







优化cuda中GEMM Kernel性能并接近cublas(一)
文章目录
文章目的
本篇文章主要是介绍在GPU中,如何一步一步写cuda代码优化矩阵乘法(GEMM)。
目前对于GEMM的优化,网上已经有非常多的教程和示例,我也相继看了不少,因此,我想结合网上大部分教程资料,以及自己在学习过程中的理解,写下这篇文章。
尽可能地去把GPU中的GEMM优化过程一步一步说明清楚,也是对自己在学习过程中总结与回顾,并且希望能够帮助其他人不要陷入疯狂找资料的耗时中,能够快速的找到相关资料进行学习。
前言
在当今人工智能迅速发展,如何让大模型推理更快逐渐成了人工智能时代一个非常重要的难题。其中矩阵乘法作为大模型中最基础的算子,广泛的应用于模型最耗时的卷积层,全连接层,attention层以及各种衍生的attention层和卷积层中,因此对于优化GEMM极大重要性毋庸置疑。
本文主要是综合各类资料中优化思路,按照自己的理解撰写代码。因此主要从两个方面进行优化分析:
- 如何减少GPU中多级存储结构上的访存次数以及如何减少申请读取内存请求事务次数,从提高访存效率。
- 如何尽可能隐藏访存时延,从而提高计算访存比
前提假设
有矩阵A,B,分别维度为m x k,k x n,进行矩阵乘法计算后得到矩阵C,其维度是m x n。且这三个矩阵中的数据都是单精度浮点数float32。
一、Baseline(cublas官方版)
本文主要是采用cublas官方的cublassSgem核函数计算的时间以及每秒计算次数GFlop/s作为优化的基线Baseline。
这里不多赘述关于cublas中API介绍,代码如下:
#include <cublas_v2.h>
void baseline(float *matrix_a, float *matrix_b, float *matrix_c, int m, int n, int k){
cublasHandle_t blas_handle;
cublasCreate(&blas_handle);
float *d_a, *d_b, *d_c;
cudaMalloc((void **)&d_a, m*k*sizeof(float));
cudaMalloc((void **)&d_b, k*n*sizeof(float));
cudaMalloc((void **)&d_c, m*n*sizeof(float));
cudaMemcpy(d_a, matrix_a, m*k*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, matrix_b, k*n*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_c, matrix_c, k*n*sizeof(float), cudaMemcpyHostToDevice);
float alpha = 1.0f;
float beta = 0.5f;
cublasSgem(blas_handle, CUBLAS_OP_T, CUBLAS_OP_T, M, N, K, &aplha, d_a, K, d_b, N, &beta, d_c, N);
cudaMemcpy(matrix_c, d_c, m*n*sizeof(float), cudaMemcpyHostToDevice);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cublasDestroy(handle);
}
二、Naive GEMM Kernel
