







前言
写人机交互论文的时候,难免需要进行用户实验,以及对用户实验数据进行分析。这个过程中用到了多种显著性差异数据统计方法和问卷调查方法,对于初学者来说,十分麻烦与琐碎。而这块内容,国内国外的可参考资料都很少,故记录下个人的实验过程,以帮助后来者。
简介
个人一开始在阅读论文时,常常能看到作者对志愿者的实验数据使用了 ANOVA 或 Friedman 等方法进行显著性差异分析,然后又用 bonferroni 、 wilcoxcon 以及 t检验 等方法进行两两校正比等。其中,光是ANOVA方法就涉及到很多变种,如:单因素ANOVA,双因素ANOVA,重复测量ANOVA(repeated-measures ANOVA),双因素重复测量ANOVA(two-way repeated-measures ANOVA)等等。
那什么是显著性差异分析?什么是两两校正?怎么挑选最合适的ANOVA分析方法?又为什么要进行这些操作呢?
除此之外,论文里分析得到的结果中,各种带 F, W, Z, p 参数的公式又有什么用?
如ANOVA分析结果:
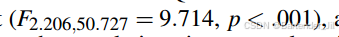
或者Friedman检验结果:

亦或是Wilcoxon sign - ranks结果:
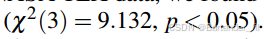
这里面的字母和数字对没接触过这个领域的人实在难以理解。
故在本篇文章中,笔者将介绍常见的显著性差异分析技术和事后比较技术(ANOVA、Friedman、Bonferroni、wilcoxcon等)的作用、人机交互常用的调查问卷(NASA-TLX、UEQ-S、SUS、Borg)计算方法、以及面对 非正态分布数据 如何进行处理以方便分析。
