









Faster R-CNN pytorch源码血细胞检测实战
文章目录
- Faster R-CNN pytorch源码血细胞检测实战
- 1、资源&参考
- 2、深度环境配置
- 3、训练代码运行
- 4 测试代码运行
- 5、代码运行过程中遇到的问题
- 5.1 fatal error C1083: 无法打开包括文件: “THC/THC.h”: No such file or directory
- 5.2 ImportError: cannot import name ‘_mask‘ from ‘pycocotools‘
- 5.3 ModuleNotFoundError: No module named 'imageio'
- 5.4 TypeError: load() missing 1 required positional argument: 'Loader'
- 5.5 assert all(max_classes[nonzero_inds] != 0)
- 5.6 4 errors detected in the compilation of...ROIAlign_cuda.cu
- 5.7 ImportError: DLL load failed: 找不到指定的程序。
- 5.8 ImportError: cannot import name 'imread' from 'scipy.misc'
- 5.9 FileNotFoundError: [Errno 2] No such file or directory: 'BloodImage_00007.xml'
- 5.10 测试AP值为0orMAP=0
- 5 总结
1、资源&参考
pytorch版 Faster R-CNN源码github仓库
BCCD数据集
参考博客1:faster rcnn训练自己的数据集(pytorch版)
参考博客2:使用pytorch版faster-rcnn训练自己数据集
参考博客3:用faster r-cnn训练自己的数据集(各种报错解决方法)
参考博客4:Faster RCNN pytorch 1.0版调试(踩坑)过程记录
十分感谢这些作者能够贡献出自己的资源和想法!!!
2、深度环境配置
基于win11+CUDA11.5+python3.7
首先需要安装anaconda3,具体参照这篇Anaconda超详细安装教程(Windows环境下)。
2.0 创建虚拟环境
打开Anaconda prompt,基于下行代码创建一个新的虚拟环境(我用的是python3.7,也可以改成其它版本的python):
conda create -n <环境名称> python=3.7
比如我,就是用的conda create -n rcnn python=3.7创建好了环境。
