









激活函数:
- Sigmoid
- Tanh
- ReLU
- LReLU
- PReLU
- ReLU6
- Scaled Exponential Linear Unit (SELU)
- Softplus
- Swish
- hard-Swish
- Mish
(一)Sigmoid
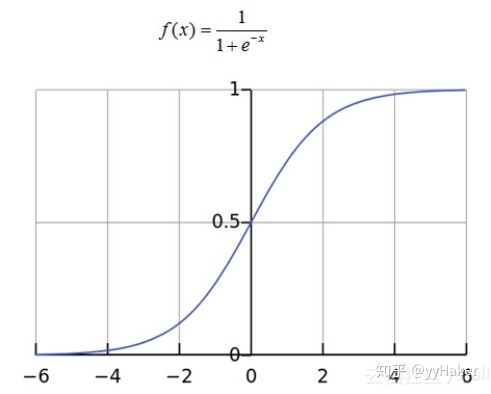
优点:平滑、易于求导,sigmoid的输出是(0,1),可以被表示做概率或者用于输入的归一化等等;
缺点:
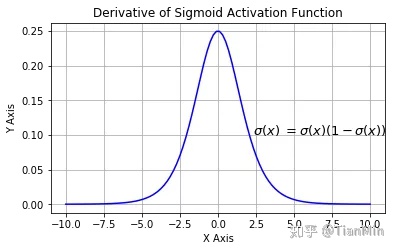
1. 梯度消失:注意:Sigmoid 函数趋近 0 和 1 的时候变化率会变得平坦,也就是说,Sigmoid 的梯度趋近于 0。神经网络使用 Sigmoid 激活函数进行反向传播时,输出接近 0 或 1 的神经元其梯度趋近于 0。这些神经元叫作饱和神经元。因此,这些神经元的权重不会更新。此外,与此类神经元相连的神经元的权重也更新得很慢。该问题叫作梯度消失。因此,想象一下,如果一个大型神经网络包含 Sigmoid 神经元,而其中很多个都处于饱和状态,那么该网络无法执行反向传播。
2. 不以零为中心:
通过Sigmoid函数我们可以知道,Sigmoid的输出值恒大于0,输出不是0均值(既zero-centerde),这会导致后一层的神经元将得到上一层输出的非均值的输入。
举例来讲σ(∑iwixi+b)σ(∑iwixi+b),如果xixi恒大于0,那么对其wiwi的导数总是正数或总是负数,向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。且可能导致陷入局部最小值。当然了,如果按batch去训练,那么那个batch可能得到不同的信号,所以这个问题还是可以缓解一下的。
当然,如果是按 batch 去训练,那么每个 batch 可能得到不同的信号,整个批量的梯度加起来后可以缓解这个问题。因此,该问题相对于上面的神经元饱和问题来说只是个小麻烦,没有那么严重。
3. 计算成本高昂:exp() 函数与其他非线性激活函数相比,计算成本高昂。
(二)Tanh
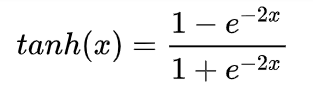
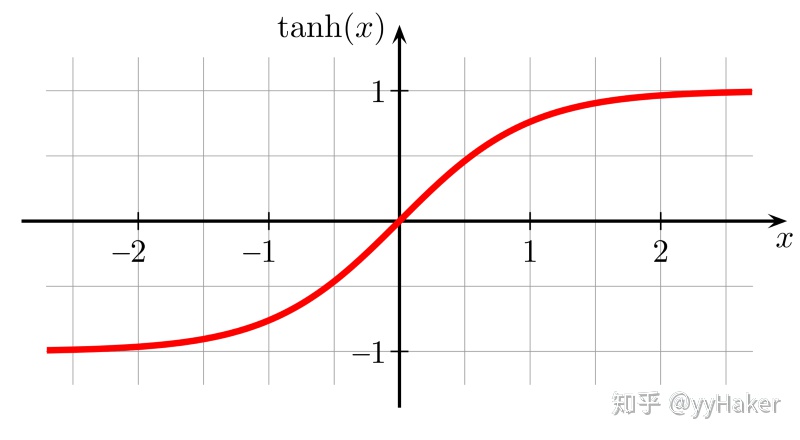
优点:Tanh 函数的输出以零为中心,因为区间在-1 到 1 之间。你可以将 Tanh 函数想象成两个 Sigmoid 函数放在一起。在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值;
缺点:Tanh 函数也会有梯度消失的问题,因此在饱和时也会「杀死」梯度。
(三)Relu
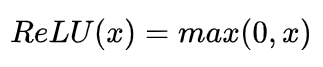
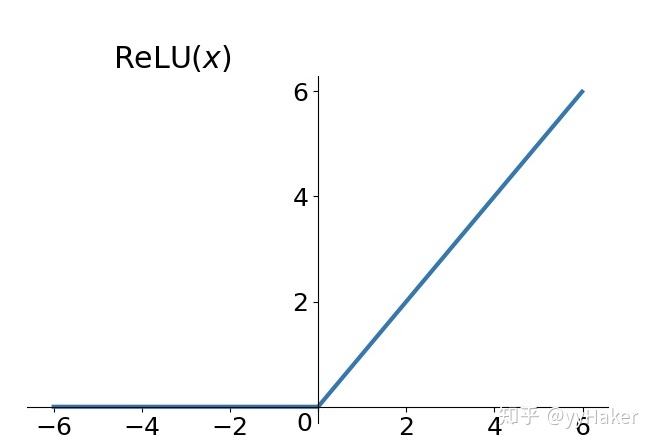
优点:
- 相比Sigmoid和tanh,ReLU摒弃了复杂的计算,提高了运算速度
- 解决了梯度消失问题,收敛速度快于Sigmoid和tanh函数,但要防范ReLU的梯度爆炸
缺点:与sigmoid类似,ReLU的输出均值也大于0,偏移现象和神经元死亡会共同影响网络的收敛性;
(四)Leaky ReLU、PReLU(Parametric Relu)、RReLU(Random ReLU)