使用工具
数据分析所使用到的工具:Excel、SPSS数据分析工具。
SPSS数据分析工具我推荐以下两个:
SPSSPRO网站 :能免费分析一百行数据,操作简单,但功能不如SPSS软件齐全。
Windows SPSS软件 :收费,但网上有一些教程使其免费(你懂的)。功能齐全,但其操作稍微复杂一些(如果能耐心跟着网上视频学习的话也不难)。
大部分分析方法都可以通过 SPSSPRO网站 完成,但是对于多重比较以及two-way repeated-measures ANOVA等涉及多因素的技术建议还是用Windows SPSS软件 方便点。
一、实验背景
为了更好地理解整个计算过程,我们以一个简单的任务为例。
1.1 任务场景
在虚拟现实环境VR中,用户通常是用手柄射线来选择场景中远处的目标物体。如下图所示,用户通过按下手柄按钮,便可发射射线来获取到远处的绿色球体目标:


但是这种方法只适用于目标没被遮挡的情况。倘若绿色小球被其他物体完全挡住了,用户就没法用射线选择到该球。换句话说,只有在场景遮挡物密度较低的情况下,射线方法 才能发挥较好的准确率。
而我们想开发新的VR交互技术,让用户在遮挡物密度高的情况下,也能快速且轻松地选择到目标。
为了解决这个问题,我们开发出了另外两种方法(B,C),并将这两种方法与射线方法(A) 进行比较,看看我们开发出来的方法,是不是在场景遮挡物密度较高的情况下仍然能有着较好的准确率。
1.2 实验设计
我们设计了拥有两个变量的实验:3 种技术(A,B,C) x 2 种场景(64, 128个遮挡物)