PS: 假如在后续的环境配置过程中,出现了错误,比如说安装的pytorch版本不对,或者包版本不兼容,或者其它莫名奇妙的问题,可以选择删了环境重建一个,然后重新配置(这真的很正常!!!)。可以参照这篇,基于下行代码删除你配置失败的环境:
conda remove -n <环境名称> --all
创建完虚拟环境之后,添加镜像源,镜像源是啥都懂吧,为了防止anaconda安装pytorch过慢或者失败,这里先设置清华源,里面的命令要一行一行执行。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro/
conda config --set show_channel_urls yes
然后,输入下行命令切换到你刚刚创建好的环境:
conda activate <环境名称>
2.1 pytorch-GPU版安装
2.1.1查看CUDA版本
首先,使用命令nvcc -V或nvidia-smi查看你的CUDA版本,按键win+R,输入cmd,打开命令行界面,如下所示,输入这两个代码查看你的CUDA版本:
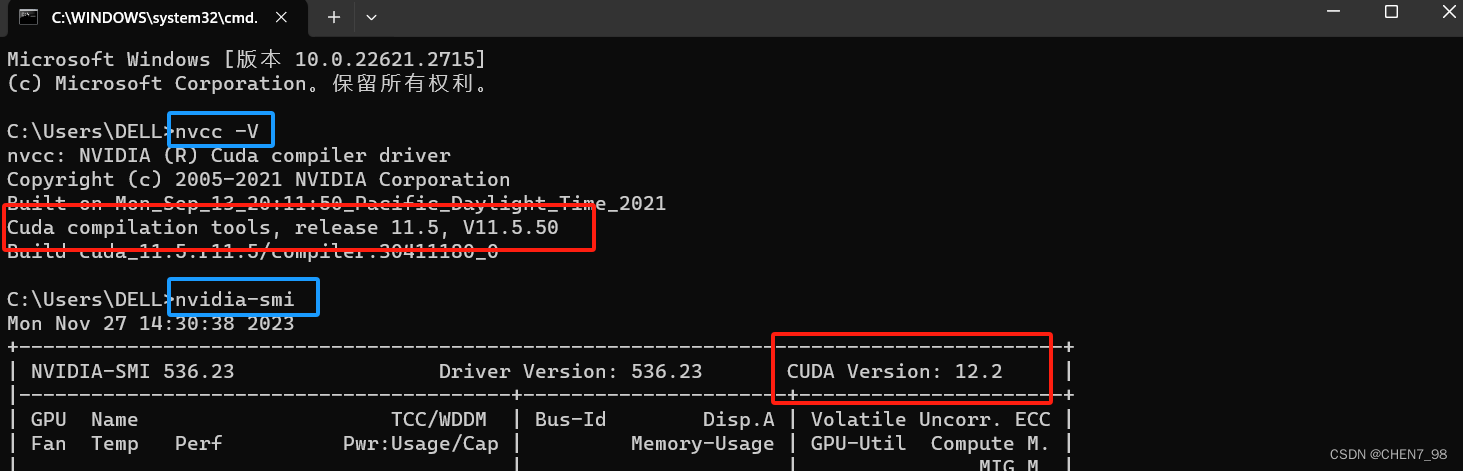
图中画红框的地方就是分别用两行命令得到的CUDA版本,一般来说,nvcc --version和nvidia-smi的版本可能会不一样,前者是runtime api对应的版本,后者是driver api的版本。 而对于pytorch-gpu,其版本通常需要和runtime的版本匹配,driver的版本可以向下兼容。
可以看到,我这里用nvcc -V查到的CUDA版本为11.5,因此需要安装对应版本的pytorch GPU版。
2.1.2安装pytorch gpu
现在我们已经创建好了虚拟环境对吧,然后也检查了CUDA版本,接下来就是安装pytorch gpu了。
在安装之前,我推荐参考我之前写的解决Anaconda3 solving environment 巨慢的方法,安装一个mamba。
因为使用conda命令在配置环境时,会首先搜索该环境下已经安装的所有包的版本,从而寻找一个最适合的版本来安装在虚拟环境中,这就会导致有时候你包装多了,搜索时间会巨长,一直卡在sovling environment这里。
这只是一个建议,不安装也没事,咱们就正常用conda和pip来安装需要的包。
正常安装pytorch gpu的流程
参照这篇Anaconda环境中PyTorch GPU版本安装(史上最全面,适用于新手的教程)
对于CUDA=11.5的用户及其它在pytorch官网找不到对应版本的用户
我参照的是这篇cuda11.5下载对应的的torch版本
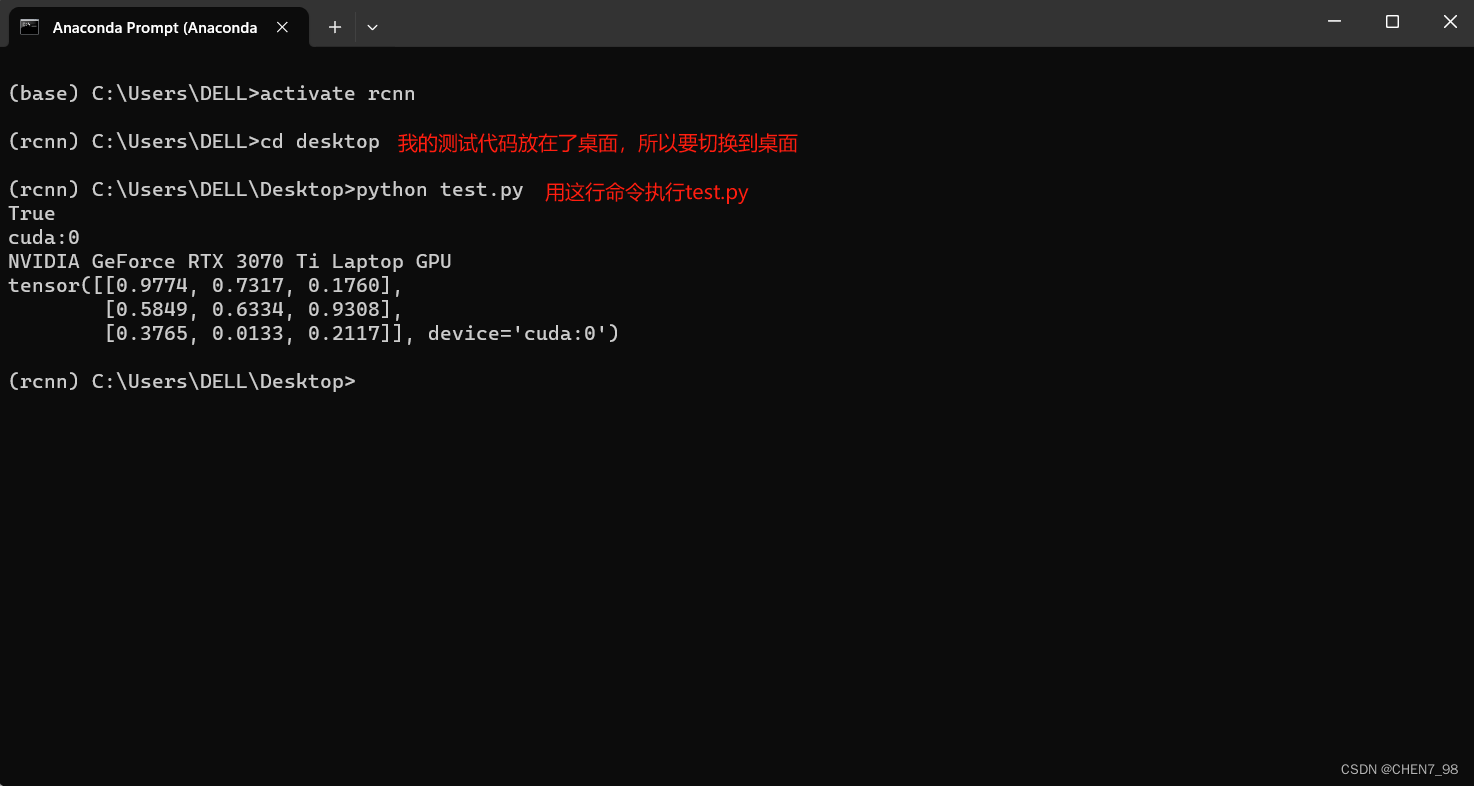
安装完成pytorch gpu版之后,激活当前虚拟环境,运行test.py测试是否安装成功,其内容如下所示:
import torch
flag = torch.cuda.is_available()
