







SV语法(1)——数据类型
1. 内建数据类型
SV中引入新的数据类型logic,SV作为侧重于验证的语言,并不十分关切logic对应的逻辑应该被综合位寄存器还是线网,因为logic被使用的场景如果是验证环境,那么它只会作为单纯的变量进行赋值操作。
引入的一个新的四态数据类型logic,可以代替reg;但是不能用在双总线和多驱动的情况下,此时只能使用网线类型,例如wire。
logic虽然只是表示数据类型,而在声明时,它默认会表示变量类型(variable),用户也可以显式声明其类型;
var logic [63: 0] addr; // a 64-bit wide variable
wire logic [63: 0] data; // a 64-bit wide net
与logic相对应的是bit类型,他们均可以构建矢量类型(vector),区别:
- logic为四值逻辑,0、1、Z、X
- bit为二值逻辑,0、1

按四值逻辑的类型和二值逻辑的类型划分:
四值逻辑类型:integer、logic、reg、net-type(例如wire、tri)
二值逻辑类型:byte、shortint、int、longint、bit
按有无符号的类型划分:
有符号类型:byte、shortint、int、longint、integer
无符号类型:bit、logic、reg、net-type(例如wire、tri)
bit a ; // 两态,单比特
bit [31: 0] b32 ; // 两态,32比特无符号
int c32 ; // 两态,32比特有符号
byte d8 ; // 两态,8比特有符号
shortint e16 ; // 两态,16比特有符号
longint f64 ; // 两态,64比特有符号
2.9补充
Verilog并没有严格区分信号的类型,变量和线网类型均是四值逻辑;
SV中将硬件信号区分为“类型”和数据类型;类型即表示该信号为变量(variables)或者线网类型(nets)。
对于线网类型赋值只能使用连续赋值语句(assign),对于变量类型赋值可以使用连续赋值、或者过程赋值;
数据类型则表示数据是四值逻辑(logic)还是二值逻辑(bit);
出个题:下面对于Verilog和SV数据类型赋值说法正确的有哪些:
A. Verilog中的变量类型只能使用过程赋值
B. Verilog中的线网类型只能使用连续赋值
C. SV中的变量类型只能使用过程赋值
D. SV中的线网类型只能使用连续赋值
SV中的assign连续赋值可以赋值给logic(var)类型吗?
在SV中,数据类型可以分为线网(net)和变量(variables)。线网的赋值设定,与Verilog的要求相同,即线网赋值只能使用连续赋值语句(assign),而不能出现在过程块(initial / always);相比于线网驱动的限制,变量(var)类型的驱动要求就没那么多了,例如 logic[3:0] a,该变量默认类型是var(变量),对它可以使用连续赋值、或者过程赋值;
避坑:可以在tb中大量使用logic类型变量,而很少使用wire。什么时候需要wire?多于一个驱动源的时候,或者设计模块端口是双向(inout)的时候;
// tb_assign_2_logic
module tb_assign_2_logic ;
wire w1;
logic r1; // 默认 logic(var)
assign w1 = 1'b1;
assign r1 = 1'b0;
wire logic w2;
var logic r2;
assign w2 = 1'b1;
assign r2 = 1'b0;
initial begin
#1ns;
$display ("w1 = %b, r1 = %b", w1, r1);
$display ("w2 = %b, r2 = %b", w2, r2);
end
endmodule

2. 用户自定义
在SV使用typedef关键字进行用户自定义类型的扩展。定义新的数据类型可以提高代码的可读性,复杂的数据类型(结构体、联合体)和特定的数组可以通过使用一个简单易懂的名字(别名)被定义为一个新的数据类型,这个新的类型就可以定义对应的变量:
typedef int my_favorite_type;
my_favorite_type a, b;
这样的方法不是创建新的数据类型,只是在做文本替换;将一个特定的数组定义为新的数据类型:
parameter OPSIZE = 8;
typedef reg [OPSIZE-1: 0] opreg_t;
opreg_t op_a, op_b;
如果使用空的typedef事先对一个数据类型作出标识,那么它就可以在其定义之前使用:
typedef foo;
foo f = 1;
typedef int foo;
一个用户自定义类型需要在类型的内容被定义之前声明。这对于由enum、sturct、union、class派生出的用户自定义类型很有用处:
typedef enum type_declaration_identifier;
typedef struct type_declaration_identifier;
typedef union type_declaration_identifier;
typedef class type_declaration_identifier;
typedef type_declaration_identifier;
某些情况下,定义一个新的数据类型是必须的,因为在SV中要用过数据类型的标识符才可以做类型转换:
// typedef_example
module test_typedef ();
typedef enum {red, green, blue, yellow, white, black} colors;
colors my_colors;
initial begin
$display ("my_colors's defaut value is %s", my_colors);
my_colors = green;
// my_colors = 1; // err 需要做数据类型转换
my_colors = colors'(3); // 通过colors数据类型标识符做类型转换
$display ("my_colors is %s", my_colors.name);
end
endmodule