在假设中,对于C中每一个元素,C[i][j],可以看作是A的一行和B的一列进行一次归约操作。采用最naive的GEMM算法,在GPU中,一共开启mn个线程,每个block负责C中对应的bmbn一小块计算,每个线程需要读取矩阵A的一行与矩阵B的一列,而后将计算结果写回至矩阵C中。因而,完成计算一共需要从global memory中进行2mnk次读操作和mn次写操作。
一个block负责bm*bn个结果计算,block中一个线程负责一个结果的计算。其示意图如下:
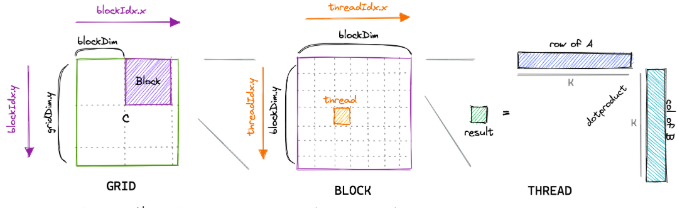
代码如下:
__global__ void naive_Kernel_MM(float *matrix_a, float *matrix_b, float *matrix_c, int M, int N, int K, float alpha, float beta){
size_t tx = blockDim.x * blockIdx.x + threadIdx.x;
size_t ty = blockDim.y * blockIdx.y + threadIdx.y;
float sum = 0.f; // 4kb
for(int k = 0; k < K; k++){
sum += matrix_a[tx * K + k] * matrix_b[k * N + ty];
}
matrix_c[tx * M + ty] = alpha * sum + beta * matrix_c[tx * M + ty];
}
naive版本的矩阵乘法中,大量的访存操作都是在全局内存存储级上进行的,而全局内存的访问时间是较长的耗时,重复性的读写会大大的降低访存效率。
三、Shared Memory访存数据优化
从提高访存效率方面进行优化,考虑到GPU存储结构,共享内存相较于全局内存的访问时延短,因此,我们不妨利用GPU中共享内存,将部分数据先从全局内存读取到共享内存上,然后在对共享内存上的部分数据进行子矩阵乘法,再写回到全局内存中。
不妨设,子矩阵A,子矩阵B和子矩阵C的维度分别为(bm,bk), (bk, bn), (bm, bn)。(这里bm和bn也就是naive版本中block的大小),因此完成C需要从全局内存中读取2mnk次减少到m/bm * n/bn * k/bk * (bm * bk + bn * bk) = mnk(1/bm+1/bn) 次。相比于之前naive版本这里减少了原来的1/2 * (1/bm + 1/bn)倍。
将小矩阵存储到共享内存当中后,计算单元进行重复行读取重复列读取,则可以直接从共享内存中取数,大大减少了访存所需要的时延,从而提高了访存效率。
示意图如下:
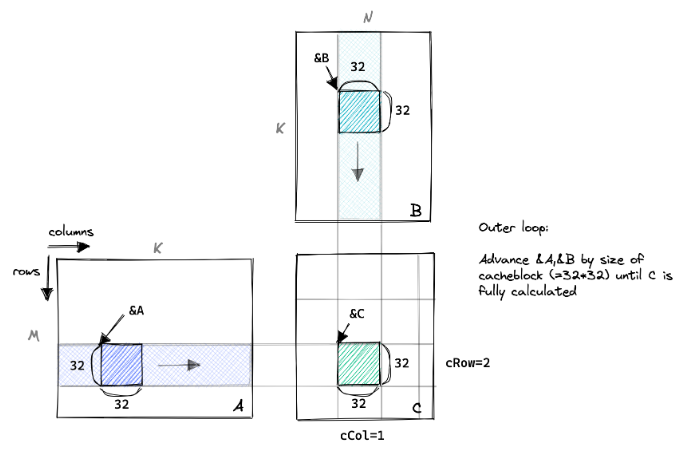
按照官方文档,如果SM中的占用率过低会导致性能下降,且一个block是管理自己共享内存的一部分。如果一个block所管理的共享内存过大,会导致SM中激活的block数量过少,从而导致SM占用率过低导致性能也会下降,因此,合适的共享内存大小使用也能改变性能提升。代码如下:
template <size_t BM, size_t BN, size_t BK>
__global__ void shared_memory_Kernel_MM(float *matrix_a, float *matrix_b, float *matrix_c, int M, int N, int K, float alpha, float beta)
{
// 申请共享内存空间
