集:WikiBio GPT-3、FELM、HaluEval和WikiRetr。WikiBio GPT-3和FELM是幻觉检测基准数据集,HaluEval是幻觉生成基准数据集。此外,作者构建了一个新的数据集WikiRetr,用于评估检索和引用标注的性能。
使用GPT模型作为LLM的骨干,不同数据集中使用的版本不同,以便与现有基线进行公平比较。除非另有说明,“ChatGPT”指的是GPT-3.5-Turbo-1106,“GPT-4”指的是GPT-4-0613。这里将解码温度设置为0,以确保LLM生成的回答具有可重复性。所有提示列在附录A中,更多数据集信息见附录B。
4.2 WikiBio GPT-3 数据集(评估幻觉)
WikiBio GPT-3数据集用于评估LLM的幻觉问题。研究人员从WikiBio数据集中随机选择了238篇传记文章,并使用text-davinci-003生成新的段落。这些段落被分割为1,908个句子,然后手动标注为三类:主要不准确、次要不准确和准确。根据之前的研究,主要不准确和次要不准确被归类为非事实性(可能存在幻觉,1,392个片段),准确被归类为事实性(516个片段)。
基线:
-
HalluDetector:利用外部知识源、特定分类模型和朴素贝叶斯分类器来检测幻觉。
-
Focus:采用多阶段决策过程,结合预检索和任务特定分类器。
-
SelfCheckGPT:使用了三个变体:w/BERTScore、w/Prompt和w/NLI。SelfCheckGPT w/BERTScore基于LLM的内在不确定性,而SelfCheckGPT w/Prompt和w/NLI则依赖于外部知识源。
评估指标为精确率-召回率曲线下面积(AUC-PR)和平衡准确率(Balanced Accuracy)。
4.3 FELM 数据集(评估幻觉)
FELM数据集用于评估幻觉检测能力。研究人员从不同场景中收集了提示,并使用GPT-3.5-Turbo-0301生成回答。这些回答被手动标注为非事实性和事实性,并附有支持文档。实验在FELM的WorldKnowledge子集上进行,因为该子集基于维基百科语料库。
基线:根据FELM的设置,采用了四种策略,分别以ChatGPT、GPT-4和Vicuna-33B为骨干LLM:
-
Vanilla prompts:普通提示。
-
Prompts augmented with Chain-of-Thought (CoT) reasoning:带有链式思维推理的提示。
-
Prompts augmented with hyperlinks to reference documents:带有参考文档超链接的提示。