2. 枚举类型
规范的操作吗和指令例如ADD、WRITE、IDLE等有利于代码的编写和维护,它比直接使用 'h01 这样的常量使用起来可读性和可维护性更好;
枚举类型enum经常和typedef搭配使用,由此便于用户自定义枚举类型的共享使用;
枚举类型的出现保证了一些非期望值的出现,降低来了设计风险;
一个枚举类型可以如下定义:
enum [data_type] {name1 = value, name2 = value2, ..., nameN = valueN} var_name;
enum {red, yellow, green} light1, light2;
无论是枚举名(red/yellow/…)还是他们的(整型)数值都必须是唯一的。他们的值可以被设置为任意整型常量值,或者从初始值0开始递增(默认情况)。
代码示例:
// enum_example
module test_enum ();
// 默认值:red = 0, yellow = 1, green = 2;
enum {red, yellow, green} light1, light2; // 未命名的枚举类型(int类型)
// 正确使用方法:IDLE = 0, S0 = 2, S1 = 3, S2 = x
enum integer {IDLE, S0 = 'b10, S1 = 'b11, S2 = 'x} state, next;
// 正确定义方法:silver和glod都没有指定大小
enum {bronze = 3, silver, gold} medal; // silver = 4, gold = 5
// c被自动地指定为8
enum {a = 3, b = 7, c} alphabet1;
// d = 0, e = 7, f = 8
enum {d, e = 7, f} alphabet2;
initial begin
light1 = red ;
light2 = green ;
// light1 = gold; // err
$display ("light1 is %0d or %s", light1, light1);
$display ("light2 is %0d or %s", light2, light2);
state = S1;
next = S2;
$display ("state is %0d or %s", state, state);
$display ("next is %0d or %s", next,next);
medal = silver ;
$display ("medal is %0d or %s", medal, medal);
alphabet1 = c ;
$display ("alphabet1 is %0d or %s", alphabet1, alphabet1);
alphabet2 = d ;
$display ("alphabet2 is %0d or %s", alphabet2, alphabet2);
end
// try something else
reg [ 3: 0] err;
initial begin
err = a;
$display ("err is %0d or %s", err, err);
end
endmodule

typedef enum {INIT, DECODE, IDLE} fsmstate_e;
fsmstate_e pstate, nstate; // 声明自定义类型变量
case (pstate)
IDLE: nstate = INIT; // 数据赋值
INIT: nstate = DECODE;
default: nstate = IDLE;
endcase
$display ("Next state is %s", nstate.name());
一个小测试:
就上面的例子中,给nstate如果直接用整数赋值,那么合法的范围是多少呢?
- 该赋值行为本身不合法
- [0:2]
- 任意整数
- 来杯冰可乐
枚举类型可以直接赋值给整型,整型不能直接赋值给枚举类型,需要做一个枚举类型的类型转换,这样在仿真的时候更安全。
INT = enum;
enum = ENUM'(INT);
// enum_test
module enum_test ;
// 默认值:red = 0, green = 1, blue = 2;
typedef enum {red, green, blue} Colors;
Colors my_color;
initial begin
my_color = red;
$display ("@0 my_color is %d or %s", my_color, my_color);
my_color = blue;
$display ("@1 my_color is %d or %s", my_color, my_color);
// my_color = int'(2); // err
// // An enum variable 'my_color' of type 'Colors' may only be assigned
// // the same enum typed variable or one of its values.
// // Value '2' requires an explicit cast.
// $display ("@2 my_color is %d or %s", my_color, my_color);
my_color = Colors'(1);
$display ("@2 my_color is %d or %s", my_color, my_color);
end
endmodule

SV未枚举类型提供了如下内置方法(method)来方便操作
- function enum first ():返回枚举类型中第一个成员的值
- function enum last ():返回枚举类型中最后一个成员的值
- function enum next (int unsigned N = 1):以当前成员为起点,返回后续第N个成员的值,默认是下一个成员的值;若起点为最后一个成员,则默认返回第一个成员的值
- function enum prev (int unsigned N = 1):以当前成员为起点,返回前面第N和成员的值,默认是前面一个成员;若起点为第一个成员,则默认返回最后一个成员的值
- function int num ():返回该枚举类型的成员数据
- function string name ():以字符串的形式返回该成员名字
4. 定宽数组
补充数组方法:
SV数组的方法——缩减、定位、排序.
int lo_hi [ 0:15]; // 16 ints [ 0]..[15]
int c_style [16]; // 16 ints [ 0]..[15]
多维数组声明和使用:
int array2 [ 0: 7][ 0: 3]; // 完整声明
int array3 [8][4]; // 紧凑声明
array2[7][3] = 1; // 设置最后一个元素
初始化和赋值:
int ascend[4] = '{0, 1, 2, 3}; // 对4个元素初始化
int descend[5];
descend = '{4, 3, 2, 1, 0}; // 为5个元素赋值
descend[0:2] = '{5, 6, 7}; // 为前三个元素赋值
sacend = '{4{8}}; // 4个值全部为8
descend = '{0:9, 1:8, default:-1}; // {9, 8, -1, -1, -1}
default说明: 用default初始化的时候,需要对不赋默认值的下标进行标注
在SV中,静态数组扩展了数组原始概念,允许定义每一维是如何存储的,这个扩展是基于存储的有效性和访问的灵活性考虑的。SV引入两种类型的数组:压缩数组(packed array)和非压缩数组(unpacked array)。
压缩数组指的是维数的定义在变量标识符之前,非压缩数组指的是维数的定义在变量标识符之后,
bit [7:0] cl; // 压缩数组(比特类型)
real u [7:0]; // 非压缩数组(实型)
存储空间考量
下面的两个变量,都可以表示24bit的数据容量,那么从实际硬件容量的角度出发,那种方式的存储方式更小呢?
bit [3][7:0] b_pack; // 3*8 合并型packed
bit [7:0] b_unpack[3]; // 3*8 非合并型unpacked