__shared__ float sm_matrix_a[BM*BK];
__shared__ float sm_matrix_b[BK*BN];
size_t tx = threadIdx.x % BN;
size_t ty = threadIdx.y / BN;
// A,B,C矩阵移动到当前block下的位置,大迭代BLOCK索引再A,B,C中起始位置
matrix_a += BM * blockIdx.y * K;
matrix_b += BN * blockIdx.x;
matrix_c += BM * blockIdx.y * N + BN * blockIdx.x;
float sum = 0.f;
// 小迭代BLOCK中共享内存计算的A,B矩阵中起始位置
for(int k = 0; k < K; k+=BK){
// 将全局内存上数据加载到共享内存上
sm_matrix_a[ty * BK + tx] = matrix_a[ty * K + tx];
sm_matrix_b[ty * BN + tx] = matrix_b[ty * N + tx];
__syncthreads();
matrix_a += BK;
matrix_b += BK * N;
for(int i = 0; i < BK; i++){
sum += sm_matrix_a[ty * BK + i] * sm_matrix_b[i * BN + tx];
}
__syncthreads();
}
matrix_c[ty * N + tx] = alpha * sum + beta * matrix_c[ty * N + tx];
}
四、Thread Tile计算及Register访存优化
从提高计算访存比以及隐藏访存时延的角度思考,首先,在共享内存版本的基础上,依旧是一个线程处理一个数据,这样的计算访存比是1/k+k+2=1/2k+2, 但是如果一个线程处理四个数据,这样的计算访存比则是4/k+k+4=2/k+2,明显在原来一个线程处理一个数据的基础上,提升了不少。
其次,虽然共享内存相比全局内存能够大大减少访存时延,但是共享内存时延(几十cycle)相比于计算时延(几个cycle)仍然比较大,因此考虑到GPU存储结构中寄存器的存在,利用一个线程管理的寄存器分块读取共享内存中的数据,再进行计算,从而减少了对共享内存的重复访问,又降低了访存时延。访存量计算:
一个block中读取shared memory本身访存量是2 * bm * bn * bk,block中每个线程负责一个rm * rn子矩阵计算后, 一个block需要负责bm/rm * bn/rn个子矩阵,则访存量变成了bm/rm * bn/rn * bk * (rm + rn) = bm * bn * bk * (1/rm + 1/rn),相比于原来访存量减少了1/2 * (1/rm+ 1/rn)倍。
因此一个block中一个线程,负责共享内存中rm*rn又一个小矩阵的计算,并利用寄存器进行缓存,这样大大提高了计算效率又掩盖了访存时延,示意图如下:
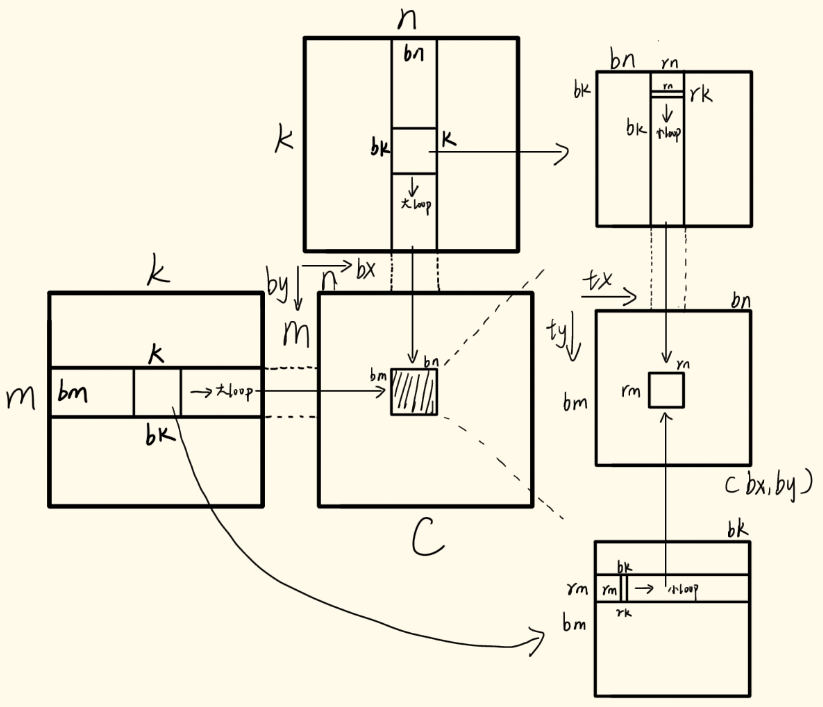
从提高计算访存比的角度:上面示意图可以看出,按照共享内存版本中一个block计算虽然是bm*bn个结果,但是考虑共享内存大小问题,需要循环的计算向量乘法中一部分结果再逐步相加,同理按照一个线程负责bm*bn中rm*rn个结果,则是对共享内存进行分块,从图中可以看出,当一个线程按列读取bm*bk矩阵和按行读取bk*bn矩阵中rm*rk 和 rk*rn时,这里我们假设rk等于1,线程取rm+rn个数据,而计算的结果是rm*rn个,很明显对于计算访存比是相当大,再采用循环逐步相加后,最终得到rm*rn的正确值。