-
Prompts augmented with human-annotated reference documents:带有手动标注参考文档的提示。
实验在单个回答级别进行。根据之前的工作,选择了非事实性、事实性和平衡准确率作为最终评估指标,以便与之前的工作进行比较。
4.4 HaluEval 数据集(评估识别幻觉能力,特别是问答任务)
HaluEval数据集用于评估LLM识别幻觉的能力。每个实例包含一个问题、一个正确答案和一个幻觉答案(多个答案由ChatGPT自动生成,并选择最令人困惑的一个)。我们采用了HaluEval的QA子集,因为它基于维基百科语料库,并从中随机抽取了2,000个样本。
基线:采用了基于更新版ChatGPT的几种模型
-
Vanilla prompts:普通提示。
-
Prompts augmented with CoT reasoning:带有链式思维推理的提示。
-
Prompts with Pre-RAG:使用了一个强大的微调检索器All-mpnet-base-v2。
评估指标为准确率。

4.5 WikiRetr 数据集(评估CEG框架的检索和引用标注能力)
WikiRetr数据集旨在进一步分析CEG框架,它基于2023年10月20日的维基百科快照构建。随机选择了1,000个段落,并分别使用text-davinci-003和GPT-4将其重写为新的声明。因此,每个重写的声明都附有一个原始段落。构建的数据集分别命名为WikiRetr-GPT3和WikiRetr-GPT4。关于WikiRetr数据集可靠性的讨论见附录D。
为了分析检索模块,使用了多种检索器,包括:
-
SimCSE BERT:CEG框架中使用。
-
Sentence BERT:使用孪生网络训练的检索器。
-
All-mpnet-base-v2。
评估指标为Recall@k(原始文档是否在前k个检索结果中)和Precision@k(声明是否被前k个文档中的某个文档支持,使用NLI方法)。
对于引用生成模块中的NLI方法,从每个数据集中随机选择100个实例进行评估。进行了手动标注,以评估原始段落是否支持重写的声明。标注结果显示,90%和94%的生成声明得到了原始段落的支持,这是NLI模型的Ground Truth。然后,使用1)True-9B模型和2)GPT模型作为NLI方法进行分析。选择手动标注与模型标注之间的一致性作为评估指标。
提出True的论文简介为:TRUE是一个用于评估文本生成模型生成内容的事实一致性的标准化框架,涵盖了多个任务和数据集,并提供了一种统一的评估方法。比较了12种不同的事实一致性评估方法,发现基于自然语言推理(NLI)和问题生成与回答(QG-QA)的方法在多个任务和数据集上表现最好,且这两种方法具有互补性。
