






摘要
如果在接近输入和接近输出的层之间包含更短的连接,卷积网络可以更深入,更准确,更有效。本文中,我们提出了稠密的卷积神经网络(DenseNet),它将每一层以一种前馈的方式连接到其它每一层。传统的具有L层的卷积网络在每一层和它的后续层之间有L个连接,我们的网络拥有L(L+1)/2个直连接。对于每一层,使用前面所有层的特征图作为输入,它自己的特征图作为所有后续层的输入。
DenseNet有以下几个优点:
- 减轻了梯度弥散带来的问题
- 增强了特征的传播
- 鼓励特征重用
- 大大减少了参数量
代码和预训练模型可以在[http://github.com/liuhuang13/DenseNet]上找到。
引言
卷积神经网络已成为诗句对象识别的主要机器学习方法。但是知道近几年才得到发展,对出的LeNet由5层组成,VGG有19层,直到Highway和ResNet的出现才达到了100层之上。
因为梯度弥散的问题,提出了许多解决办法。Highway Net和ResNet通过身份连接(identity connections)将信号从一层传到下一层。Stochastic depth通过随机丢弃ResNet在训练期间的层来获得更好的信息和梯度流。等等。虽然在拓扑和训练过程中有所不同,但他们都有一个关键特性:创建了从早期图层到后期图层的段路径(they create short paths from early layers to later layres,不太好理解)。
在这篇文章中,我们提出了一种将这种特性提炼成简单的连接模式的架构:为了确保网络层中各层之间最大的信息流,我么将每一层和其它层进行了直连接(有同样大小的匹配的特征图)。为了保持这种前馈特性,每一层要从之前的所有层中获得额外的输入,并将其自身的特征图传到后续的所有层中,如图1:
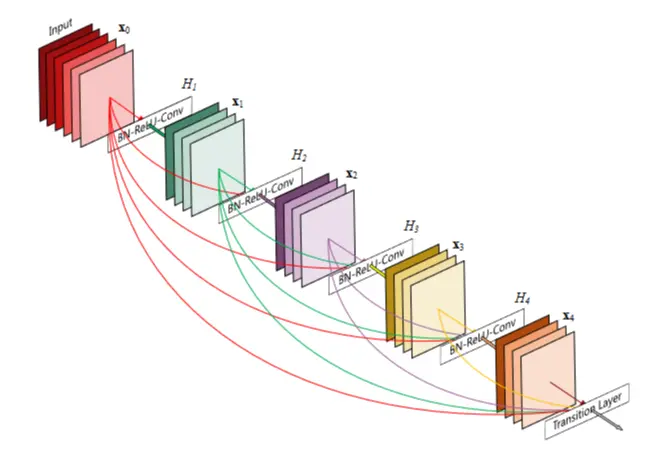
值得注意的是:相比于ResNet,我们没有通过将特征求和的组合方式传到一个图层中,相反,我们使用了连接的组合方式。因此,第i层有i个输入,这些输入是由第i层之前的所有卷积块的特征图组成,它自己的特征图传向了其后L-i个后续层。这就引入了L层网络的L(L+1)/2个连接,而不是传统的L个连接。因为密集的连接模式,我们将这种方法叫做 密集卷积网络(DesneNet)。
一个反直觉的效应是,相比于传统卷积网络这种密集连接模式需要的参数更少,因为它没有必要重新学习冗余的特征图。传统的前馈结构可以看作一种状态算法,这种状态从一层传到下一层,每一层从它的前一层读取状态,并写入到后面的层。虽然这种方式改变了状态,但是传递了需要保留的信息。ResNet通过加性标识转换达到了使信息显式保持的目的。ResNet的参数量大很多,因为每一层都有自己的权重。我们提出的DenseNet结构将加到网络上的信息和需要保留的信息进行了明确的区分。DenseNet层非常窄(例如,每层只有12个滤波器),仅向网路的“集体知识”("collective knowledge")中添加一小部分特征图并保持其余的特征图保持不变,最终的分类器基于网络中所有的特征图进行决策。
DenseNet的另外一大优点是其在整个网络中不断改进的信息和梯度流,这使得它们更容易训练。每一层都能直接从损失函数和原始输入信号中获得梯度,这有助于训练更深层次的网络架构。此外,我们发现密集连接有一种正则化的效果,这有助于减小在小规模数据集上的任务的过拟合问题。
相关工作
Highway Net是首批提供一种有效地训练超过100层的端到端的网络体系结构之一。
一种使网络更深的正交化方法是增加网络的宽度。GoogleNet就是这种。