又由于寄存器有限的问题,如果一个block中使用的寄存器
代码如下:
template <const int BLOCK_SIZE_M, const int BLOCK_SIZE_N, const int BLOCK_SIZE_K, const int THREAD_SIZE_M, const int THREAD_SIZE_N>
__global__ void thread_tile_register_Kernel_MM(float *matrix_a, float *matrix_b, float *matrix_c, int M, int N, int K)
{
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
const int tid = ty * blockDim.x + tx;
// 统计一个block中计算需要的线程总数 == rm * rn有多少块
int thread_nums = (BLOCK_SIZE_M / THREAD_SIZE_M) * (BLOCK_SIZE_N / THREAD_SIZE_N);
int A_TILE_COL = tid % BLOCK_SIZE_K;
int A_TILE_ROW = tid / BLOCK_SIZE_K;
int A_TILE_ROW_STRIDE = thread_nums / BLOCK_SIZE_K;
int B_TILE_COL = tid % BLOCK_SIZE_N;
int B_TILE_ROW = tid / BLOCK_SIZE_N;
int B_TILE_ROW_STRIDE = thread_nums / BLOCK_SIZE_N;
// 申请共享内存空间
// 考虑到一个线程负责rm*rn个计算结果式读取A中一列rm和读取B中一行rn计算所得,因此不妨对A进行进行一次转置后再读取
__shared__ float sm_A_matrix[BLOCK_SIZE_K][BLOCK_SIZE_M]; // bm * bk
__shared__ float sm_B_matrix[BLOCK_SIZE_K][BLOCK_SIZE_N]; // bk * bn
float reg_a[THREAD_SIZE_M]; // rm
float reg_b[THREAD_SIZE_N]; // rn
/*
###### first loop ######
A,B,C矩阵让指针指向对于block中处理的数据最初开头位置的地址
*/
matrix_a += by * BLOCK_SIZE_M * K;
matrix_b += bx * BLOCK_SIZE_N;
matrix_c += by * BLOCK_SIZE_M * N + bx * BLOCK_SIZE_N;
// 申请寄存器空间用于保存rm*rn的结果
float sum[THREAD_SIZE_M][THREAD_SIZE_N] = {0.f};
/*
###### second loop ######
加载数据到共享内存上
load_to_sm(SA, A, bm*bk)
load_to_sm(SB, A, bk*bn)
*/
#pragma unroll
for(int bk = 0; bk < K; bk += BLOCK_SIZE_K){
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_M; i+=A_TILE_ROW_STRIDE){
