







思维链提示+强化学习=>单元测试
由GPT单元测试生成知,其存在生成测试套件覆盖率低和焦点方法理解不佳的困难。针对上述难点,提出了一种名为TestCTRL的新方法,该方法通过思维链(CoT)提示和强化学习(RL)策略优化llm的单元测试生成。
具体地说,我们首先构建一个新的CoT数据集,其中包含焦点方法、相应的单元测试和CoT提示。CoT提示包括意图和可能的测试输入值。然后,使用CoT数据集对一个LLM(即具有7B个参数的CodeLlama)进行微调,该LLM可以视为RL中的策略模型。同时,我们通过预测焦点方法及其测试的行覆盖率来微调另一个LLM(即CodeGPT)作为奖励模型。此外,我们采用了近端策略优化(PPO)算法来优化策略模型并生成单元测试。最后,我们采用波束搜索算法在推理过程中生成单元测试。为了评估我们方法的有效性,我们使用了缺陷4j基准来评估我们的方法。实验结果表明,在行和分支覆盖率方面,TestCTRL比最先进的基线至少高出34%和36%。本文还探讨了该方法优越性的原因。
使用CoT提示的策略,增强了LLM的理解和测试边界生成。同时,TestCTRL还采用基于行覆盖率的奖励模型来提高生成测试的质量。
贡献
•创建了一个富含CoT提示符的新数据集。该数据集包括超过96K的焦点方法、相应的测试和相关的CoT提示。
•提出了TestCTRL,一种新的单元测试生成方法,它利用CoT提示和深度强化学习策略,可以生成具有更高行和分支覆盖率的单元测试。
•使用缺陷4j基准进行全面的实验。评估结果表明,TestCTRL优于所有基线,TestCTRL中的技术决策是合理和有益的。
概念
焦点方法:被单元测试的方法
单元测试包含测试代码和测试用例。单元测试中的“测试用例”更多是以测试代码的形式出现,这些代码包含了测试用例的描述、测试环境的设置、测试步骤的执行以及预期结果和实际结果的验证。
强化学习:主要研究智能主体(Agent)在环境中如何采取行动以最大化所获得的累积奖励,包括策略模型和奖励模型两个模型。
思维链模式:思维链提示(Thought Chain Prompting)是一种在教育、培训、问题解决或创造性思维活动中使用的技术,旨在通过一系列有序、连贯的提示或问题来引导个体或团队系统地思考和解决问题。这种方法通过构建一系列逻辑上相互关联的步骤或想法,帮助人们深入分析问题,逐步推导出解决方案或见解。
近端策略优化算法:PPO作为一个行动者-评论家算法运行,结合两个具有独立权重的网络:行动者网络,确定策略模型,和评论家网络(即奖励模型),奖励给定的状态-动作对,以改善行动者网络的选择。PPO利用一个剪切的目标函数来约束策略模型权重的更新,避免大规模的策略更新。
波束搜索算法:
预训练任务:是在深度学习,特别是在自然语言处理(NLP)和计算机视觉(CV)领域中,为了提升模型在特定任务上的表现而先期进行的一系列训练任务。这些任务通常是在大规模数据集上进行的,旨在让模型学习到数据的一般性、通用性知识或特征,从而为后续在特定任务上的微调(Fine-tuning)或迁移学习(Transfer Learning)提供坚实的基础。
特定下游任务与基础预训练阶段相一致:这意味着CoT提示设计时,会考虑如何让模型在解决特定任务时,能够利用其在基础预训练阶段学到的知识和技能。
鼓励模型语言化中间推理步骤:与传统的仅提供(查询、回答)对作为演示的标准提示不同,CoT提示不仅给出最终答案,还展示了从问题到答案的逐步推理过程,即中间推理步骤。这样做有助于模型理解问题的逻辑结构,提升其在复杂任务上的表现。