从上图可以得到b_unpack实际会占据3个WORD的存储空间,但是b_pack指挥占据一个WORD的存储空间
C语言的写法都是把维度写在变量名右边,硬件的话习惯性写在左边
将维度都写在左边称为合并型数组,高纬度在左边
只要有一个维度是写在右边,那就是非合并数组,高纬度从变量名右边开始
如果使用logic类型来存储上面的数据即24bit,分别声明变量为下面情况,它们占据的实际存储空间应该是多少?
logic [3][7:0] 1_pack;
logic [7:0] 1_unpack[3];
【解】:logic是四值逻辑,想要表示4中状态,就得需要2bit,所以24位的logic需要连续48bit,就是2WORD,非合并型需要 3* (8*2) 大小的空间,需要3WORD
integer i1 ; // 如logic signed [31: 0] i1;
byte c2[4:0] ; // 如bit signed [ 7: 0] c2[ 4: 0];
对于某些数据类型,可以通过整体访问或者把它分解成几个部分,例如,可以把一个32bit寄存器,作为四个8比特的寄存器或者作为一个32bit的整体。那么压缩数组可以实现这个目的。
压缩数组的维数只能通过[hi, lo]方式来定义。如下,变量reg_32是一个 由四个8bit特组成的压缩数组,作为一个32位的长字存储。
// array_example
module test_array ( );
bit [3:0] [7:0] reg_32; // 4个字节压缩为32bit的向量
bit [3:0] [7:0] mix_array[3];
initial begin
reg_32 = 32'hdead_beef;
$display ("%b", reg_32); // 打印所有的32bit
$display ("%h", reg_32[3]); // 打印最高位的字节“de”
$display ("%b", reg_32[3][7]); // 打印最高位比特“1”
mix_array[0] = 32'h0123_4567;
mix_array[1] = mix_array[0];
mix_array[2] = mix_array[1];
if (mix_array[1][3] == 8'h01)
$display ("Access mix_array[1][3]");
if (mix_array[2][1][6] == 1'b1)
$display ("Access mix_array[2][1][6]");
#50
//mix_array[0] = 64 mix_array[1] = 63, mix_array[2] = 62;
mix_array = '{64, 63, 62}; // 对于非压缩数组初始化,在声明时可以使用’{}内的值序列进行初始化
end
endmodule


基本数组操作for和foreach循环
initial begin
bit [31: 0] src[5], dst[5];
for (int i = 0; i < $size(src); i++)
src[i] = i;
foreach (dst[j])
dst[j] = src[j]*2; // dst doubles src values
end
基本数组操作复制和比较
对于赋值,可以利用赋值符号“ = ”直接进行数组的复制;
对于比较,在不适用循环的情况下,也可以利用” == “或者” != “来比较数组的内容,不过结果仅限于内容相同或者不同;
bit [31: 0] src[5] = '{0, 1, 2, 3, 4},
dst[5] = '{5, 4, 3, 2, 1};
if (src == dst) // 比较数组
$display ("src == dst");
else
$display ("src != dst");
dst = src; // 数组复制
src[0] = 5; // 修改数组中的一个元素
5. 动态数组
定宽数组类型给的宽度在编译时就确定了,但如果像在程序运行时再确定数据的宽度就需要使用【动态数组】了;SV提供动态数组,可以在仿真的过程动态分配大小。动态数组最大的特点就是可以在仿真运行时灵活调节数组的大小即存储量;
动态数组在一开始声明时,就需要利用” [ ] “来声明,而数组此时是空的,即0容量。其后,需要使用” new [ ] “来分配空间,在方括号中传递数组的宽度;
此外,也可以在调用 new [ ] 时将数组名也一并传递,将已有数组的值复制到新数组中;
动态数组可以是可以是一维或者多维的,其中非压缩部分的一维的大小在定义的时候为被指定,其存储空间只有当数组在运行时被显式分配之后才会存在。最简单的动态数组声明如下,
data_type array_name [];
bit [3:0] nibble [ ]; // 4bit向量的动态数组
integer mem [2][ ] ; // 固定大小的非压缩数组中 带两个动态的整型子数组
data_type时数组成员的数据类型,动态数组与静态数组支持相同的数据类型。空的“[ ]”意味着我们不需要在编译的时候指定数组的大小,在运行的过程中可以动态分配。动态数组初始化时是空的,没有分配空间,使用前必须通过调用new[ ],并在“[ ]”中输入期望的长度数值来分配空间。
int dyn[], d2[]; // 声明动态数组
initial begin
dyn = new[5]; // 分配5个元素
foreach (dyn[j]) dyn[j] = j; // 动态数组初始化
d2 = dyn; // 复制一个动态数组
d2[0] = 5; // 修改复制值
$display (dyn[0], d2[0]); // 显示数值0和数值5
dyn = new[20](dyn); // 分配20个数值并进行复制,{0, 1, 2, 3, 4, 0, 0, ..., 0};
dyn = new[100]; // 重新分配100个数值,而旧值不复存在,{0, 0, ..., 0};
dyn.delete(); // 删除所有元素
// dyn = new[0];
// dyn = '{};
end
sv增加了foreach循环,它可用来对一维或多维数组中的元素进行迭代。foreach循环的自变量是数组名,它后面是方括号内用逗号隔开的循环变量列表。每个循环变量对应于数组的一个维度。
// dy_array_example
module test_dy_array ( );
int dyn1[ ], dyn2[ ]; // 动态数组
initial begin
dyn1 = new[100]; // 分配100个成员
foreach (dyn1[i])
dyn1[i] = i; // 初始化成员
dyn2 = new[100](dyn1); // 复制一个动态数组
dyn2[0] = 5;
// 检查dyn1[0]和dyn2[0]的数值
$display ("dyn1[0] = %2d, dyn2[0] = %2d", dyn1[0], dyn2[0]);
// 扩展大小,并赋值初值
dyn1 = new[200](dyn1);
$display ("The size of dyn1 is %0d", dyn1.size());
// foreach (dyn1[i])
// $display ("dyn1[%2d] = %3d", i, dyn1[i]);
// 改变dyn1的大小
dyn1 = new[50];
$display ("The size of dyn1 is %0d", dyn1.size());
dyn1.delete;
$display ("The size of dyn1 is %0d", dyn1.size());
// 复制一个动态数组
dyn1 = dyn2;
$display ("dyn1[0] = %2d, dyn2[0] = %2d", dyn1[0], dyn2[0]);
end
endmodule