我们招募了 12 名志愿者,要求每名志愿者在不同场景下使用不同的技术重复完成 5 次任务。
故总共要进行 12 x 3 x 2 x 5 = 360 次实验。
为了分析哪种技术对于用户来说选择 速度最快,且用户能 感到更轻松,我们记录下了360次实验的 任务完成时间 ,以及36份 主观调查问卷分数(12个用户对3种不同技术分别填写一份问卷)。
1.任务完成时间即为用户从开始选择物体,到选择完成后的总完成时间。
2.主观问卷则是像NASA-TLX、Borg、SUS、UEQ-S之类的问卷,用于调查用户的主观感受。
在本实验中,我将以NASA-TLX问卷为例进行数据分析。其中,由于原版的NASA-TLX需要进行一系列的加权操作,比较麻烦。故我们可以选择简化版本的RAW NASA-TLX供用户填写,以方便计算。(RAW NASA-TLX是不需要加权的NASA-TLX问卷,挺多人机交互论文都选择了这个版本。当然,本文也会介绍怎如何使用原版NASA-TLX)
二、数据分析
在得到了 360 个时间数据,以及 36 份NASA-TLX问卷(因为要检验12个志愿者对3种不同技术的感受,故要填12*3份问卷)后,我们便可以进行数据分析了。
2.1 客观数据预处理
首先要先进行数据预处理,对大于平均值3个标准差的离群值进行剔除。
对于 360 个时间数据:
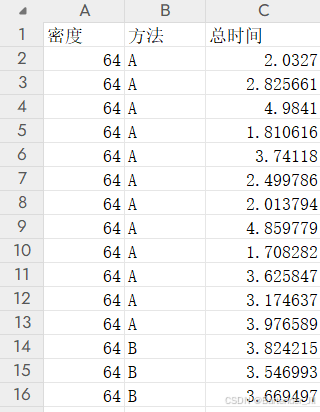
里面肯定有几个数据是比较离谱且偏离平均值的,比如因为用户分心导致任务用了20多秒才完成。
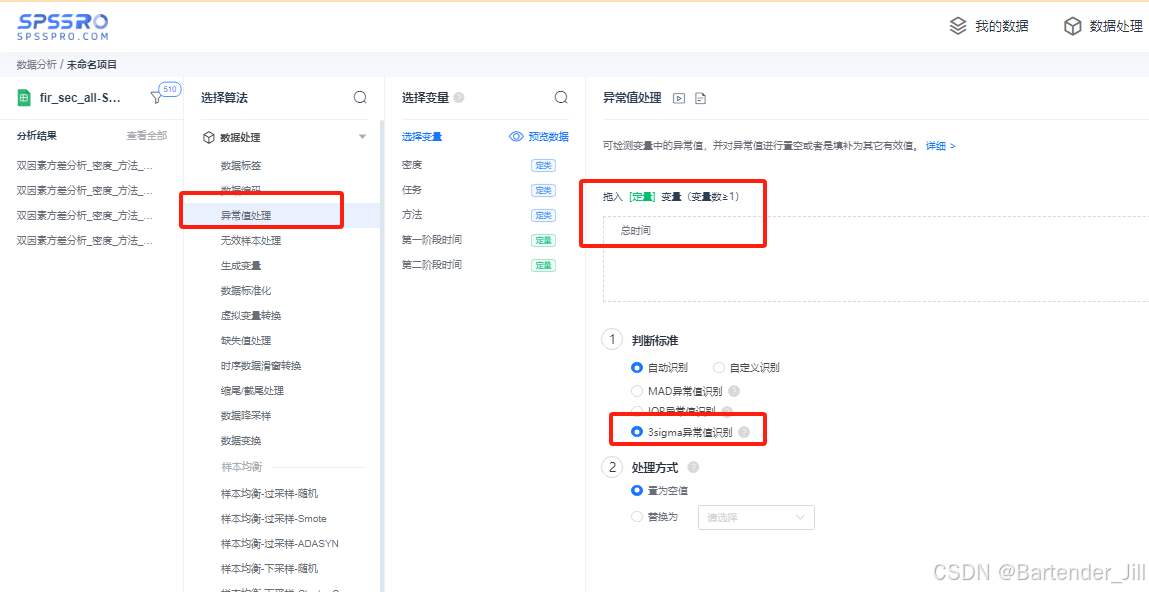