print(flag)
ngpu= 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3,3).cuda())
如果安装正确,会和我一样,如下图所示,显示显卡的信息:
3、训练代码运行
3.1 源码下载
- 首先进入pytorch版 Faster R-CNN源码github仓库,可以git clone,也可以直接下载zip包。
- 打开anaconda prompt,切换至刚刚创建好且安装了pytorch gpu的虚拟环境,将虚拟环境的当前目录切换到faster-rcnn.pytorch-pytorch-1.0,输入下行代码,安装必要的依赖包:
pip install -r requirements.txt
3.2 下载血细胞数据集
这里是我自己找的数据,密码为:t18o。其格式符合VOC2007数据集格式(这个很重要!)。
下载之后,解压即可。
3.3 创建文件夹
- 在faster-rcnn.pytorch-pytorch-1.0\目录下创建data和models文件夹,models文件夹可以在trainval_net.py文件中61行自定义,用于存放训练中保存的模型。
- 在faster-rcnn.pytorch-pytorch-1.0\data\目录下创建pretrained_model文件夹,用于存放resnet101_caffe.pth等预训练模型(这些预训练模型可以在网上下载,我用的resnet101)。
可以参照这篇Faster-RCNN.pytorch的搭建、使用过程详解(适配PyTorch 1.0以上版本) 中的第5点下载预训练模型。
下载完记得放在data\pretrained_model\目录下!!!! - 在faster-rcnn.pytorch-pytorch-1.0\data\目录下创建VOCdevkit2007文件夹,然后在该文件夹目录下创建VOC2007文件夹。
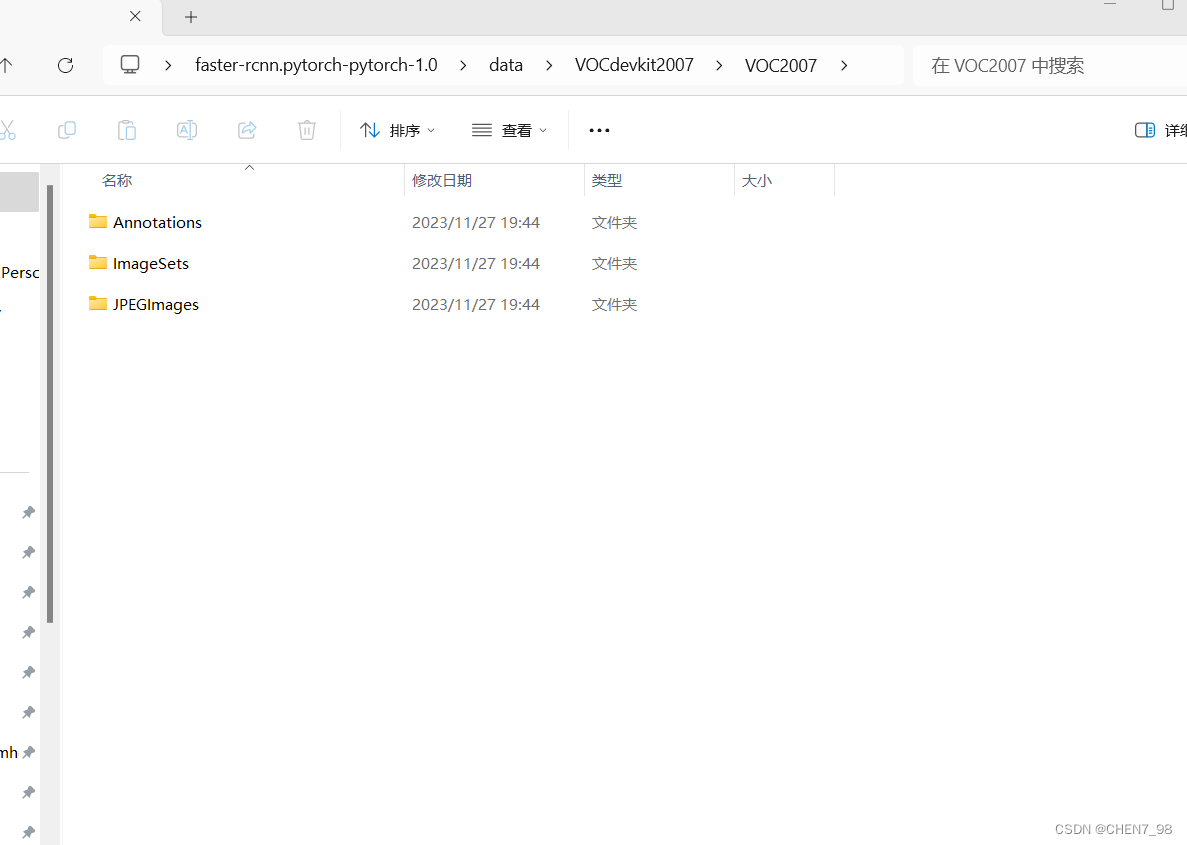
- 打开血细胞数据集的解压文件,将
Annotations、ImageSets、JPEGImages这三个文件夹复制到faster-rcnn.pytorch-pytorch-1.0\data\VOCdevkit2007\VOC2007\目录下,如下图所示:
3.4 修改源程序
- 修改faster-rcnn.pytorch-pytorch-1.0\lib\datasets\pascal_voc.py,修改后结果如下所示:
self._devkit_path = self._get_default_path() if devkit_path is None \
else devkit_path
self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year)