6. 关联数组
关联数组可以用来保存稀疏矩阵的元素,数据没有连续存储。当你对一个非常大的地址空间寻址时,该数组只为实际写入的元素分配空间,这种实现方法所需要的空间比定宽或动态数组所占用的空间要小的多;
关联数组在使用之前不会分配任何存储空间,并且索引表达式不仅仅是整型表达式,而且可以是任何数据类型。
此外,关联数组有其它灵活的应用,在其他软件语言也有类似的数据存储结构,被称之为哈希(Hash)或者词典(Dictionary),可以灵活赋予键值(key)和数值(value);
动态数组可以允许在程序运行的时候根据动态需求分配特定大小的数组,动态数组的限制在于其存储空间在一开始创建时就被固定下来,那么对于超大容量的数组这种方式无疑存在着浪费,因为很有可能该大容量的数组中有相当多的数据不会被存储和访问,空间被开辟了但是没有用到。
若我们需要一个超大的数组呢?在具体的应用环境中,如处理器,它可以访问几个GB的地址空间,如果全部分配,消耗的内存是非常巨大的;而实际测试中我们可能只需要访问某些范围或者离散的地址;关联数组是一种通过标号来分配空间和访问的数组,其好处就是只分配使用到的特定地址的空间,也就是当你访问某一个较大地址的数组时,SV只针对该地址分配空间。如下所示,关联数组只分配0~5、45、1000、4531和200000地址的数值。存储器分配也会比固定数组和动态数组小。