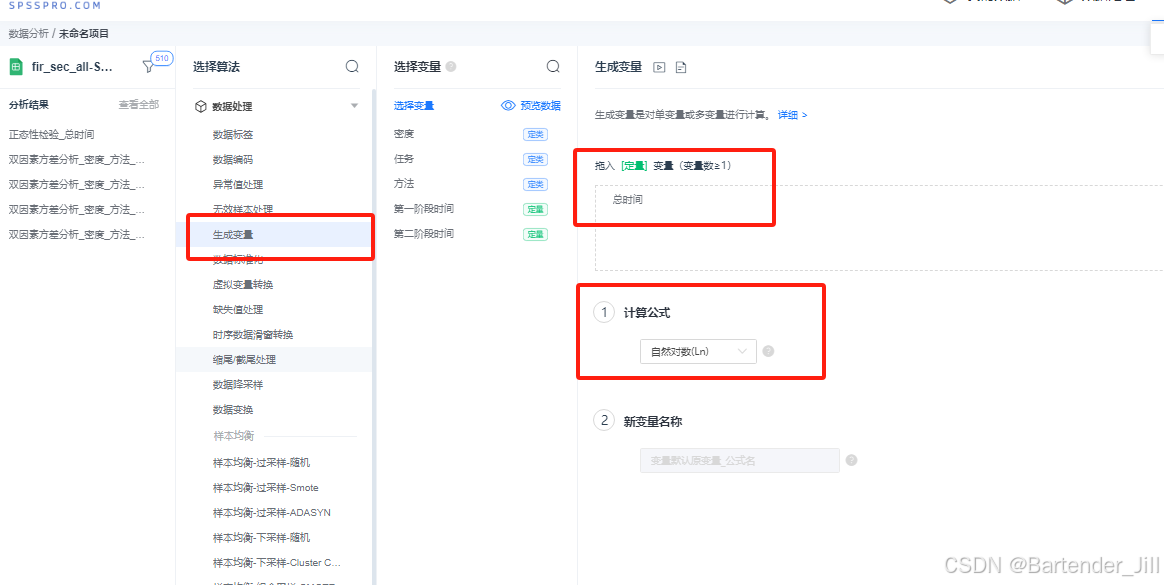
以SPSSPRO网站 为例,我们导入我们的excel文件(excel文件中存储了 360 个时间数据值),点击 “异常值处理” ,便可以选择对偏离均值3个sigma的离群值剔除并置为0值 (我这里是建议置为0,因为后续求平均值可以用到这个0):
在处理完成后,我们还要接着查看时间数据是否符合正态分布:
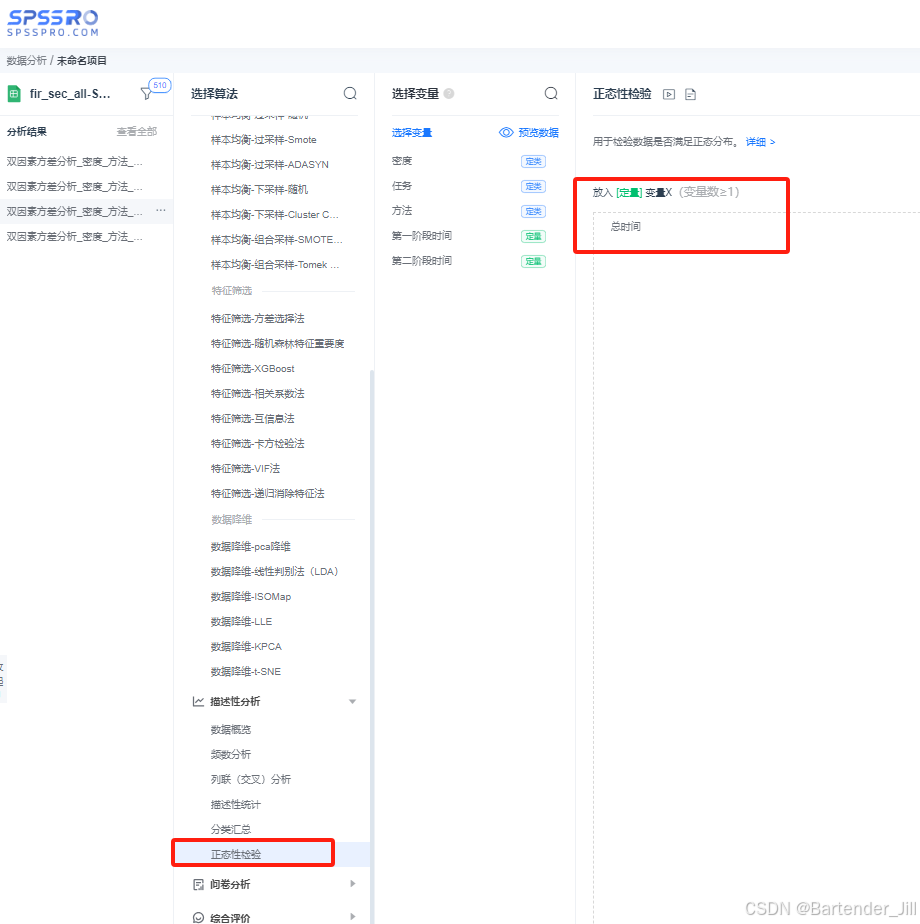
由分析结果可得,我们的数据在剔除了离群值后,满足正态分布:
为什么要进行正态性检验?因为许多数据分析方法(如ANOVA等)只能用于符合正态分布的数据,对于不符合正态分布的数据,我们要另寻其他的数据分析技术。
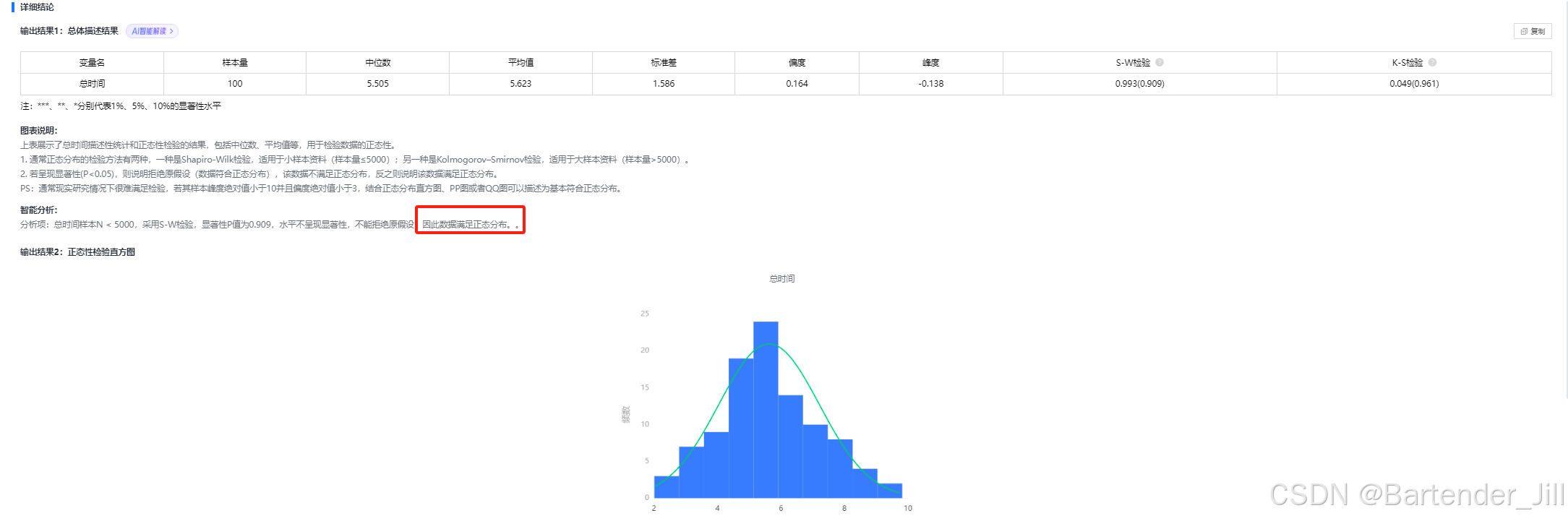
当然,如果你的数据如果是“满足正态分布”或“基本满足正态分布”的话,大部分情况下都是可以直接用的。
当然,为了严谨起见,你可以对时间数据进行一定的尺度变换,来将“基本满足正态分布”的数据转换成“满足正态分布”的情况,同时不影响分析。最常用的一种转换方式就是对所有时间数据取 对数,取完对数后再丢进“正态性检验”后,基本都能“满足正态分布”:
而对于“不满足正态分布”的数据,你先确保你的离群值已经剔除了。然后,你可以使用这个 Align-and-rank ART工具,来对时间数据进行处理,使其往正态分布方向靠。至于工具如何使用,由于涉及篇幅较长,后续再进行更新。
2.2 主观数据预处理
在处理完客观的“时间数据”后,我们是否就要轮到对“主观的问卷数据”进行处理?