# self._classes = ('__background__', # always index 0
# 'aeroplane', 'bicycle', 'bird', 'boat',
# 'bottle', 'bus', 'car', 'cat', 'chair',
# 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant',
# 'sheep', 'sofa', 'train', 'tvmonitor')
# 血细胞数据集包含三类:RBC(红细胞)、WBC(白细胞)、血小板(Platelets)
# 注意这里必须要包含背景类
# 这里的标签名一定要和annotations文件夹下xml文件中的标签名对应(大小写也一样!)
self._classes = ('__background__','RBC', 'WBC', 'Platelets')
- 由于我的类别标签里面有大写,所以需要进行修改,参照Faster rcnn中训练AP=0问题和demo.py 运行后不显示检测图片问题,将
pascal_voc.py文件中的self._class_to_ind[obj.find(‘name’).text.lower().strip()中lower()去掉改成self._class_to_ind[obj.find(‘name’).text.strip()即可。 - 修改faster-rcnn.pytorch-pytorch-1.0\lib\roi_data_layer\目录下的minibatch.py,将其中的
from scipy.misc import imread更改为from imageio import imread,否则会出现ImportError: cannot import name ‘imread’ from 'scipy.misc...报错。 - 参照5.6的报错,进行修改!!!
3.5 编译
将虚拟环境的当前目录切换到faster-rcnn.pytorch-pytorch-1.0\lib\,输入下行指令,进行编译:
python setup.py build develop
3.6 训练模型
将虚拟环境的当前目录切换到faster-rcnn.pytorch-pytorch-1.0\,输入下行指令,开始训练:
python trainval_net.py --dataset pascal_voc --net res101 --epochs 50 --nw 1 --bs 1 --lr 0.0001 --cuda