DenseNet没有采用极深的或宽的体系结构进行代表性的特征抽取,而是通过特征复用来发掘网络的潜能,生成易于训练的和参数高效化的精简模型。连接不同层学习的特征图可以增加后续层的输入的变化并提高效率。这就构成了 DenseNet和ResNet的主要区别。
DenseNet
考虑一个通过卷积网络的单个图片X_0,该网络包含L层,每个层实现一个非线性转换H_l(·),其中l表示层的编号,H(·)可以是操作的复合函数,比如Batch Normalization(BN)、整流线性单元(ReLU)、池化层和卷积层。我们将第l层的输出定义为X_l。
- ResNet,传统的前馈卷积网络连接第l层的输出作为第
l+1层的输入,从而产生了下面的层转换,
,ResNet增加了一个跨层连接,它使用身份函数绕过了非线性变换:
ResNet的一个优点就是梯度可以直接通过身份函数从后面的层流到较前面的层。然而,身份函数和输出H_l通过相加的方式结合起来可能会阻碍网络中的信息流。 - Dense connectivity,为了进一步改善层间的信息流,我们提出了一个不同的连接模式:我们提出了从任何层向其所有后续层的直连接,如图1所示。因此,第l层接受其前所有层的特征图作为输入:

其中[x_0, x_1,...,x_l-1]表示第0到l-1层产生的特征图的连接。为了便于应用,我们将上式中的多输入[x_0, x_1,...,x_l-1]连接成一个张量。 - Composite function,我们将
H_l(·)定义为一个复合函数,它由三部分连续的操作组成:Batch Normalization、ReLU和一个3x3的卷积操作。 - Pooling layers,当特征图的尺寸发生变化时,式(2)中的连接操作是不可取的。然而,卷积网络的一个重要组成部分就是下采样层,它可以改变特征图的尺寸。为了便于在我们的体系结构中使用下采样层,我们将网络划分为多个紧密相连的密集块,如图2所示。我们将块之间的层称为过渡层,它们进行卷积和池化操作。我们实验中使用的过渡层包括一个
BN层和一个1x1的卷积层,其次是一个2x2的平均池化层。 - Growth rate, 如果每个
H函数产生k个特征图,那么第l层的输入特征图总数为:
其中k_0代表输入层的通道数。DenseNet和现有网络结构的一个重要区别在于DenseNet具有很窄的层,例如k=12,我们把超参数k称为网络的增长率。我们的实验表明一个较小的增长率就可以获得相对好的效果。
一种解释就是,网络的块中的每一层都可以获得其前的所有特征图,因此,可以访问网络的集体知识。每一层都可以将特征图看作网络的全局状态,并且可以将自己的k个特征图添加到这个全局状态中。增长率k调节每一层对全局状态贡献的新信息量。全局状态一经编写,就可以从网络的任何地方进行获取,而不需要像传统神经网络一样在层和层之间进行复制。 - Bottleneck layers,尽管每一层仅产生
k个特征图,但它通常情况下拥有更多的输入。在每个3x3卷积前引入1x1卷积作为瓶颈层可以减少输入特征图的数量,从而可以提高计算效率。 - Compression,为了进一步提高模型的紧凑性,我们可以在过渡层减少特征图的数量。如果一个密集块包含
m个特征图,我们让其后的过渡层产生一个输出特征图,其中
0<θ≤1被称为压缩因子,当θ=1时,通过过渡层的特征图数量不变,我们在实验中设置θ=0.5。 - Implenentation Details,除了ImgageNet以外的所有数据集,我们实验中使用的DenseNet都有三个密集块,每个块的层数都是相等的。在进入第一个紧密块之前,在输入图像上进行一个16通道的卷积。对于卷积核大小为3x3的卷积层,输入的每一侧都被填充一个像素以保持固定的特征图的大小。我们在1x1的卷积后跟一个2x2的平均池化层作为过渡层连接两个相邻的密集块。在最后一个密集块之后,执行一个全局平均池化,然后附加一个softmax分类器。三个紧密块的特征图尺寸分别为32x32、16x16和8x8。
训练
所有训练的网络都使用SGD梯度下降。在CIFAR和SVHN上训练的batch size为64,分别为300和40轮。初始学习率设置为0.1。















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