5. 实验结果和分析
5.1 幻觉检测的性能
| 实验目的 | 数据集 | 基线方法 | 评估指标 | 实验重点 | 实验结果 | CEG是否优于基线 |
|---|---|---|---|---|---|---|
| 评估幻觉检测能力 只用CEG框架中的前两个模块 | WikiBio GPT-3 | HalluDetector、Focus、SelfCheckGPT(w/BERTScore、w/NLI、w/Prompt) | AUC-PR、 平衡准确率(Balanced Accuracy) | 验证CEG框架在检测生成文本中幻觉(非事实性声明)的能力。 | CEG的平衡准确率(77.59%)和事实性AUC-PR(70.24%)均最优,非事实性AUC-PR(92.31%)仅次于SelfCheckGPT w/NLI(92.50%)。 | 是(综合最优) |
| 多场景幻觉检测 只用CEG框架中的前两个模块 | FELM | Vicuna-33B、ChatGPT、GPT-4的普通提示(Vanilla)、CoT、带参考文档的提示(Link、Doc) | 非事实性准确率、事实性准确率、平衡准确率 | 测试CEG在不同LLM上的通用性。 | 使用GPT-4时,CEG的平衡准确率(69.9%)最优;使用ChatGPT时,CEG(59.7%)优于所有ChatGPT基线。 | 是 |
为了验证CEG方法的有效性,在WikiBio GPT-3和FELM数据集上使用了检索增强和引用生成模块进行幻觉检测。
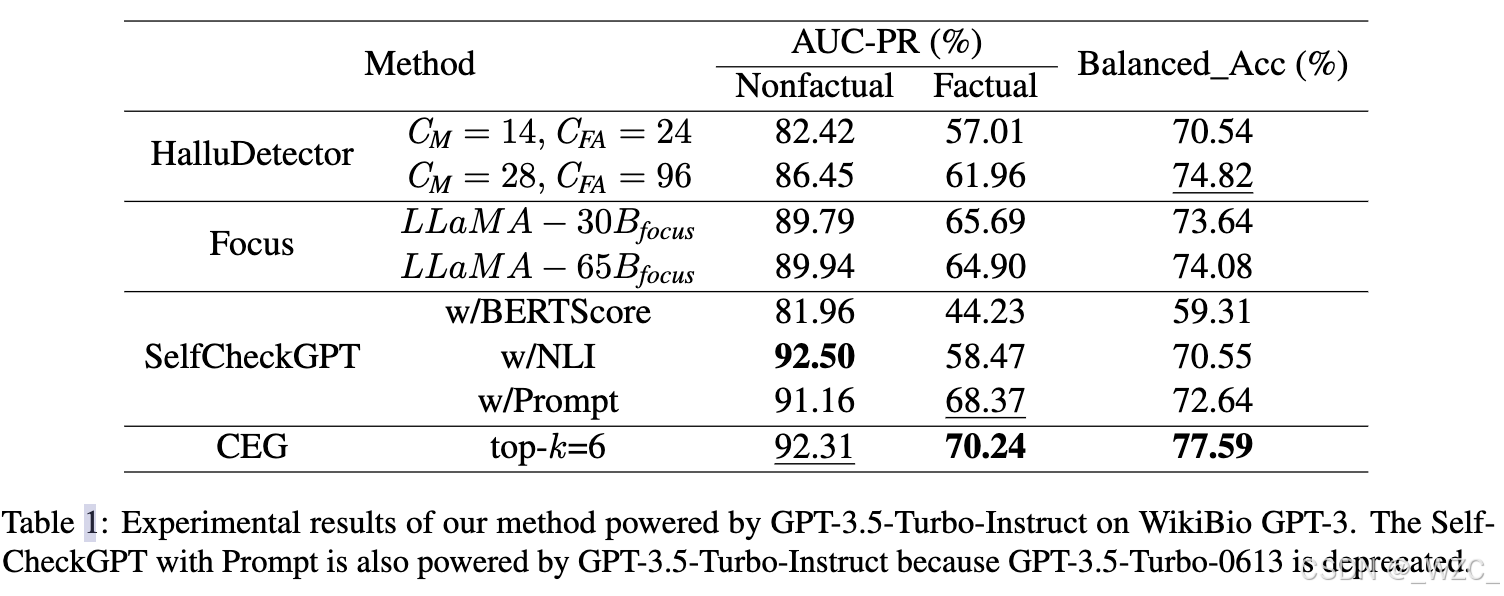
在WikiBio GPT-3数据集上的整体性能如表1所示,观察如下:
-
CEG框架在平衡准确率和事实性片段的AUC-PR上优于所有基线方法,在非事实性片段的AUC-PR上表现第二。这些结果表明了CEG方法的强大。
-
之前的预检索增强生成模型,如SelfCheckGPT w/NLI和w/Prompt,在AUC-PR上也表现良好。但由于处理长文本的困难,它们无法在所有指标上达到与CEG模型相当的性能。
-
CEG模型在非事实性片段的AUC-PR上略低于w/NLI,原因可能是SelfCheckGPT的NLI模块经过了额外的训练来检测非事实性片段。
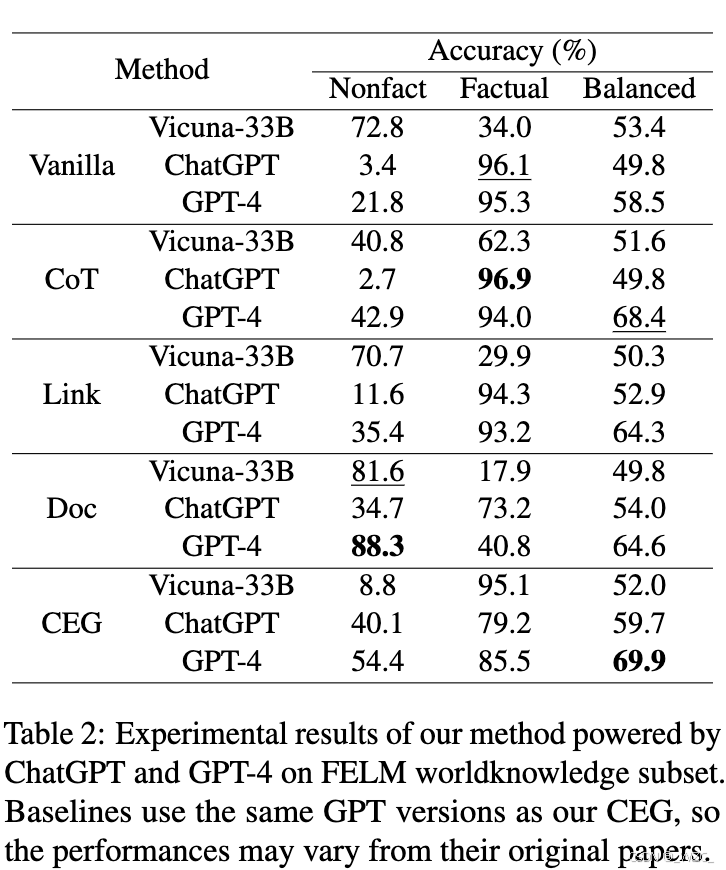
FELM数据集的实验结果总结在表2中。
