







一 问题描述
提示:这里可以添加技术概要
使用基于oneAPI的C++/SYCL实现一个用于计算图像的卷积操作。输⼊为一个图像矩阵和一个卷积核矩阵,输出为卷积后的图像。
二 问题分析
提示:这里可以添加技术整体架构
图像卷积是一种常见的图像处理操作,用于应用各种滤波器和特征检测器。其原理可以简单地描述为在图像的
每个像素上应用一个小的矩阵(通常称为卷积核或滤波器),并将卷积核中的元素与图像中对应位置的像素值
相乘,然后将所有乘积的和作为结果。这个过程可以看作是对图像进行了平滑、锐化、边缘检测等操作。
假设有⼀个大小为M × N 的输入图像I 和一个大小为m × n 的卷积核 K 。图像卷积操作可以用下面的数学公
式来表示:
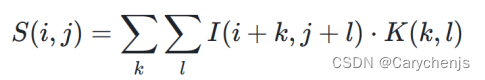
其中, S(i, j)是卷积操作的结果图像中位置 (i, j) 处的像素值。 I(i + k, j + l) 是图像中位置 (i + k, j + l) 处的像
素值, K(k, l) 是卷积核中位置 (k, l) 处的权重。卷积核通常是一个小的⼆维矩阵,用于捕捉图像中的特定特征。
在异构计算编程中,可以使用并行计算来加速图像卷积操作。通过将图像分割成小块,然后在GPU上并行处理
这些块,可以实现高效的图像卷积计算。通过合理的块大小和线程组织方式,可以最大限度地利用GPU的并行
计算能力来加速图像处理过程。
基于GPU的图像卷积操作的原理基于并行处理和矩阵乘法的基本原理,通过将图像数据和卷积核数据分配给不
同的线程块和线程,利用GPU的并行计算能力实现对图像的快速处理。
三 整体解决流程
提示:这里可以添加技术名词解释
(1)数据准备:
准备输入图像和卷积核。
确定图像和卷积核的尺寸。
(2)内存分配:
在主机(CPU)和设备(GPU)上分配内存。
将图像和卷积核的数据复制到GPU。
(3)并行卷积计算:
将图像分割成小块,每个线程块处理图像的一个区域。
实现卷积操作的核函数,每个线程计算输出图像中的一个或多个像素值。
(4)结果传回主机:
将卷积后的图像从GPU内存复制回主机内存。
(5)清理资源:
释放GPU和CPU上分配的资源。
图像卷积操作的代码:
#include <CL/sycl.hpp>
#include <vector>
const int img_height = 1024; // 图像高度
const int img_width = 1024; // 图像宽度
const int kernel_size = 3; // 卷积核大小
// 卷积核函数
void convolve(sycl::queue &queue, sycl::buffer<float, 2> &img_buffer, sycl::buffer<float, 2> &kernel_buffer, sycl::buffer<float, 2> &result_buffer) {
queue.submit([&](sycl::handler &cgh) {
auto img = img_buffer.get_access<sycl::access::mode::read>(cgh);
auto kernel = kernel_buffer.get_access<sycl::access::mode::read>(cgh);
auto result = result_buffer.get_access<sycl::access::mode::write>(cgh);
cgh.parallel_for<class convolveKernel>(sycl::range<2>(img_height, img_width), [=](sycl::item<2> item) {
int x = item.get_id(0);
int y = item.get_id(1);
float sum = 0.0f;
// 卷积计算
for (int i = 0; i < kernel_size; ++i) {
for (int j = 0; j < kernel_size; ++j) {
int ix = x + i - kernel_size / 2;
int iy = y + j - kernel_size / 2;
if (ix >= 0 && ix < img_height && iy >= 0 && iy < img_width) {
sum += img[ix][iy] * kernel[i][j];
}
}
}
result[x][y] = sum;
});
});
}
int main() {
std::vector<float> img(img_height * img_width);
std::vector<float> kernel(kernel_size * kernel_size);
std::vector<float> result(img_height * img_width);
// 初始化图像和卷积核
// ...
sycl::queue queue(sycl::default_selector{});
sycl::buffer<float, 2> img_buffer(img.data(), sycl::range<2>(img_height, img_width));
sycl::buffer<float, 2> kernel_buffer(kernel.data(), sycl::range<2>(kernel_size, kernel_size));
sycl::buffer<float, 2> result_buffer(result.data(), sycl::range<2>(img_height, img_width));
convolve(queue, img_buffer, kernel_buffer, result_buffer);
queue.wait_and_throw();
// 获取卷积后的图像
// ...
return 0;
}
四 技术细节
提示:这里可以添加技术细节
**边界处理:**在卷积过程中,需要注意图像的边界处理。当卷积核超出图像边界时,可以采用填充、裁剪或者忽略这些边界像素。
**性能优化:**可以通过调整线程块的大小和维度来优化性能。此外,共享内存的使用可以减少对全局内存的访问,从而提高性能。
**卷积核的选择:**卷积核的选择对于最终结果有很大影响。不同的卷积核可以实现不同的图像处理效果,例如锐化、模糊或边缘检测。
五 小结
提示:这里可以添加总结
通过这个基于oneAPI的C++/SYCL实现图像卷积并行加速的项目,学到以下几点:
1.oneAPI和SYCL的基础知识:
了解了oneAPI作为一个全栈开发环境,它提供了面向数据并行计算的工具和库。
掌握了SYCL作为一个基于标准C++的高级编程模型,它允许开发者编写代码来在异构硬件(如CPU、GPU)上执行。
2.异构计算的应用:
学习了如何在异构计算环境下编写程序,特别是如何在GPU上高效执行计算密集型任务。
理解了如何在GPU上使用SYCL编程模型来执行并行计算。
3.GPU内存管理:
掌握了如何在主机(CPU)和设备(GPU)之间管理内存,包括数据的分配和传输。
了解了在SYCL中使用buffer和accessor来管理内存,这对于确保数据在CPU和GPU之间正确同步至关重要。
4.并行编程技巧:
学习了如何将一个问题分解为可以并行处理的小任务,并在GPU上高效执行这些任务。
掌握了编写并行核函数的技能,这在进行GPU编程时是核心技术。
5.性能优化:
了解了如何调整线程块的大小和维度来优化GPU上的性能。
学习了如何利用共享内存来减少全局内存访问并提高计算效率。
6.实际应用场景:
通过实现图像卷积操作,理解了并行计算在实际应用(如图像处理)中的重要性和应用方式。
学到了如何将理论知识应用于解决实际问题,例如图像的平滑、锐化或边缘检测。

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









