







Perplexity和预训练时用的loss都是用来评估语言模型的性能的指标,但是它们的计算方式和意义有所不同。
Perplexity是一种用来衡量语言模型对一个测试集的预测能力的指标。它的计算方式是将测试集中的所有句子输入到语言模型中,计算每个句子的困惑度,最后将所有句子的困惑度取平均值得到一个整体的困惑度。困惑度反映的是语言模型在预测一个句子时的困难程度,它的值越小表示模型的预测能力越好。
预训练时用的loss是在模型训练过程中用来优化模型参数的指标。在预训练阶段,模型通常会使用一些预测任务(例如掩码语言建模或下一句预测)来学习语言的表示。这些任务都有一个对应的损失函数,模型的目标就是在训练过程中最小化这个损失函数。在预训练阶段,我们通常不会直接使用perplexity来评估模型性能,而是使用训练时使用的损失函数来评估模型。因为这些损失函数能够直接反映模型在特定任务上的表现,是训练过程中的优化目标。
perplexity可以作为模型的训练loss吗
perplexity可以作为语言模型的训练loss。在训练语言模型的过程中,我们可以使用perplexity来衡量模型在训练数据上的性能,并将其作为损失函数,用来更新模型参数。
具体来说,我们可以将语言模型的训练数据划分为训练集和验证集两部分。训练集用来训练模型参数,验证集用来评估模型在未见过的数据上的性能。在每个训练步骤中,我们使用训练集的数据来更新模型参数,并使用验证集来计算perplexity,衡量模型的性能。最终的训练目标就是使perplexity最小化,从而提高模型的性能。
需要注意的是,perplexity只是一种评估模型性能的指标,不能直接作为损失函数进行优化。因此,在实际的训练过程中,我们通常会使用perplexity的对数形式(即log-perplexity)作为损失函数,从而方便进行优化。具体来说,我们可以将log-perplexity定义为:
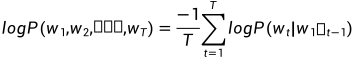
其中$T$表示句子的长度,$w_t$表示句子中的第$t$个词,$P(w_t|w_{1:t-1})$表示在已知前面$t-1$个词的情况下,预测第$t$个词的概率。最终的训练目标就是最小化log-perplexity的值。
perplexity和交叉熵损失的区别
Perplexity和交叉熵损失都是用来评估和优化语言模型的指标,但是它们的计算方式和意义有所不同。
Perplexity是用来衡量语言模型对一个测试集的预测能力的指标,它的计算方式是将测试集中的所有句子输入到语言模型中,计算每个句子的困惑度,最后将所有句子的困惑度取平均值得到一个整体的困惑度。困惑度反映的是语言模型在预测一个句子时的困难程度,它的值越小表示模型的预测能力越好。
交叉熵损失是用来优化语言模型参数的损失函数,它的计算方式是将语言模型预测的概率分布和真实概率分布之间的交叉熵作为损失函数,用来更新模型参数。在训练语言模型时,我们通常会将目标词的one-hot编码作为真实概率分布,将语言模型预测的概率分布作为预测概率分布,然后计算它们之间的交叉熵。
在实际应用中,perplexity和交叉熵损失是紧密相关的,对数形式的perplexity(即log-perplexity)和交叉熵损失是等价的。因此,在训练语言模型时,我们可以将perplexity作为评估指标和损失函数,或者将交叉熵损失作为损失函数。不同的是,perplexity更加直观和易于理解,而交叉熵损失则更加常用和方便计算。

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