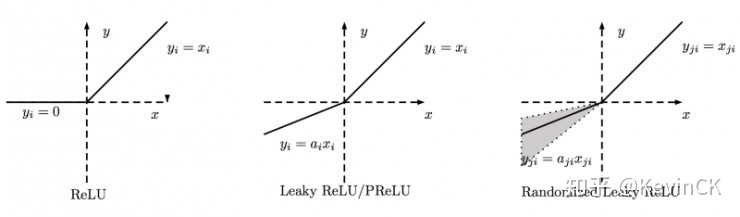
(五)ELU、SELU、RReLU(Random ReLU)、Relu6
ELU:Exponential Linear Unit(ELU,指数化线性单元),为了解决ReLU存在的问题而提出的,ELU有ReLU的基本所有优点,以及不会有Dead ReLU问题,和输出的均值接近0(zero-certered),它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
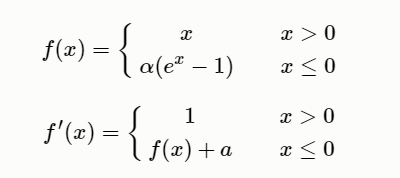
SELU:

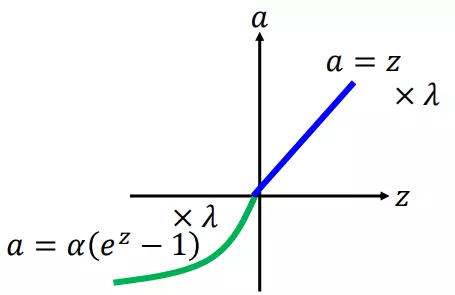
其中超参 α 和 λ 的值是 证明得到 的(而非训练学习得到):
α = 1.6732632423543772848170429916717λ = 1.0507009873554804934193349852946
即:
- 不存在死区
- 存在饱和区(负无穷时, 趋于 -
αλ) - 输入大于零时,激活输出对输入进行了放大
Relu6
首先说明一下ReLU6,卷积之后通常会接一个ReLU非线性激活,在Mobile v1里面使用ReLU6,ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip),这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失。
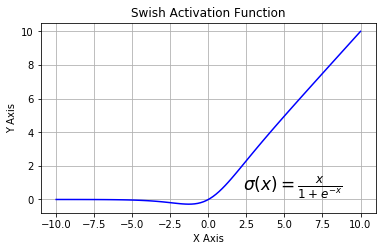
(六)Swish
Swish 激活函数,该函数又叫作自门控激活函数,它近期由谷歌的研究者发布,数学公式为:f(x)=x * sigmod(x)
(七)Softplus
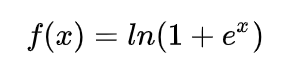
SoftPlus可以作为ReLu的一个不错的替代选择,可以看到与ReLU不同的是,SoftPlus的导数是连续的、非零的、无处不在的,这一特性可以防止出现ReLU中的“神经元死亡”现象。然而,SoftPlus是不对称的,不以0为中心,存在偏移现象;而且,由于其导数常常小于1,也可能会出现梯度消失的问题。
(八)Maxout