sm_A_matrix[A_TILE_COL][A_TILE_ROW + i] = matrix_a[(i + A_TILE_ROW) * K + A_TILE_COL];
}
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_K; i+=B_TILE_ROW_STRIDE)
{
sm_B_matrix[B_TILE_ROW + i][B_TILE_COL] = matrix_b[(i + B_TILE_ROW) * N + B_TILE_COL];
}
__syncthreads();
matrix_a += BLOCK_SIZE_K;
matrix_b += BLOCK_SIZE_K * N;
/*
###### third loop ######
加载数据到寄存器上
load_to_reg(reg_a, SA, rm*rk)
load_to_reg(reg_b, SB, rk*rn)
*/
#pragma unroll
for (int i = 0; i < BLOCK_SIZE_K; i++){
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm++){
reg_a[rm] = sm_A_matrix[i][rm + ty * THREAD_SIZE_M];
}
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn++){
reg_b[rn] = sm_B_matrix[i][rn + tx * THREAD_SIZE_N];
}
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm++){
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn++){
sum[rm][rn] += reg_a[rm] * reg_b[rn];
}
}
}
__syncthreads();
}
// 存储计算结果矩阵C中
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm++){
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn++){
matrix_c[(ty * THREAD_SIZE_M + rm) * N + tx * THREAD_SIZE_N + rn] = sum[rm][rn];
}
}
}
代码中A_TILE_COL表示block中某个线程读取A矩阵中列的索引,A_TILE_ROW表示block中读取A矩阵中某个线程读取的行索引,A_TILE_ROW_STRIDE表示一个block中所有线程读取A矩阵中多少行,对于B矩阵同理。当读取到共享内存当中后,再逐个读取数据到寄存器当中,示意图如下:
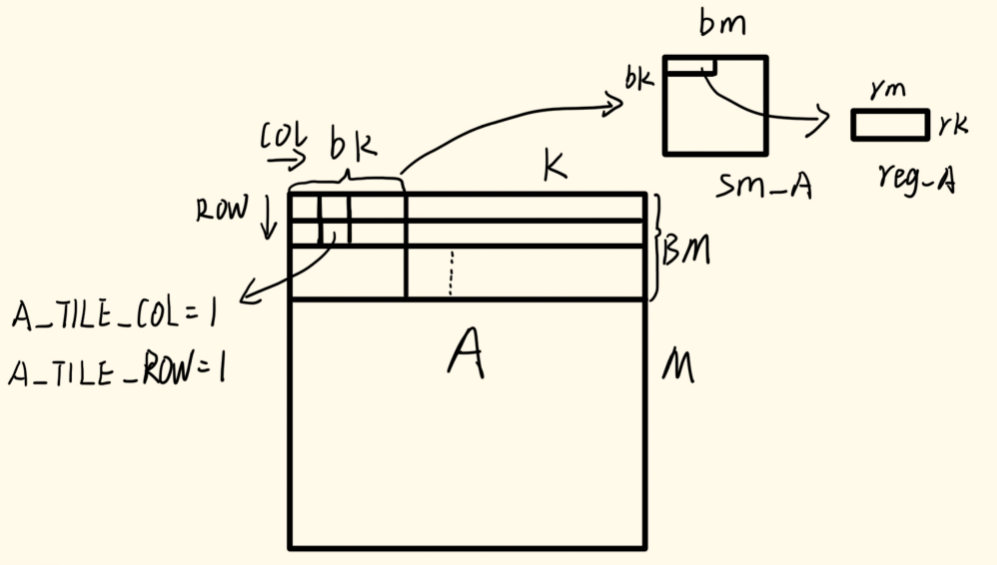
BLOCK_SIZE_M循环读取A矩阵时,以A_TILE_ROW_STRIDE为步长读取行。
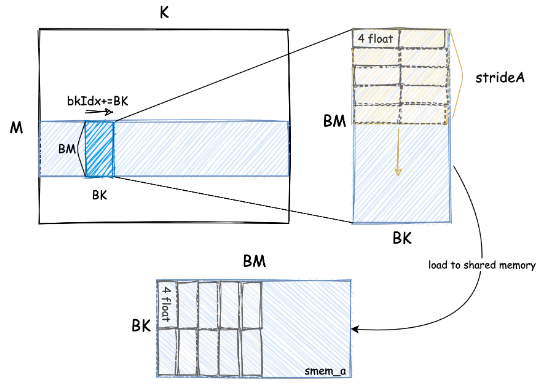
五、FLOAT4向量化减少申请内存事务优化
合并访存从而减少申请内存事务角度分析:在上述的共享内存、寄存器优化访存时延以及thread tile优化计算访存比当中,一个线程虽然可以计算多个结果,但是在读取时却只能将一个一个数据读取到共享内存,寄存器当中,且只能将一个一个数据读取出来进行计算,这样效率是非常低,且指令数量也非常多,我们能否减少这些读取数据的指令数量呢?