训练的详细参数可以参考pytorch版 Faster R-CNN源码github仓库中的Readme.md文件。
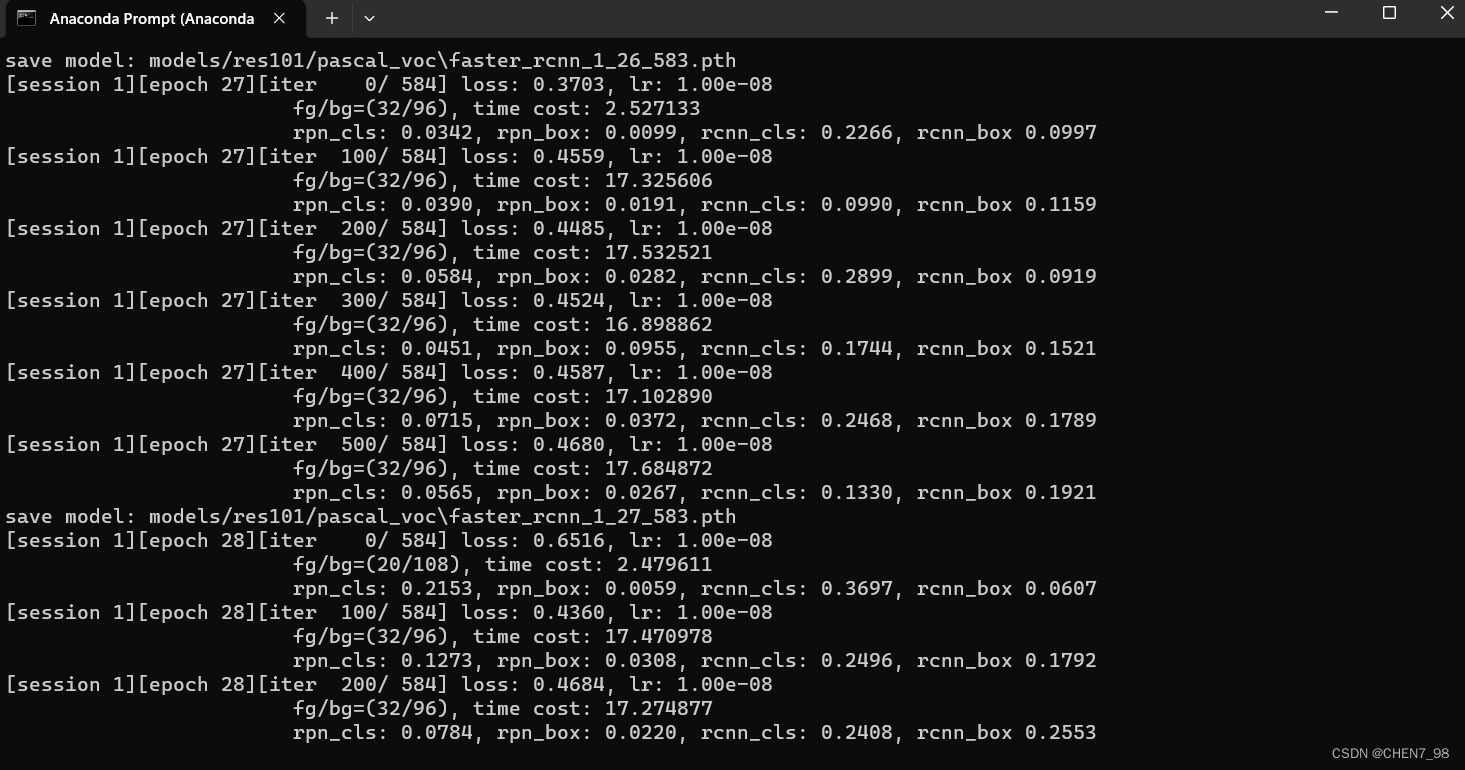
终于跑通了5555555555,训练界面如下所示55555555:
4 测试代码运行
4.1 源码修改
- 参照5.8的报错,进行修改,将demo.py中的
from scipy.misc import imread修改为from imageio import imread。 - 修改demo.py中的pascal_classes,如下所示:
# pascal_classes = np.asarray(['__background__',
# 'aeroplane', 'bicycle', 'bird', 'boat',
# 'bottle', 'bus', 'car', 'cat', 'chair',
# 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant',
# 'sheep', 'sofa', 'train', 'tvmonitor'])
# 血细胞数据集包含三类:RBC(红细胞)、WBC(白细胞)、血小板(Platelets)
# 注意这里必须要包含背景类
# 这里的标签名一定要和annotations文件夹下xml文件中的标签名对应(大小写也一样!)
pascal_classes = ('__background__','RBC', 'WBC', 'Platelets')
4.2 测试模型
完成训练之后的模型会存储在faster-rcnn.pytorch-pytorch-1.0\models\目录下,我这里用的resnet101,然后数据集名称是用的pascal_voc嘛,所以我最终训练好的模型就存储在faster-rcnn.pytorch-pytorch-1.0\models\res101\pascal_voc\目录下,如图所示,由于总共训练了50个epoch,所以会有50个模型:
注意看,模型的命名编号为1_{数字1}_{数字2},这个数字1代表是第几个epoch,对应的参数为checkepoch,数字2代表了第几个point,对应的参数为checkpoint。接下来,执行测试流程,比如说我想测试第50个epoch中,point为583的模型,那么我就会执行以下代码来实现对测试数据集的测试:
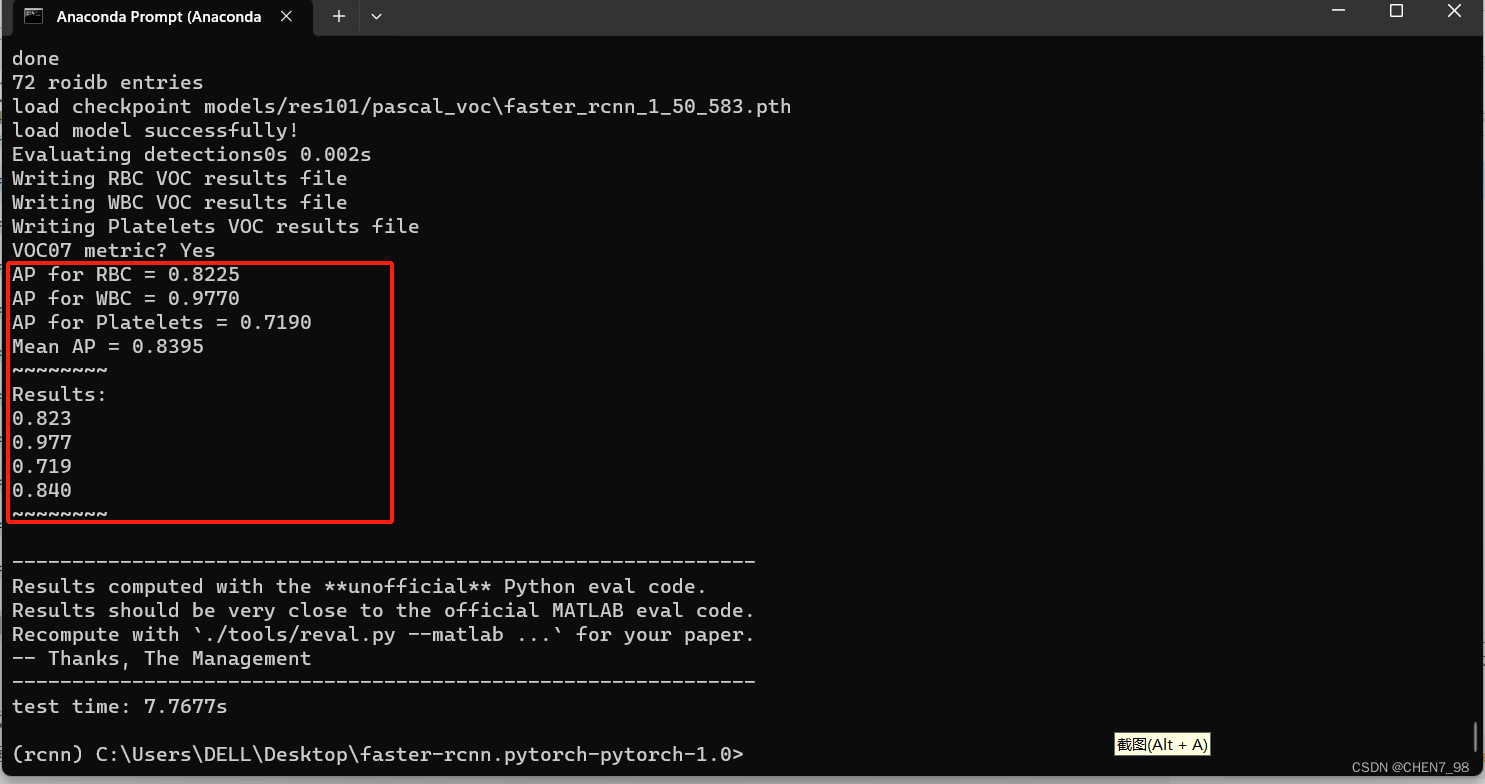