关联数组实现了一个所声明类型成员的查找表,用索引的数据类型作为查找表的查找键值,并强制了其排列顺序。关联数组的声明语法如下,
data_type array_id [index_type];
data_type时数组成员的数据类型。静态数组可以使用的任何类型都可以作为关联数组的数据类型;array_id是关联数组的变量名;index_type是用作索引的数据类型或者是* ,如果指定了※,那么数组可以使用任意大小的整型表达式来索引。采用数据类型作为索引的关联数组将索引表达式限制为一个特定的数据类型。
integer i_array [* ]; // 整型关联数组(未指定索引类型)
bit [20: 0] array_b [string];// 21bit向量的关联数组,索引为字符串
event ev_array [myClass]; // 事件的关联数组,索引为myClass的类
module assoc_test ;
// bit [63: 0] assoc[int]; // 制定索引类型为int
bit [63: 0] assoc[bit[63:0]];
bit [63: 0] idx = 1;
initial begin
repeat(64) begin // 对稀疏分布的元素进行初始化
assoc[idx] = idx;
idx = idx << 1; // assoc[1]=1、assoc[2]=2、assoc[4]=4、assoc[8]=8、assoc[16]=16、...
end
foreach (assoc[i]) begin // 使用foreach遍历数组
$display ("%d, %u", i, i); // %d 打印有符号数, %u 打印无符号数
$display ("assoc[%d] = %d", i, assoc[i]);
end
// 函数遍历
if (assoc.first(idx)) begin // 得到第一个索引
do
$display ("assoc[%d] = %d", idx, assoc[idx]);
while (assoc.next(idx)); // Get next index
end
// 找到并删除第一个元素
assoc.first(idx);
assoc.delete(idx); // 用下标删除对应元素
foreach (assoc[i]) // 使用foreach遍历数组
$display ("assoc[%d] = %d", i, assoc[i]);
end
endmodule
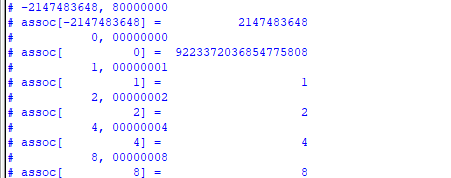
仿真的时候,发现一个有趣的结果,我想要的结果是下面的情况,但是实际打印了assoc[-21447483648] = 21447483648,这是因为最开始声明关联数组的时候,指定的索引类型为【int】,而int类型的数据默认是有符号的,当把声明改为【bit [63: 0] assoc[bit[63:0]];】就都好了
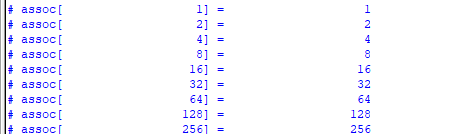
除了索引操作符外,SV提供了几个内建方法来让用户分析和处理关联数组,同时提供了对关联数组的索引或键值的迭代处理。
- function int num ( ) / function int size ( ):返回关联数组中成员的数目。如果数组是空数组,那么返回0;
- function void delete ([input index]):index是一个可选的适当类型的索引,删除特定索引的成员,如果没有指定索引,则删除数组的所有成员;
- function int exists (input index):index是一个适当类型的索引,如果成员存在,则返回1,否则返回0;
- function int first (ref index):index是一个适当类型的索引,将指定的索引变量赋值为关联数组中第一个(最小的索引的值);如果数组是空的,则返回0,否则返回1;
- function int last (ref index):index是一个适当类型的索引,将指定的索引变量赋值为关联数组中最后一个(最大的索引的值);如果数组是空的,则返回0,否则返回1;
- function int next (ref index):index是一个适当类型的索引,查找索引值大于指定索引的条目。如果存在下一个成员,索引变量被赋值为下一个成员的索引,并且函数返回1。否则,索引不会发生变化,函数返回0;
- function int prev (ref index):index是一个适当类型的索引,查找索引小于指定索引的成员。如果存在前一个成员,索引变量被赋值为前一个成员的索引,并且函数返回1 。否则,索引不会发生变化,并且函数返回0;
// as_array_example
module test_associate_array ( );
bit [ 7: 0] i_array [* ]; // 整型关联数组(未指定索引类型)
// 未指定索引(*)表明可以是任意整型
bit [ 7: 0] idx;
bit [ 7: 0] age [string]; // 8bit向量的关联数组,索引为字符串
string tom = "tom";
int assoc_array [int unsigned] = '{1:1, 2:2, 3:3, 4:4, 5:5, 6:6, 7:7, 8:8, 9:9, 10:10};
int unsigned idx_int, smallest, largest;
initial begin
idx = 1;
repeat (6) begin
i_array[idx] = idx;
idx = idx << 1;
// 8'b0000_0001( 1) 8'b0000_0010( 2) 8'b0000_0100( 4) 8'b0000_1000( 8)
// 8'b0001_0000(16) 8'b0010_0000(32)
end
if (i_array.first(idx)) begin // 将i_array[0]赋值给idx
// 如果数组是空的,则返回0,否则返回1
do
$display ("i_array[%2d] = %2d", idx, i_array[idx]);
while(i_array.next(idx)); // 如果i_array[idx]存在下一个成员,idx = idx + 1,函数返回1
// 否则,索引不会发生变化,函数返回0
end
age[tom] = 21;
age["joe"] = 32; // 【不理解要干啥】
$display ("%s is %d years of age", tom, age[tom], "[%0d ages available]", age.num());
// function int num ( ):返回关联数组中成员的数目
$display ("smallest = %2d, largest = %2d", smallest, largest);
if (!assoc_array.first (smallest))
// 将指定的索引变量smallest赋值为关联数组assoc_array中第一个(最小的)索引的值
// 如果数组是空的,则返回0,否则返回1
$display ("ERROR-Assoc array has no indexes!");
if (!assoc_array.last(largest))
// 将指定的索引变量smallest赋值为关联数组assoc_array中最后一个(最大的)索引的值
// 如果数组是空的,则返回0,否则返回1
$display ("ERROR-Assoc array has no indexes!");
$display ("smallest = %2d, largest = %2d", smallest, largest);
$display ("Smallest indes is %2d", smallest);
$display ("Largest index is %2d", largest);
idx_int = largest; // 赋值个10 assoc_array[10] = 10
do
$display ("Index %0d is set to %0d", idx_int, assoc_array[idx_int]);
while (assoc_array.prev(idx_int));// 如果assoc_array[idx_int]存在前一个成员,idx_int = idx_inx - 1,函数返回1
// 否则,索引不会发生变化,函数返回0
// 实现的功能就是倒序遍历
end
endmodule