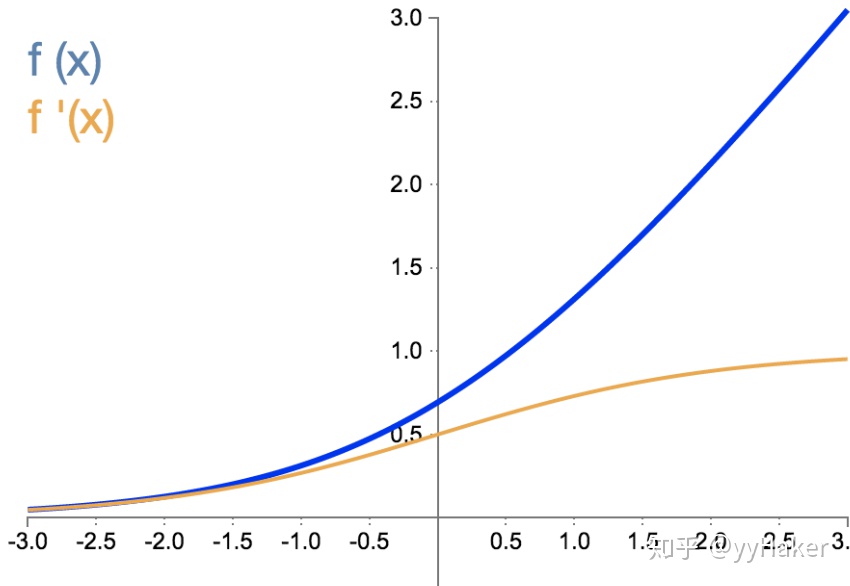
(九)Mish
Mish = x * tanh(ln(1+e^x))
为什么Mish表现这么好?
以上无边界(即正值可以达到任何高度)避免了由于封顶而导致的饱和。理论上对负值的轻微允许允许更好的梯度流,而不是像ReLU中那样的硬零边界。
最后,可能也是最重要的,目前的想法是,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
尽管如此,我测试了许多激活函数,它们也满足了其中的许多想法,但大多数都无法执行。这里的主要区别可能是Mish函数在曲线上几乎所有点上的平滑度。
loss
- MSE
- Smooth L1
- Balanced L1
- KL Loss
- GHM loss
Balanced L1 loss
这是一作在知乎的回答介绍。
如何看待 CVPR2019 论文 Libra R-CNN(一个全面平衡的目标检测器)?
Libra R-CNN中提出了Balanced L1 Loss。作者观察发现, Lloc那些easy samples只能贡献30%的梯度(具体说明?),这样的梯度贡献分配是不合理的(作者发现数据集中有不少的noise label,故希望能降低这些noise label对loss的负面影响,而这些noise label大部分分布在x比较大的部分)。
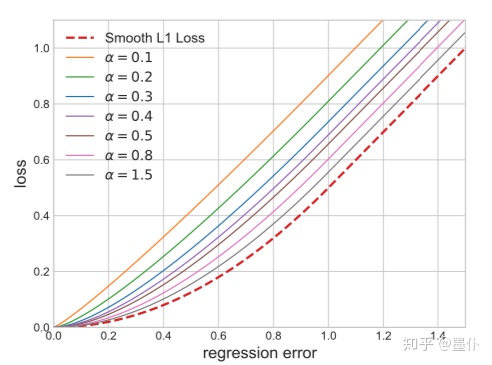