其实是不需要的。
因为这种主观问卷的主观性太强,其数据本身往往就是难以符合正态分布情况的,故对于36 份“RAW NASA-TLX”主观问卷数据,我们保持不动即可,可以直接跳到显著性差异分析和两两验证。
这也是为什么许多论文都选择用Friedman对 主观数据 进行显著性差异分析而不用 ANOVA 。因为Friedman不要求数据“满足正态分布”,但是ANOVA需要,因为我们的主观问卷数据往往是不符合正态分布的。
那你可能会问,既然Friedman不要求数据“满足正态分布”,那我直接对时间客观数据也用Friedman分析不就好了吗?省了将时间数据转换成“满足正态分布”这个过程。
这块笔者一开始也很迷惑,但是经过一番查找,找到了以下资料 Friedman对主观问卷分析的优势 。
该资料解释道:鉴于用户评估的主观性,问卷调查得到的数据往往是不符合正态分布的,而ANOVA却要求数据是正态分布的。而Friedman 检验是一种非参数统计检验,它不假设数据呈正态分布,故非常适合分析 NASA-TLX 生成的有序数据。除此之外,使用 Friedman 检验可以比较多种条件或组的工作量,而不受参数检验的限制,因此非常适合 NASA-TLX 提供的多维构造情况。
简而言之,Friedman对主观问卷数据有更好的多维分析作用。
同样的,这也是为什么用 Wilcoxon 对问卷调查结果进行两两比较,而不是用Bonferroni。因为Wilcoxon检验特别适合于处理偏态分布或非正态分布的数据。因为NASA-TLX的评分数据可能不满足正态性假设,Wilcoxon检验是一种更好的选择。而Bonferroni校正则是更适用于数据满足正态分布,且独立多个假设(不同技术、不同场景)检验的校正方法。
三、分析技术介绍
3.1 拉丁方(Latin square)设计的作用
对实验进行拉丁方设计的意思是:不同的用户要使用不同任务顺序,以避免造成实验误差。
在我们的例子中,12个用户需要先执行A技术实验,再进行B技术实验,再进行C技术实验。但这样其实是不太严谨的,万一用户做实验时,越做越熟练,那么在做C技术实验的时候,完成C实验的时间指标往往会偏短,使得数据上来看,C技术相对于A技术更有优势。
为了避免这种误差,我们要采用拉丁方实验设计,即可以将12个用户分成3组。其中,第一组执行顺序为ABC,第二组为BCA,第三组为CAB:
| 组数 | 实验顺序1 | 实验顺序2 | 实验顺序3 |
|---|---|---|---|
| 第一组 | A | B | C |
| 第二组 | B | C | A |
| 第三组 | C | A | B |
确保每一行每一列都没有重复的字母(因素)出现,即可避免由于任务执行顺序所带来的误差。
3.2 显著性差异( significant difference )分析的作用
ANOVA 和 Friedman都是显著性差异分析方法,那什么是显著性差异分析方法呢?
“显著性差异分析”是一种判断不同条件对我们要观测的变量是否有明显影响的方法。
在我们的例子中,我们要用“显著性差异分析”方法,来验证两个变量(技术 、 场景密度 )对用户时间到底有没有造成影响。
如果不验证的话,我们怎能知道我们开发的新技术与旧的技术相比真的起到了作用?万一只是志愿者运气好在做你的实验时速度就是更快?
所以,显著性差异分析技术,是为了在理论层次上严谨地证明不同技术确实有差异,你开发的技术和旧的技术相比确实对用户的选择速度有区别。
故显著性差异分析能帮我们判断是不是“变量"真的对"时间”有影响,倘若有影响,那么就是有显著性差异,倘若没有影响,那就是没有显著性差异。
显著性差异往往由符号p表示,p越小,证明差异性越大,即你的方法与旧方法区别更大。当 p值<0.05 时,我们认为有显著性差异,当p值>0.05时,我们认为没有显著性差异,即你开发的新方法与旧方法压根没什么区别:

志愿者是在使用你的技术前,就越来越熟练VR设备了,操控起来本来速度就更快,耗费时间更少,结果你还傻傻的以为是自己的技术起效了,那就闹笑话了。
假设我们将 时间 进行显著性差异分析,结果显示技术A对时间有显著性差异,而技术B、C、D对时间没有显著性差异,那意味着在用户视角看来,其实你的BCD技术三者对于他而言根本没什么不同,都是起到同样作用的技术罢了。而A技术却是实实在在地影响用户的实验时间,至于A是让用户完成任务时间更快,还是更慢,都有可能。
显著性差异分析只是帮你判断有没有影响,至于是好的影响还是坏的影响就判断不了了。
ANOVA 和 Friedman的区别在于,ANOVA要求数据呈正态分布,而Friedman不要求数据呈正态分布。
3.3 事后两两验证( post-hoc pairwise comparisons )的作用
Bonferroni 和 Wilcoxcon都是事后两两验证方法,那什么是事后两两验证方法呢?