现有的基于强化学习的测试生成方法利用编译的测试结果作为奖励分数来表示生成输出的质量。如果没有包含给定测试的整个程序的可用性,就不可能为生成的测试提供奖励分数:这种方法的核心在于,测试生成器(通常是一个智能体,如神经网络)被训练来生成能够发现程序中错误的测试案例。然而,这种方法的局限性在于,它无法直接评估那些没有触发任何已知测试(即编译或运行时错误)的程序的可用性”或“正确性”,因为缺乏明确的评估标准。即无法评估未触发错误的测试。
最小化交叉熵损失:交叉熵损失函数用于衡量模型输出概率分布与真实标签概率分布之间的差异,并通过最小化这个差异来优化模型参数。
CodeBLEU分数是一种用于代码生成和评估的自动评价指标,它是对传统BLEU分数在代码领域的一种扩展和改进。
- n-gram匹配:CodeBLEU保留了BLEU中的n-gram匹配机制,用于评估生成代码与参考代码在词汇和短语层面的相似度。
- 语法信息:通过抽象语法树(AST)匹配,CodeBLEU能够评估生成代码在语法结构上的正确性。例如,它可以检测到代码中的token缺失、数据类型错误等语法问题。
- 语义信息:CodeBLEU还考虑了代码的语义信息,通过数据流分析来评估生成代码与参考代码在功能上的相似度。这有助于捕捉到那些虽然语法正确但功能不同的代码差异。
n-gram匹配:是一种文本匹配算法,它通过将文本切分成连续的n个字符或词语,并计算它们之间的相似度来确定文本之间的相关性。
问题
通过实验,得出由LLM大型语言模型存在生成测试套件覆盖率低和焦点方法理解不佳的困难。针对上述难点,提出了一种名为TestCTRL的新方法,该方法通过思维链(CoT)提示和强化学习(RL)策略优化llm的单元测试生成。
实验
1.设置基准:构建CoT数据集
2.提示设计:CoT数据集进行训练
3.基线
3.1:基于学习的基线:CodeBERT, AthenaTest ,StarCoder ,CodeLlama-7B ,TestCTRL
3.2:对比传统的和基于LLM的基线:Randoop、Evosuite
4.指标:生成单元测试的质量+消融研究
消融研究:控制变量
1.有无CoT数据集训练的影响
2.CoT提示中不同顺序的组件对生成测试质量的影响,初始顺序为:焦点方法、它们的意图和可能的输入值
3.奖励模型的效果
5.模型参数
我们对策略模型(即CodeLlama-7B[53])进行了350步微调,使用余弦学习率为1e−4。输入序列的最大长度为2048。批量大小为8个。由于参数数量庞大,对所有参数进行微调变得越来越不现实,因此我们利用LoRA框架[28]对上述策略模型进行微调。对于奖励模型,我们使用线性学习率2e−5对CodeGPT[71]进行了10个epoch的微调。输入长度的最大长度为1024。衰变的权重为0.001。在PPO优化过程中,我们将Adam学习率设置为1.4e−5。
此外,我们设置目标KL值为0.1进行自适应KL控制,初始化KL惩罚系数为0.2。在模型推理阶段,我们采用波束搜索算法[5],将波束数设置为5个。最大输出长度为1024。
环境。所有实验都在运行Ubuntu的服务器上进行,使用Python编程。服务器的规格如下:(1)CPU: Intel(R) Xeon(R) Platinum 8358P@2.60GHz 32核。(2) GPU: 8个Nvidia GeForce A800单元。(3) CUDA版本:12.0
结果
RQ1.生成单元测试的质量(与四个基于学习的模型对比)
(1)代码相似度:TestCTRL达到了最高的CodeBLEU分数17.24%,这表明它生成的测试与人类编写的测试最相似