不过没有找到Balanced L1 Loss的easy samples贡献的梯度的百分比。可以看到,Balanced L1 Loss确实在x较小的时候提升了loss的值,变相减小了x比较大的时候的loss,达到了降低那些noise label的loss的效果。
Focal Loss与GHM——解决样本不平衡利器
参考链接:https://zhuanlan.zhihu.com/p/80594704
Bounded IoU Loss
- IoU Loss
- GIoU Loss
- CIoU Loss
- DIoU Loss
目标检测任务的损失函数由Classificition Loss和Bounding Box Regeression Loss两部分构成。目标检测任务中近几年来Bounding Box Regression Loss Function的演进过程,其演进路线是

一、IOU(Intersection over Union)
1. 特性(优点)
IoU就是我们所说的交并比,是目标检测中最常用的指标,在anchor-based的方法。作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离。
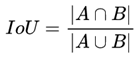
1. 可以说它可以反映预测检测框与真实检测框的检测效果。
2. 还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性)

2. 作为损失函数会出现的问题(缺点)
1. 如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练。
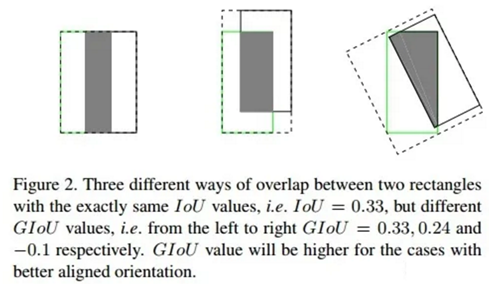
2. IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。
二、GIOU(Generalized Intersection over Union)
1、来源
在CVPR2019中,论文
《Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression》
https:arxiv.org/abs/1902.09630
提出了GIoU的思想。由于IoU是比值的概念,对目标物体的scale是不敏感的。然而检测任务中的BBox的回归损失(MSE loss, l1-smooth loss等)优化和IoU优化不是完全等价的,而且 Ln 范数对物体的scale也比较敏感,IoU无法直接优化没有重叠的部分。

这篇论文提出可以直接把IoU设为回归的loss。
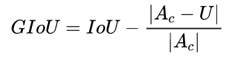
上面公式的意思是:先计算两个框的最小闭包区域面积_ _(通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
附:https://github.com/generalized-iou/g-darknet
2、 特性[1]
与IoU相似,GIoU也是一种距离度量,作为损失函数的话, 满足损失函数的基本要求:
GIoU对scale不敏感
GIoU是IoU的下界,在两个框无线重合的情况下,IoU=GIoU
IoU取值[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。
与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。


三、DIoU(Distance-IoU)[2]
1、来源
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。论文中
Distance-IoU
https://arxiv.org/pdf/1911.08287.pdf
基于IoU和GIoU存在的问题,作者提出了两个问题:
1. 直接最小化anchor框与目标框之间的归一化距离是否可行,以达到更快的收敛速度?
2. 如何使回归在与目标框有重叠甚至包含时更准确、更快?
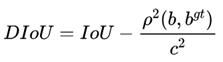
其中,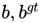 分别代表了预测框和真实框的中心点,
分别代表了预测框和真实框的中心点, 且代表的是计算两个中心点间的欧式距离。c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
且代表的是计算两个中心点间的欧式距离。c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。

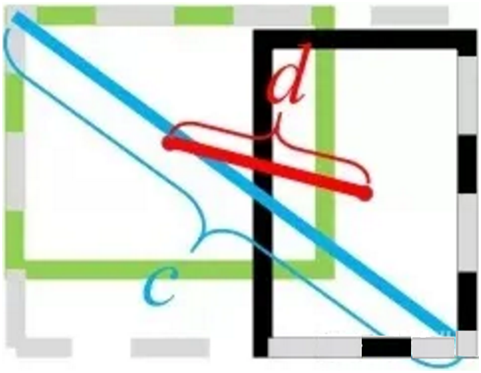
DIoU中对anchor框和目标框之间的归一化距离进行了建模
附:
YOLOV3 DIoU GitHub项目地址
https//github.com/Zzh-tju/DIoU-darknet
2、优点
与GIoU loss类似,DIoU loss( )在与目标框不重叠时,仍然可以为边界框提供移动方向。
DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快,而GIoU损失几乎退化为IoU损失。
DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
实现代码:[3]


四、CIoU(Complete-IoU)
论文考虑到bbox回归三要素中的长宽比还没被考虑到计算中,因此,进一步在DIoU的基础上提出了CIoU。其惩罚项如下面公式:

实现代码:[5]


















 2393
2393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