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 50 --checkpoint 583 --cuda
得到的测试结果如下所示:
4.3 目标检测
假如你需要应用训练好的模型对一些新的图片进行目标检测,可以直接将faster-rcnn.pytorch-pytorch-1.0\images\目录下原来的图片删除,然后放入你想检测的图片,比如我这里随机挑选了6张血细胞图片进行检测,输入下述命令即可:
python demo.py --net res101 --checksession 1 --checkepoch 50 --checkpoint 583 --cuda --load_dir models
原图为:
得到的结果为:
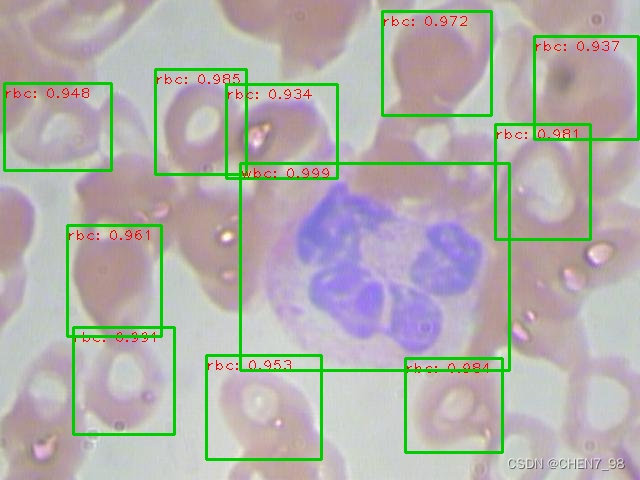
需要注意的是,每次检测的时候,之前检测好的名称中带有det的图片也会被检测,因此需要在新一次的检测开始前对其进行删除。
当然,也可以直接在faster-rcnn.pytorch-pytorch-1.0\目录下新建一个文件夹,比如我新建了一个文件夹,命名为testimg,那么我可以直接输入下行命令对其进行检测:
python demo.py --net res101 --checksession 1 --checkepoch 50 --checkpoint 583 --cuda --load_dir models --image_dir testimg
5、代码运行过程中遇到的问题
5.1 fatal error C1083: 无法打开包括文件: “THC/THC.h”: No such file or directory
原因是我本来装的torch是1.11的,但THC.h文件在Pytorch1.10版之后被移除了。
降低pytorch版本即可(推荐)。
或者参照这篇解决。
对于我而言,直接是降到了1.9版本的pytorch,在pytorch//previous-versions中基于下图所示的代码进行安装:
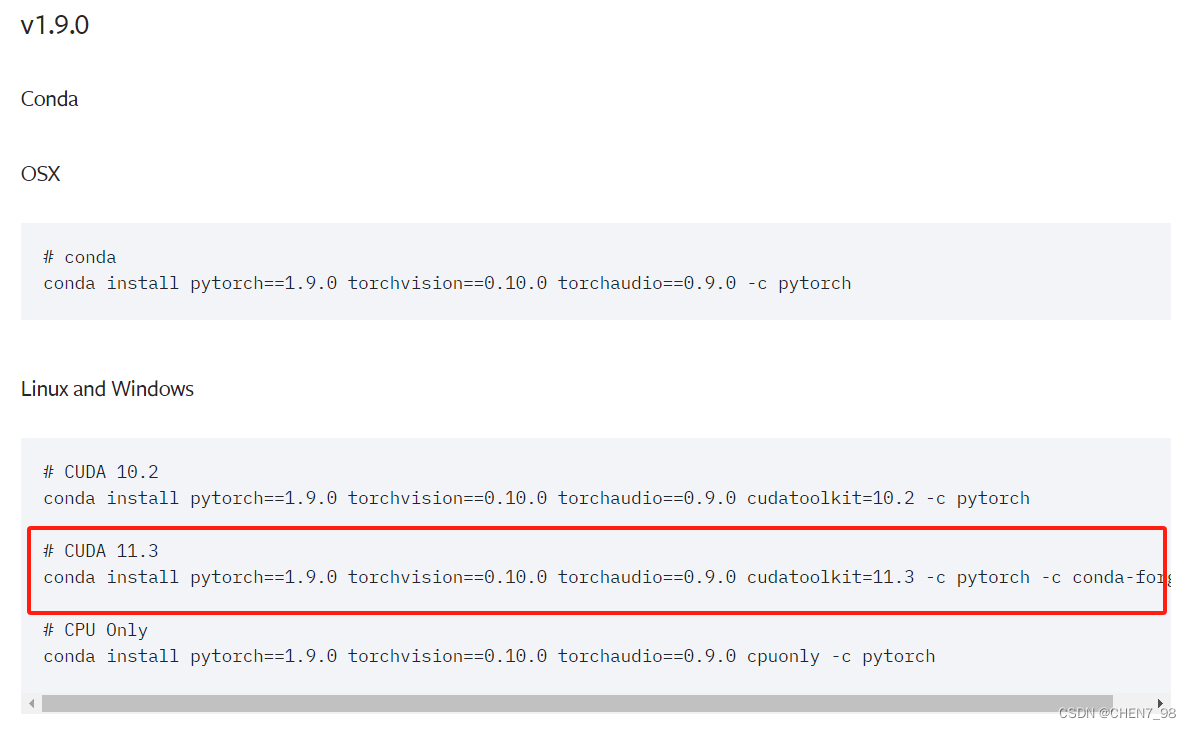
主要是没有CUDA=11.5对应的pytorch版本,所以无奈选择了CUDA=11.3对应的1.9版本pytorch进行安装,如下所示:
conda install pytorch==1.9.0 torchvision==0.10.0 torchaudio==0.9.0 cudatoolkit=11.3 -c pytorch -c conda-forge