这就要利用LDS.128指令用于多个数据同时读取的指令,而这个指令往往在程序中以向量化数据类型的形式表达。
由于是考虑的是单精度浮点数floa32计算,一个数据占32位,LDS.128一个指令只能读4个float32,因此通过C++中强制类型转换,对内存地址进行LDS.128数据对齐,每次获取以4个float32为组的首地址位置。这一个指令就可以减少多个指令对多个数据的访存,从实现合并访存的思路,示意图如下:
代码在上述的基础上优化如下:
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0])
template <const int BLOCK_SIZE_M, const int BLOCK_SIZE_N, const int BLOCK_SIZE_K, const int THREAD_SIZE_M, const int THREAD_SIZE_N>
__global__ void float4_Kernel_MM(float *matrix_a, float *matrix_b, float *matrix_c, int M, int N, int K)
{
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
const int tid = ty * blockDim.x + tx;
// 统计一个block中计算需要的线程总数 == rm * rn有多少块
const int thread_nums = (BLOCK_SIZE_M / THREAD_SIZE_M) * (BLOCK_SIZE_N / THREAD_SIZE_N);
// ldg_a_num表示所有线程需要经过多少论文采用FLOAT4向量加载数据,才能A中数据添加到共享内存中
const int ldg_a_num = (BLOCK_SIZE_M * BLOCK_SIZE_K / thread_nums / 4);
const int ldg_b_num = (BLOCK_SIZE_N * BLOCK_SIZE_K / thread_nums / 4);
int A_TILE_COL = tid % (BLOCK_SIZE_K / 4) * 4; // 每个线程读取的列索引
int A_TILE_ROW = tid / (BLOCK_SIZE_K / 4); // A的子矩阵BA中线程读取的行索引, 由于现在(BLOCK_SIZE_K / 4)个线程一行读取,则应该除以(BLOCK_SIZE_K / 4)
int A_TILE_ROW_STRIDE = BLOCK_SIZE_M / ldg_a_num; // 每轮搬运多少行
int B_TILE_COL = tid % (BLOCK_SIZE_N / 4) * 4;
int B_TILE_ROW = tid / (BLOCK_SIZE_N / 4);
int B_TILE_ROW_STRIDE = BLOCK_SIZE_K / ldg_b_num;
// 申请共享内存空间
// 考虑到一个线程负责rm*rn个计算结果式读取A中一列rm和读取B中一行rn计算所得,因此不妨对A进行进行一次转置后再读取
__shared__ float sm_A_matrix[BLOCK_SIZE_K][BLOCK_SIZE_M]; // bm * bk
__shared__ float sm_B_matrix[BLOCK_SIZE_K][BLOCK_SIZE_N]; // bk * bn
// 由于A需要转置,存储的位置不是连续对齐位置,不能直接使用对齐的形式存储
// 4 * ldg_a_num确保最最多4轮搬运完成
float ldg_a_reg[4 * ldg_a_num] = {0.f};
float reg_a[THREAD_SIZE_M]; // rm
float reg_b[THREAD_SIZE_N]; // rn
/*
###### first loop ######
A,B,C矩阵让指针指向对于block中处理的数据最初开头位置的地址
*/
matrix_a += by * BLOCK_SIZE_M * K;
matrix_b += bx * BLOCK_SIZE_N;
matrix_c += by * BLOCK_SIZE_M * N + bx * BLOCK_SIZE_N;
// 申请寄存器空间用于保存rm*rn的结果
float sum[THREAD_SIZE_M][THREAD_SIZE_N] = {0.f};
/*
###### second loop ######
加载数据到共享内存上
load_to_sm(SA, A, bm*bk)
load_to_sm(SB, A, bk*bn)
*/
#pragma unroll
for(int bk = 0; bk < K; bk += BLOCK_SIZE_K){
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_M; i+=A_TILE_ROW_STRIDE){
int ldg_index = i / A_TILE_ROW_STRIDE;
FLOAT4(ldg_a_reg[ldg_index]) = FLOAT4(matrix_a[(i + A_TILE_ROW) * K + A_TILE_COL]);
sm_A_matrix[A_TILE_COL + 0][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 0];
sm_A_matrix[A_TILE_COL + 1][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 1];
sm_A_matrix[A_TILE_COL + 2][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 2];