- 首先,CEG模型在使用GPT-4时达到了平衡准确率的最佳结果。大多数基线模型在分类单一类型时存在偏差。
- 其次,使用ChatGPT的CEG优于其他ChatGPT基线,展示了CEG模型的灵活性。
- 第三,CEG优于所有预检索基线,展示了所提出的后处理片段级检索模块在幻觉检测中的强大能力。
- 最后,对于Vicuna-33B,所有方法相比普通方法都有一定程度的下降(比较Vicuna-33B的Balanced指标,发现采用普通提示Vanilla的值为53.4,为所有中最高值),表明其在通用能力和使用检索文档方面的局限性。然而,CEG方法下降幅度最小,尤其是与手动标注的Doc基线相比,CEG方法优于其2.2个百分点,证明了更细粒度文档利用的有效性。
总结来说,CEG在两个基准数据集上优于各种最先进的基线模型,表明后处理检索与NLI在幻觉检测中具有强大的能力。
5.2 幻觉再生的结果
| 实验目的 | 数据集 | 基线方法 | 评估指标 | 实验重点 | 实验结果 | CEG是否优于基线 |
|---|---|---|---|---|---|---|
| 评估回答再生能力 采用完整的CEG框架 | HaluEval | Vanilla、CoT、Pre-Retrieval(基于All-mpnet-base-v2检索器) | 准确率(选择正确答案 vs. 幻觉答案) | 验证CEG在检测到幻觉后重新生成回答的能力。 | CEG的准确率(69.45%)显著优于预检索策略(61.35%)和CoT(68.55%),提升最高达8.1%。 | 是 |
在HaluEval数据集上,采用了完整的CEG框架来进一步评估再生模块。如果文档有助于解决问题且任何回答片段被分类为非事实性,CEG方法将生成一个新的提示进行再生,如第3.4节所述。此外,由于该数据集与之前的语料库不一致,文章采用了2018年的维基百科快照作为语料库。
实验结果如表3所示。首先,CEG框架在使用GPT-3.5-Turbo-Instruct时达到了最佳性能(准确率为69.45%),相比预检索策略提高了8.10%。使用ChatGPT的CEG也优于预检索策略,因此这些结果表明文章的后处理方法具有鲁棒性。其次,预检索策略甚至比带有CoT的基线表现更差,这表明检索到的文档并不总是有帮助的。第三,与文章在表5中与NLI模型相关的实验一致,当使用GPT-3.5-Turbo-Instruct作为NLI模型时,结果优于ChatGPT。同时还进行了案例研究来展示再生结果,部分案例见附录C。
5.3 进一步分析(分析各个模块是否都有效)
| 子章节 | 实验重点 | 数据集使用方式 | 基线方法 | 评估指标 | 关键结果 |