坏!我发现上面装的好像是不是gpu的版本,那么还是参照这篇cuda11.5下载对应的的torch版本进行安装,安装选择的是CUDA=11.3对应的pytorch1.10。
5.2 ImportError: cannot import name ‘_mask‘ from ‘pycocotools‘
这里我参考了这篇pycocotools踩坑(ImportError: cannot import name ‘_mask‘ from ‘pycocotools‘)(No module named pycocotoo)和这篇[已解决]ImportError: cannot import name ‘_mask‘以及这篇错误:cl: 命令行 error D8021 :无效的数值参数“/Wno-cpp”
主要做法为:
-
首先到cocoapigithub仓库下载源码,并进行解压。
-
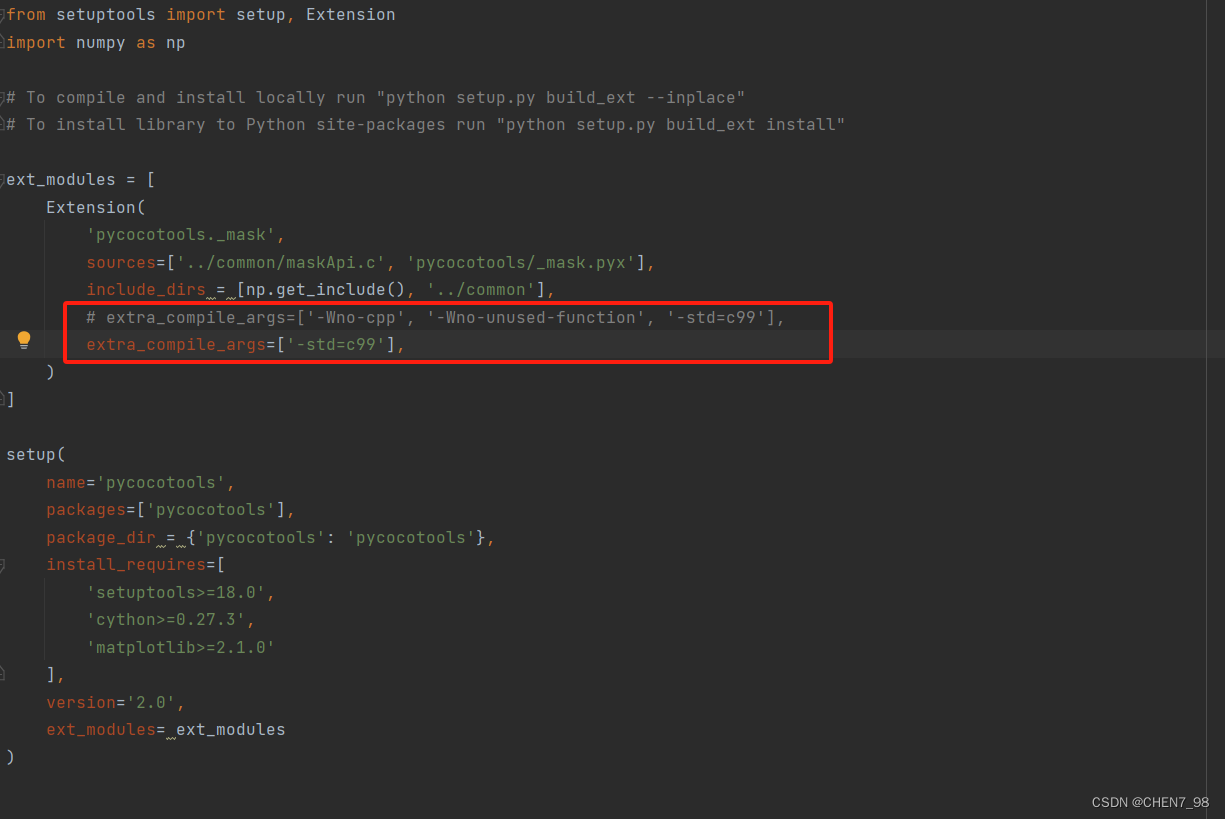
打开cocoapi-master\PythonAPI目录,双击打开setup.py文件,将其中的
extra_compile_args=['-Wno-cpp', '-Wno-unused-function', '-std=c99'],修改为extra_compile_args=['-std=c99'],,如下图所示:
-
然后以管理员身份运行anaconda prompt,切换到用于跑代码的虚拟环境(例如我的是名为rcnn的虚拟环境)。在虚拟环境中,切换到 cocoapi\PythonAPI目录,然后运行以下两行指令:
# install pycocotools locally
python setup.py build_ext --inplace
# install pycocotools to the Python site-packages
python setup.py build_ext install
- 之后,在编译好的cocoapi文件夹中找到pycocotools(cocoapi/PythonAPI/pycocotools),复制pycocotools下的全部内容,替换掉faster-rcnn/lib/pycocotools下的全部内容。
- 最后,将虚拟环境的当前目录切换到faster-rcnn.pytorch-pytorch-1.0\lib,重新运行命令
python setup.py build develop即可,之后就可以正常跑训练了!