7. 队列
队列是一个大小可变,具有相同数据类型成员的有序集合,结合了链表和数组的优点,可以在它的任何地方添加或删除元素,并且通过索引实现对任意元素的放访问。
队列的声明式使用 [$ ] 符号,队列元素的标号从0到$;队列类似于动态数组,是一个一维二点非压缩数组,它可以自动地增长或缩减。因此,与数组一样,队列可以使用索引、串联、分片、比较操作符进行处理。
队列不需要 new[ ] 去创建空间,只需要使用队列的方法为其增减元素,一开始其空间为0;
队列能够在固定时间内访问它的所有元素,也能够在固定时间内对队列的尾部和头部插入和删除成员,适合于实现FIFO和堆栈之类地数据结构;
队列的一个简单使用即是通过其自带方法 push_back( ) 和 pop_front( ) 的结合来实现FIFO的用法;
队列定义如下,
data_type queue_name [$ ];
data_type queue_name [$:maxsize];
data_type是数据成员地数据类型,与静态数组和动态数组支持地一致;queue_name是定义的队列变量,若给定max size,那么队列成员地最大数将受到约束。例如,
byte q1 [$ ]; // 字节队列
string names [$ ] = {"Bob"}; // 字符串队列
integer Q [$ ] = {3, 2, 7}; // 初始化整型队列
bit q1 [$: 255]; // 最大长度为256的bit队列
空队列文本{ }可以用来指示一个空队列。如果声明式没有提供初始值,那么队列变量被初始化成一个空队列。
当创建一个队列的时候,SV实际上分配了额外的空间,所以可以很快的添加成员。不用像动态数组那样调用new [ ]为队列分配空间;当添加到一定数量的成员之后,SV会自动分配额外的空间,为此可以任意增加和缩减一个队列,而对性能没有太大影响。
int j = 1;
int q2[$] = {3, 4}; // 队列复制不使用“ ' ”
int q[$] = {0, 2, 5};
initial begin
q.insert(1, j); // {0, 1, 2, 5},在q[1]前插入j
q.insert(3, q2);// {0, 1, 2, 3, 4, 5},在q[3]前插入队列q2
q.delete(1); // {0, 2, 3, 4, 5},删除q[1]
// 高端操作,是内置函数实现FIFO和栈
q.push_front(6); // {6, 0, 2, 3, 4, 5},在队列头部插入
j = q.pop_back(); // {6, 0, 2, 3, 4},从队列尾部取出
q.push_back(8); // {6, 0, 2, 3, 4, 8},在队列尾部插入
j = q.pop_front(); // {0, 2, 3, 4, 8},从队列头部取出
foreach (q[i])
$display (q[i]);// 打印队列q
q.delete(); // 删除整个队列
end
// queue_example
module test_queue ( );
int queue1 [$ ];
int n, m, item;
initial begin
queue1 = {1, 2, 3, 4, 5};
n = 8;
m = 9;
// 使用拼接操作符把n放到queue1的最左边
queue1 = {n, queue1};
// 使用拼接操作符把m放到queue1的最右边
queue1 = {queue1, m};
// 将queue1左边第一个成员赋值给item
item = queue1[0];
// 将queue1右边最后一个成员赋值给item
item = queue1[$];
// 通过整数对queue1做遍历访问
for (int i = 0; i < queue1.size( ); i++) begin
$display ("queue1[%0d] = %0d", i, queue1[i]);
end
// 求queue1的长度
n = queue1.size( );
$display ("queue1 size is %0d", n);
// 删除左边第一个成员
queue1 = queue1[1: $];
// 删除右边第一个成员
queue1 = queue1[0: $-1];
for (int i = 0; i < queue1.size( ); i++) begin
$display ("queue1[%0d] = %0d", i, queue1[i]);
end
queue1 = {}; // 清空队列
$display ("queue1 size is %0d", queue1.size( ));
end
endmodule

// as_array_example_2
// Description: 使用字符串索引读取文件,并建立关联数组switch,以实现从字符串到数组的映射
// Document content:42 min_address
// 1492 max_address
module as_array_example_2 ;
int switch[string], min_address, max_address;
initial begin
int i, r, file;
string s;
file = $fopen("switch.txt", "r");
while (! $feof(file)) begin
r = $fscanf(file, "%d %s", i, s);
switch[s] = i;
end
$fclose(file);
// 获取最小地址值,缺省值为0
min_address = switch["min_address"];
// 获取最大地址值,缺省值为1000
if (switch.exists("max_address"))
max_address = switch["max_address"];
else
max_address = 1000;
// 打印数组的所有元素
foreach (switch[s])
$display ("switch['%s'] = %0d", s, switch[s]);
end
endmodule