|---|---|---|---|---|---|
| 5.3.2 检索模型 | 比较不同检索模型在后处理任务中的性能 | 使用WikiRetr-GPT3和WikiRetr-GPT4,评估检索模型能否正确召回原始文档。 | SimCSE BERT、Sentence BERT、All-mpnet-base-v2 | Recall@k、Precision@k | SimCSE BERT在Top-10时Recall@10=76.8%(WikiRetr-GPT3),优于其他检索模型。 |
| 5.3.3 引用生成中的NLI模型 | 验证不同NLI模型在引用生成中的准确性 | 使用WikiRetr数据集,手动标注生成声明与原始文档的支持关系,对比模型标注与人工标注的一致性。 | True-9B、GPT系列(如GPT-3.5、GPT-4) | 一致性(Agreement Rate) | GPT-4在WikiRetr-GPT4上的标注一致性达96%,显著优于True-9B(84%)。 |
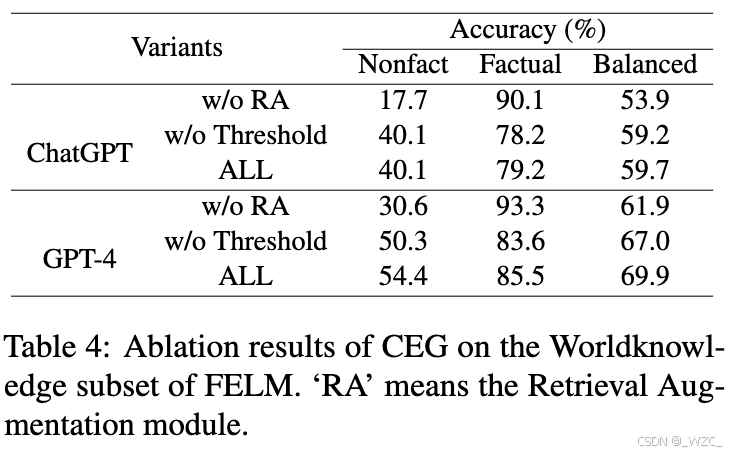
5.3.1 消融实验(without检索模型 效果不好)
在FELM Worldknowledge数据集上进行了消融实验,其中检索增强(k=4)和文档选择阈值(阈值=0.5)被涉及。如表4所示,检索增强模块在不同骨干LLM(ChatGPT和GPT-4)上提供了更好的结果。此外,检索文档的阈值是必要的,它可以过滤掉引用生成中的不相关文档。因此,所有设计的模块都对CEG框架的改进有贡献。
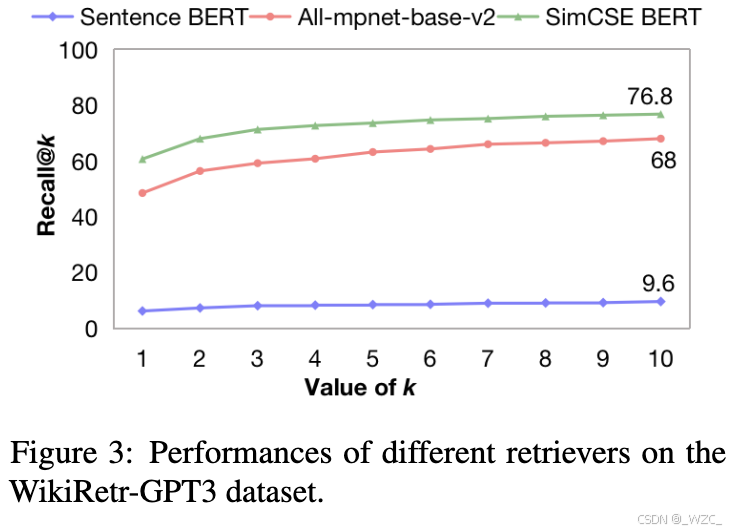
5.3.2 检索模型(不同检索模型的选择)
检索模型的选择显著影响了检索增强模块的性能,如图3所示。三种不同检索模型的实验结果表明,SimCSE BERT在后处理检索任务中表现更好(使用前10个文档时为76.8%),其中使用了6400万个文档作为候选。此外,尽管更大的k值可以提高召回率,但它也需要更多的资源进行进一步计算。为了在效率和效果之间取得平衡,在实验中设置了k值在4到6之间。
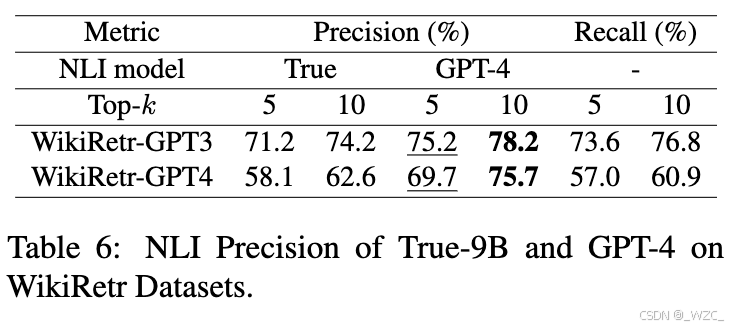
5.3.3 引用生成中的NLI模型(引用生成模块)
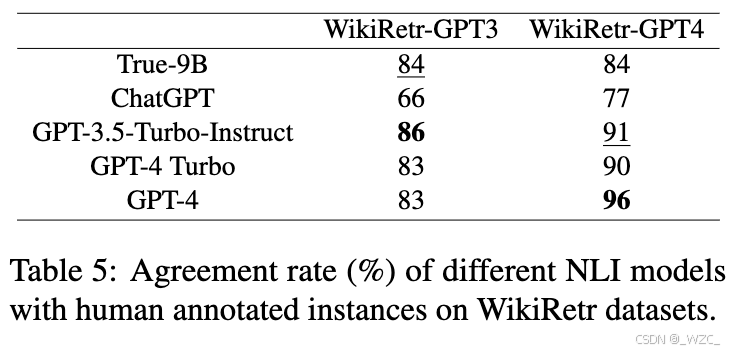
不同NLI模型在引用生成模块中的性能如表5所示,有以下两个主要观察:
-
尽管True-9B是最先进的特定任务NLI方法,但在此场景中表现不如最佳LLM。LLM(如GPT-3.5-Turbo-Instruct和GPT-4)能够在CEG的引用生成模块中扮演NLI模型,因为它们与人类标注者达到了高度一致。