5.3 ModuleNotFoundError: No module named ‘imageio’
直接安装这个包即可,用如下指令:
pip install imgaug
5.4 TypeError: load() missing 1 required positional argument: ‘Loader’
参照这篇TypeError: load() missing 1 required positional argument: ‘Loader‘,降低pyyaml的版本至5.4.1即可。
5.5 assert all(max_classes[nonzero_inds] != 0)
清理faster-rcnn.pytorch-pytorch-1.0\data\cache\目录下的文件即可。
5.6 4 errors detected in the compilation of…ROIAlign_cuda.cu
参照这篇中提到的,进入这个网址,然后打开faster-rcnn.pytorch-pytorch-1.0\lib\model\csrc\cuda\目录下的ROIAlign_cuda.cu和ROIPool_cuda.cu文件,参照这个网址中提到的,将dim3 grid(std::min(THCCeilDiv(output_size, 512L), 4096L));和dim3 grid(std::min(THCCeilDiv(grad.numel(), 512L), 4096L));代码进行修改,并在前面添加如下代码:
int ceil_div(int a, int b){
return (a + b - 1) / b;
}
5.7 ImportError: DLL load failed: 找不到指定的程序。
参照这篇博客win10下安装基于caffe的 Faster-Rcnn中提到的方法试了一下没用,然后重新编译发现编译不通过(为啥会突然编译不通过呢?应该是因为我大量地重新安装环境,所以导致此时新装的环境无法通过编译,因此这里会缺少模块,所以就重新编译,然后遇到了5.6提到的问题,对后缀为cu的代码修改后就能够运行了!!!
5.8 ImportError: cannot import name ‘imread’ from ‘scipy.misc’
在测试代码时,运行demo.py时报了这个错误,可以参照前面写的3.4小节的第二点,将demo.py中的from scipy.misc import imread更改为from imageio import imread即可。
5.9 FileNotFoundError: [Errno 2] No such file or directory: ‘BloodImage_00007.xml’
参照这个issue和的解决方法,将pascal_voc.py中的下列代码更改:
# before
def _do_python_eval(self, output_dir='output'):
annopath = os.path.join(
self._devkit_path,
'VOC' + self._year,
'Annotations',
'{:s}.xml')
...
# after
def _do_python_eval(self, output_dir='output'):
annopath = os.path.join(
self._devkit_path,
'VOC' + self._year,
'Annotations',
'{}.xml')
...
5.10 测试AP值为0orMAP=0
本来死活找不到为什么测试AP值为0的原因,用demo.py跑了一下对测试图片的检测效果,发现能检测到,但是算出来的AP值还是为0,说明不是检测的问题,而是在计算过程中出现了问题。后面参考了这篇Faster rcnn中训练AP=0问题和demo.py 运行后不显示检测图片问题,发现是自己在pascal_voc.py中的标签设置有问题,大小写没有和annotations中的xml文件对应好,因此改成如下形式即可以正确计算AP值:
# pascal_classes = np.asarray(['__background__',
# 'aeroplane', 'bicycle', 'bird', 'boat',
# 'bottle', 'bus', 'car', 'cat', 'chair',
# 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant',
# 'sheep', 'sofa', 'train', 'tvmonitor'])
pascal_classes = ('__background__','RBC', 'WBC', 'Platelets')
5 总结
太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了太不容易了从下午配到天黑😭😭😭😭😭,很感激本文中提到的所有文章的作者,也感谢源代码的作者!!!小白配环境千万不要着急,遇到问题多bing多google,这个源代码仓库几千的fork,你遇到的问题肯定大家都遇到过!!
在本文的基础上,对血细胞数据进行数据增强,请参考Faster R-CNN pytorch源码血细胞检测实战(二)数据增强。
能不能直接三连了😭😭😭














 2532
2532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