顾名思义,“事后两两验证方法”就是对成对的变量进行详细具体的显著性差异分析。
假设我们先前的ANOVA显著性差异分析结果表明,不同的技术条件对时间有着显著性差异,则意味着:当志愿者使用不同的技术A、B、C时,会影响他们完成任务的时间长短。但我们并不能从ANOVA结果中知道A、B、C这3种技术彼此之间的显著性差异程度如何。
我们虽然知道A和B和C之间有差异,但是差异具体是多少我们并不知道。
A和B方法到底有多大的不同呢?有没有可能A只是B好一点点,差异不算特别大?有没有可能我们改进的方法与旧方法相比改进的效果其实并不明显?
为了衡量这种具体的差异情况,我们便可以用两两校验方法对不同条件进行差异性计算。常用的两两校验方法有Bonferroni和Wilcoxcon。
两两校验结果中的差异性符号,通常也用p表示:

同样的,p越小差异性越大,p>0.05则认为没有显著性差异。
3.4 差异性符号p和星号*的关系
我们可能经常在论文里能看到这样的柱状图:
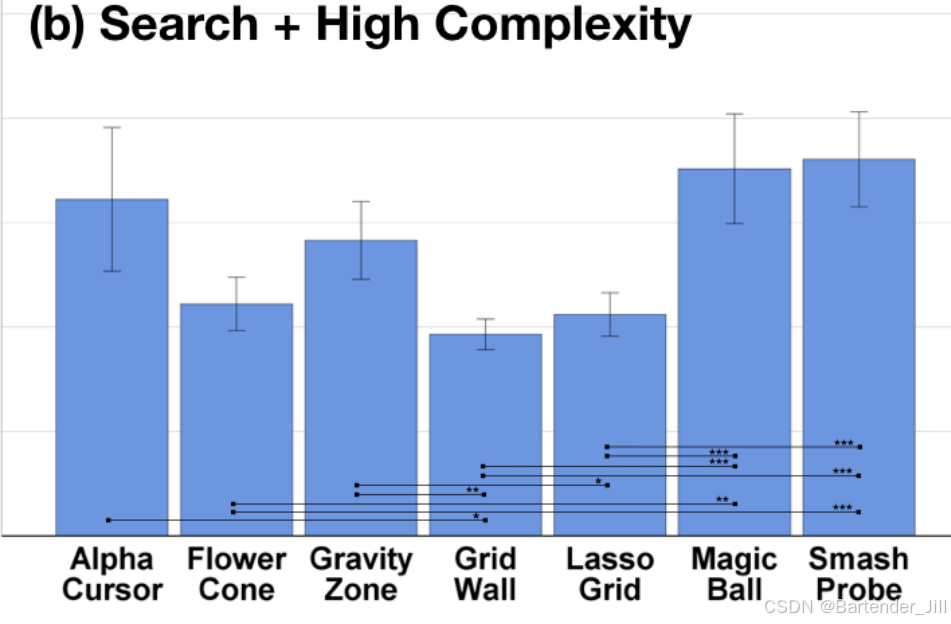
不同的技术之间连着线,线上面画着1到3颗*号不等。
这里的*号表达的是差异程度。两个方法间差异越大,星号越多。
具体而言:
P<0.05时,星号为1颗,有差异性但不多;
P<0.01时,星号为2颗,差异性可观;
P<0.001时,星号为3颗,差异性超级大;
四、数据分析
4.1 客观数据分析
对于收集到的 360 个客观数据我们经过剔除离群值(假设剔除了9个离群值后,剩下 351 个数据)以及一些相应的转换后,它已经是符合正态分布的数据了,接下来我们要对其进行“ANOVA显著性差异分析”和“Bonferroni 两两校验”。
由于涉及篇幅较长,具体过程请看我的另一篇博客:人机交互数据统计教程(二):ANOVA/Bonferroni两两校验/双因素重复测量方差 (更新中)
4.2 主观数据分析
对收集到的36份问卷调查数据进行“Friedman显著性差异分析”和“Wilcoxcon两两校验”。
由于涉及篇幅较长,具体过程请看我的另一篇博客:人机交互数据统计教程(三):主观数据分析Friedman/Wilcoxcon/NASA-TLX/UEQ-S/SUS/Borg问卷调查(更新中)
总结
本篇文章是对常见的分析方法进行了介绍与教学,如有错误,欢迎指出。


















 3283
3283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