-
LLM在它们生成的数据上表现更好,这与之前的研究一致。
表6展示了当检索器为Simcse BERT时,不同NLI模型在引用生成模块中的实验结果,表明:
-
即使在超过6400万个候选文档的语料库上,CEG引用生成模块也表现出色,在两个数据集上的精度分别达到了78.2和75.7。
-
与WikiRetr-GPT3相比,WikiRetr-GPT4构成了一个更具挑战性和更高质量的数据集。原因是WikiRetr-GPT4的召回率较低,表明原始文本与生成声明之间的语义相似性较低。然而,其精度超过了召回率,表明生成的声明质量较高。
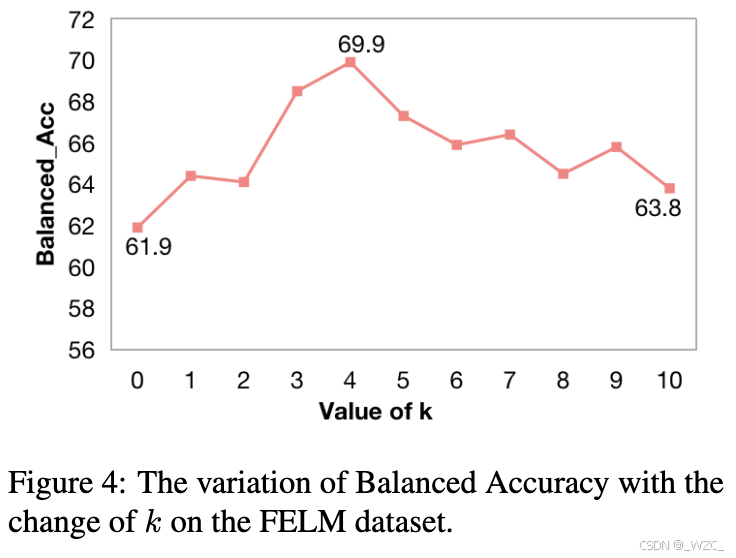
5.3.4 超参数分析
由于篇幅限制,仅在FELM数据集上展示了k的超参数分析,如图4所示。有以下观察:
-
在FELM和WikiBio GPT-3数据集上的实验结果表明,更多的文档(更大的k值)并不总是提供更好的性能。原因可能是更多的文档导致输入变长,注意力分散,同时检索文档的相关性降低。
-
较少或没有检索文档也会导致性能下降,这表明检索增强模块在CEG中的有用性。
-
当k接近5时(FELM数据集为Top-4,WikiBio GPT-3数据集为Top-6),达到了最佳性能。
6. 结论
本研究提出了一种新颖的后处理引用增强生成框架,以减少LLMs中的幻觉问题。该框架结合了检索增强和自然语言推理(NLI)技术。与之前的幻觉研究不同,CEG框架是后处理的,并且具有灵活性,可以应用于不同的LLM,而无需额外的训练或标注,具有重要的实际意义。在三个与幻觉相关的基准数据集和坐着构建的数据集上的实验表明,CEG框架在幻觉检测和再生任务中达到了最先进的性能。进一步的分析展示了坐着提出的模块和采用模型的有效性。未来,坐着计划进一步扩展语料库以支持更多场景。
局限性
研究有几个局限性:
-
受限于检索器与语料库:实验中未使用针对后处理任务优化的专用检索器,且仅依赖维基百科语料库,限制了框架在通用知识问答场景外的适用性。
-
实验验证范围:实验基于现有基准数据集和人工标注,未提出新的问答数据集以全面验证再生性能。
-
NLI模块的依赖:引用生成模块依赖LLM自身的世界知识,若LLM对检索文档的理解存在偏差,可能影响标注准确性。
-
API成本:使用商业LLM(如GPT-4)生成引用和再生回答会产生较高的API调用成本。

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