SV提供下面几种预定义的方法来访问和操作队列,
- function int size ( ):返回队列中成员的数目。如果队列空,返回0;
- function void insert (int index, queue_type item):在指定的索引位置插入指定的成员;
Q.insert(i, e)等效于Q= {Q[0:i-1], e, Q[i, $]}; - function void delete (int index):删除指定索引位置的成员;
Q.delete(i)等效于Q = {Q[0:i-1], Q[i+1, $]}; - function queue_type pop_front ( ):删除并返回队列的第一个成员;
e = Q.pop_front( )等效于e = Q[0], Q = Q[1, $]; - function queue_type pop_back ( ):删除并返回队列的最后一个成员;
e = Q.pop_back ( )等效于e = Q[$], Q = Q[0, $-1]; - function void push_front (queue_type item):在队列的前端插入指定的成员;
Q.push_front(e)等效于Q = [e, Q]; - function void push_back (queue_type item):在队列的尾部插入指定的成员;
Q.push_back(e)等效于Q = [Q, e];
上面的方法可以用来建模堆栈、FIFO、队列
8. 字符串
当一个字符串文本被赋值到一个大小不同、整型压缩数组变量的时候,它或者被截短到变量的大小或者在左侧填补0。
SV中,字符串文本的表现行为与Verilog相同,但是SV还支持字符串类型,可以将一个字符串文本赋值到这种数据类型。当使用字符串元类型来代替一个整型变量的时候,字符串可以具有任意的长度并且不会发生截短现象。当字符串文本赋值到一个字符串类型或者在一个使用字符串类型操作数的表达式中使用的时候,会被隐式转换成字符串类型。
string variable_name [= initial_value];
string myName = "John Smith";
variable_name式一个有效的标识符,可选的initial_value可以是一个字符串文本,也可以式一个空字符串(" ")。如果在声明中没有指定初始值,变量就会被初始化成空字符串(" ")。
SV中的字符串末尾没有“ \0 ”,当用s.len()函数时,会返回最后一个字符的下标
// string_test
module string_test ;
string s; // "xxxx",最后没有"\0"
initial begin
s = "IEEE ";
$display (s.getc(0)); // 显示“I”
$display (s.tolower()); // 显示ieee
s.putc(s.len()-1, "-"); // 将空格变为“-”
s = {s, "P1800"}; // 字符串拼接,"IEEE-P1800"
$display (s.substr(2, 5)); // 显示EE-P
// 创建一个临时字符串并将其打印
my_log ($sformatf("%s %5d", s, 42));
end
task my_log (string message); // 打印消息
$display ("@%0t: %s", $time, message);
endtask
endmodule

8.1. 非组合型数组(unpacked)
对于Verilog,数组经常会被用来存储数据,例如
reg [15: 0] RAM [0:4095]; // memory array
SV将Verilog这种声明数组的方式称之为非组合型声明,即数组中的成员之间存储数据都是相互独立的;
Verilog也不会指定软件如如何存储数组中的成员,四个table在存储空间都是相互独立的
wire [ 7: 0] table [ 3: 0];
变量名左侧的维度都是连续的存储的,右侧维度声明都是分散独立的;
左侧是低维度,右侧是高纬度

SV保留了非组合型的数组生命方式,并且扩展了允许的类型,包括event,logic,bit,byte,int,longint,shortreal和real类型;
SV也保留了Verilog索引非组合型数组或者数组片段的能力,这种方式为数组以及数组片段的拷贝带来了方便;
int a1 [ 7: 0] [1023: 0]; // unpacked array
int a2 [ 1: 8] [1: 1024]; // unpacked array
a2 = a1; // copy entire array
a2[3] = a1[0]; // copy a slice of an array
数组声明的方式,有以下两种,
logic [31: 0] data [1024];
logic [31: 0] data [ 0: 1023];
8.2. 组合型数组(packed)
SV将Verilog的向量作为组合型数组声明方式,
wire [ 3: 0] select; // 4-bit "packed array"
reg [63: 0] data; // 64-bit "packed array"
SV也进一步允许多维组合型数组的声明,
logic [ 3: 0][ 7: 0] data; // 2-D packed array