(2)语法正确率和编译通过率:除了TestCTRL之外,我们可以看到CodeBERT的语法正确率也很高(97.46%)
(3)覆盖率:StarCoder是表现最好的基准。尽管StarCoder的模型参数和训练数据大小比TestCTRL大,但StarCoder在所有指标上都落后于TestCTRL。
优势:
(1)生成多样性的测试,为不同焦点方法提供更详尽的测试覆盖的潜力
(2)生成测试编译通过率更高
错误:
(1)测试包含错误的外部类或方法。
(2)测试包含不相关的函数。
(3)测试包含重复语句。
RQ2.消融研究(控制变量研究各个组件)
chatgpt生成的测试在测试充分性方面类似于手工编写的测试。ChatGPT实现了与手工测试相当的覆盖率,并且与现有技术相比覆盖率最高;ChatGPT还生成更多类似人类的测试,每个测试的断言数量与手工编写的测试相似。
RQ3.探索传统和基于LLM的单元测试
TestCTRL有最高的行覆盖率,这表明它在覆盖焦点方法的不同语句方面是最有效的
在分支覆盖率方面,Evosuite表现出色,表明其在测试不同决策分支方面的相对优势
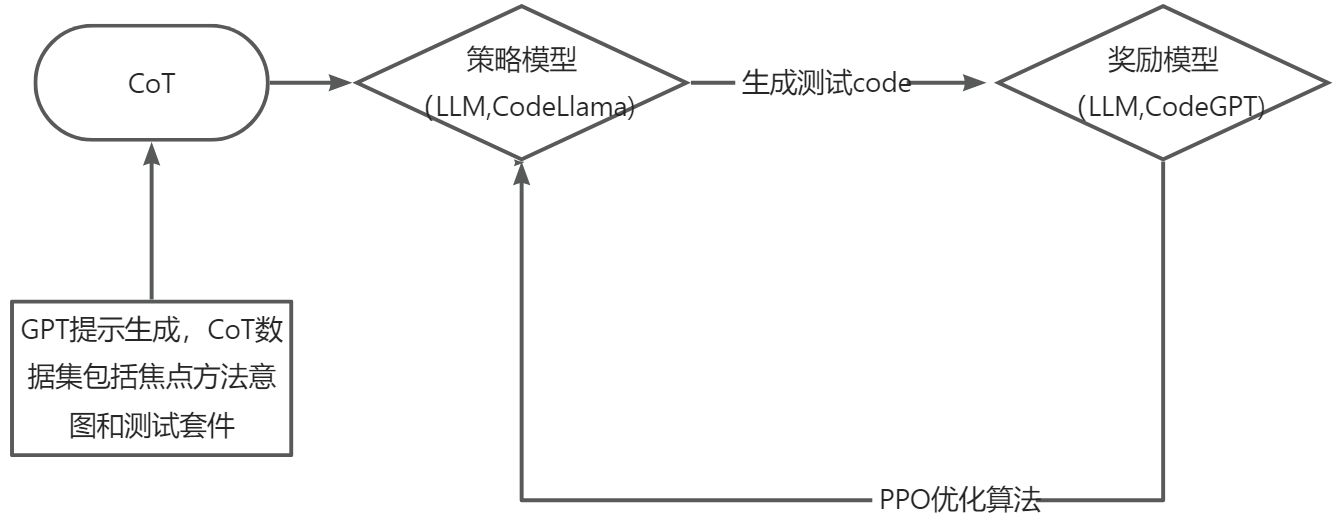
TestCTRL
其包含两个模块:策略模型和奖励模型。策略模型是一个使用CoT提示进行微调的LLM。奖励模型是另一个基于线路覆盖率预测任务进行微调的LLM。
收集CoT提示符的阶段。给定焦点方法,采用ChatGPT生成CoT提示,其中包括焦点方法的意图和可能的测试输入值。
策略模型,一个带有CoT提示的监督微调LLM(即CodeLlama-7B[53])。
奖励模型,一个基于行覆盖率的微调LLM(即CodeGPT[71]),在RL中优化策略模型的PPO算法。
该方法通过思维链(CoT)提示和强化学习(RL)策略优化llm(两个LLM拼接)的单元测试生成。对于焦点方法理解欠佳问题,采用思维链提示增强对焦点方法的理解。对于生成测试用例覆盖率低的问题,采用强化学习的方法优化llm,并利用行覆盖率作为奖励分数来调整llm生成测试的策略。此外,采用近端策略优化(PPO)算法来优化策略模型。当策略模型生成测试时,奖励模型提供反馈,用更高的覆盖率奖励测试。在迭代交互中,策略模型精炼了它的测试生成策略,旨在从奖励模型中获得最大的奖励。最后,就代码覆盖率而言,TestCTRL生成语法正确、语义有意义和全面的测试。利用波束搜索算法在推理过程中生成测试,以确保高效和最优的测试生成。
总结
针对基于学习的单元测试生成中多样性问题和焦点方法理解问题,本文提出了TestCTRL方法进行优化。首先,提出了CoT数据集。该数据集包含焦点方法,可能的测试值和方法意图三部分。其通过GPT进行中间化推理自动化生成。之后,该方法结合强化学习与大型语言模型技术对上述问题进行解决。其包含策略模型和奖励模型两个模块。对于策略模型,其采用CoT数据集对CodeLlama模型进行微调,用于测试代码的生成。对于奖励模型,采用行覆盖率作为奖励分数,选择GPT模型进行微调,用于调整LLM生成测试。同时,采用PPO算法对策略模型进行优化。通过基于传统的测试生成、基于学习的测试生成对比实验以及消融实验,验证了TestCTRL方法的有效性和优越性。
文章来源:[2305.04764] ChatUniTest: A Framework for LLM-Based Test Generation (arxiv.org)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