组合型数组会进一步规范数据的存储方式,而不需要关心编译器或者操作系统的区别。
组合型(packed)除了可以运用的数组声明,也可以用来定义结构体的存储方式:
typedef struct packed {
logic [ 7: 0] crc;
logic [63: 0] data;
}data_word;
data_word [ 7: 0] darray;
组合型数组和其他数组片段也可以灵活选择,用来拷贝和赋值等,
logic [ 3: 0][ 7: 0] data; // 2-D packed array
wire [31: 0] out = data; // entire array
wire sign = data[3][7]; // bit-select
wire [ 3: 0] nib = data[ 0][ 3: 0]; // part-select
byte high_byte;
assign high_byte = data[3]; // 8-bit slice
logic [15: 0] word;
assign word = data[ 1: 0]; // 2 slice
1.8.3. 数组初始化
组合型(packed)数组初始化时,同向量初始化一直:
logic [ 3: 0][ 7: 0] a = 32'h0; // vector assignment
logic [ 3: 0][ 7: 0] b = {16'hz, 16'h0}; // concatenate operator 连接
logic [ 3: 0][ 7: 0] c = {16{2'b01}}; // replicate operator 复制
非组合型(unpacked)数组初始化时,则需要通过 '{} 来对数组的每一个维度进行赋值:
int d[ 0: 1][ 0: 3] = '{'{0, 4, 1, 8}. '{1, 1, 3, 0}};
// d[0][0] = 0
// d[0][1] = 4
// d[0][2] = 1
// d[0][3] = 8
// d[1][0] = 1
// d[1][1] = 1
// d[1][2] = 3
// d[1][2] = 0
8.4. 数组赋值
非组合型数组在初始化时,也可以类似结构体初始化,通过 '{} 和default关键词即可完成,
int a1 [ 0: 7][ 0: 1023] = '{default:8'h55};
非组合型数组的数据成员或者数组本身均可以为其赋值,
byte a [ 0: 3][ 0: 3];
a[1][0] = 8'h5; // assign to one element
a[3] = '{'hF, 'hA, 'hB, 'hC}; // assign list of values to slice of the array
一下是组合型数组的赋值方法,
logic [ 1: 0][ 1: 0][ 7: 0] a; // 3-D packed array
a[1][1][0] = 1'b0; // assign to one bit
a = 32'hF1A2B3C4; // assign to full array
a[1][0][3:0] = 4'hF; // assign to a part select
a[0] = 16'h FABC; // assign to a slice
a = {16'bz, 16'b0}; // assign concatenction
8.5. 数组拷贝
对于组合型数组,由于数组会被视为向量,因此当赋值左右两侧操作数的大小和维度不相同时,也可以做赋值;
如果当尺寸不相同时,则会通过截取或者扩展右侧操作数的方式来对左侧操作数赋值,
bit [ 1: 0][15: 0] a; // 32-bit 2-state vector
logic [ 3: 0][ 7: 0] b; // 32-bit 4-state vector
logic [15: 0] c; // 16-bit 4-state vector
logic [39: 0] d; // 40-bit 4-state vector
b = a; // assign 32-bit array to 32-bit array
c = a; // upper 16-bit will be truncated 高位截断
d = a; // upper 8-bit will be zero filled 空位填充
对于非组合型数组,在发生数组间拷贝时,则要求左右两侧操作数的维度和大小必须严格一致,
logic [31: 0] a [ 2: 0][ 9: 0];
logic [ 0:31] b [ 1: 3][ 1:10];
a = b; // assign unpacked array to unpacked array
非组合型数组无法直接赋值给组合型数组,同样的,组合型数组也无法直接赋值给非组合型数组。
9. 结构体和联合体
Verilog的最大缺陷之一就是没有数据结构,在SV中可以使用struct语句创建结构,跟c语言类似;
不过struct的功能少,它只是一个数据的集合,其通常的使用的方式是将若干相关的变量组合到一个struct的结构定义中;
伴随typedef可以来创建新的类型,并利用新类型类声明更多变量;
struct { bit [7:0] r, g, b;} pixel; // 创建一个pixel结构体
// 为了共享该类型,通过typedef来创建新类型
typedef sturct {bit [7:0] r, g, b;} pixel_s;
pixel_s my_pixel; // 声明变量
my_pixel = '{'h10, 'h10, 'h10}; // 结构体类型赋值
结构体的成员被连续的存储,而联合体的所有成员共享用统一片存储空间,也就是联合体中最大成员的空间。
结构体和联合体的声明遵从C语言的语法,但在“{”之前没有可选的结构体标识符。如下,
// eg1:
struct {
bit [ 7: 0] opcode;
bit [23: 0] addr;
}IR; // 未命名结构体,定义结构体变量IR
IR.opcode = 1; // 对IR的成员opcode赋值
// eg2:
typedef struct {
bit [ 7: 0] opcode;
bit [23: 0] addr;
}instruction; // 命名为instruction的结构体类型
instruction IR; // 定义结构体变量
// eg3:
tyoedef union {
int i;
shortreal f;
}num; // 命名为num的联合体类型
num n;
n.f = 0.0; // 以浮点数合适设置n
一个结构体可以作为一个整体赋值,并且可以作为一个整体作为接口参数在一个函数或任务中传递。
// struct_example
module test_struct ( );
struct {
bit [ 7: 0] my_byte;
int my_data;
real pi;
}my_struct;
initial begin
my_struct.my_byte = 8'hab;
$display ("my_byte = %h, my_data = %2d, pi = %f", my_struct.my_byte, my_struct.my_data, my_struct.pi);
my_struct = '{0, 99, 3.14};
$display ("my_byte = %h, my_data = %2d, pi = %f", my_struct.my_byte, my_struct.my_data, my_struct.pi);
end
endmodule
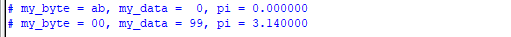
一个规律:
【’{ }】:动态数组、结构体都用到了,如果是非合并型、数据不是紧挨着存放的,都要用到
10. 常量
SV提供三个elaboration-time常量(parameter、localparam、specparam)和一个run-time常量(const)。每个参数必须在定义时给定初值;参数在elaboration的过程中设置(创建模块例化层次)并且保持该值直至整个程序执行结束。
// para_type_example
module ma
# (
parameter p1 = 1,
parameter type p2 = shortint
)
(
input logic [p1: 0] i,
output logic [p1: 0] o
);
p2 j = 0;
always @ (i) begin
o = i;
j++;
end
endmodule
module mb ( );
logic [ 3: 0] i, o;
ma #(
.p1(3),
.p2(int)
)
u1 (
.i(i),
.o(o)
);
endmodule
11. 文本表示
SV可以使用撇号(’)作为前缀,来说明一个文本的所有位可使用相同的数字来填充,如’0’、‘1’、‘z’、‘x’。在撇号(’)与值之间没有基数限定符,使得任何长度的向量不用显式地指定位宽就可以整体赋值,
bit [63: 0] data;
data = '1; // 设置数据地所有位为1















 1952
1952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