sm_A_matrix[A_TILE_COL + 3][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 3];
}
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_K; i+=B_TILE_ROW_STRIDE)
{
FLOAT4(sm_B_matrix[B_TILE_ROW + i][B_TILE_COL]) = FLOAT4(matrix_b[(i + B_TILE_ROW) * N + B_TILE_COL]);
}
__syncthreads();
matrix_a += BLOCK_SIZE_K;
matrix_b += BLOCK_SIZE_K * N;
/*
###### third loop ######
加载数据到寄存器上
load_to_reg(reg_a, SA, rm*rk)
load_to_reg(reg_b, SB, rk*rn)
*/
#pragma unroll
for (int i = 0; i < BLOCK_SIZE_K; i++){
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm+=4){
FLOAT4(reg_a[rm]) = FLOAT4(sm_A_matrix[i][rm + ty * THREAD_SIZE_M]);
}
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn+=4){
FLOAT4(reg_b[rn]) = FLOAT4(sm_B_matrix[i][rn + tx * THREAD_SIZE_N]);
}
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm++){
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn++){
sum[rm][rn] += reg_a[rm] * reg_b[rn];
}
}
}
__syncthreads();
}
// 存储计算结果矩阵C中
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm++){
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn+=4){
FLOAT4(matrix_c[(ty * THREAD_SIZE_M + rm) * N + tx * THREAD_SIZE_N + rn]) = FLOAT4(sum[rm][rn]);
}
}
}
其中对于读取A矩阵到共享内存上时,进行了一次转置,是为了在读取共享内存到寄存器中时,能够保证数据的连续性读取,这样对齐数据式地读取才能够让编译器采用LDS.128指令,不然如果按行读取四个会导致LDS.128指令无法使用。
六、Double Buffering高效并行访存优化
从并行优化访存和计算角度分析:在上述所有程序中,计算和访存在时间轴上并不是重叠的形式,而是串行的形式。
在GPU中从全局内存中访存实际上是非常慢的,而这样的访存延时虽然可以通过SM对激活的block进行上下文切换来掩盖,但由于一个block中分配的共享内存较大,每个SM共享内存有有限,从而容易导致激活的block数量并不太多,最终这种延时很难被掩盖。
对于一个thread,需要计算一个的小矩阵,但是必须先将数据从共享内存传到寄存器上,才能开始进行计算。所以导致了每进行一次迭代,计算单元就需要停下来等待数据加载完成。
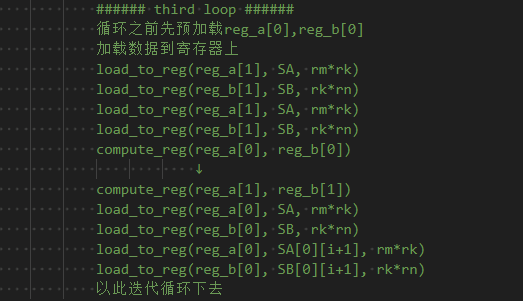
为了缓解上面的问题,需要通过double buffering预取的形式来尽可能地掩盖数据加载的延时。思路是:
申请两块共享内存sm[0]和sm[1]以及两块用于计算缓存的寄存器reg,以及两块用于访存缓存的寄存器ldg_reg。
- 共享内存的迭代角度:

- 寄存器的迭代角度:
template <const int BLOCK_SIZE_M, const int BLOCK_SIZE_N, const int BLOCK_SIZE_K, const int THREAD_SIZE_M, const int THREAD_SIZE_N>
__global__ void double_buffer_Kernel_MM(float * __restrict__ matrix_a, float * __restrict__ matrix_b, float * __restrict__ matrix_c, int M, int N, int K)
{
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
const int tid = ty * blockDim.x + tx;
// 统计一个block中计算需要的线程总数 == rm * rn有多少块
const int thread_nums = (BLOCK_SIZE_M / THREAD_SIZE_M) * (BLOCK_SIZE_N / THREAD_SIZE_N);
// ldg_a_num表示所有线程需要经过多少论文采用FLOAT4向量加载数据,才能A中数据添加到共享内存中
const int ldg_a_num = BLOCK_SIZE_M * BLOCK_SIZE_K / thread_nums / 4;
const int ldg_b_num = BLOCK_SIZE_N * BLOCK_SIZE_K / thread_nums / 4;
const int A_TILE_COL = tid % (BLOCK_SIZE_K / 4) * 4; // 每个线程读取的列索引
const int A_TILE_ROW = tid / (BLOCK_SIZE_K / 4); // A的子矩阵BA中线程读取的行索引, 由于现在(BLOCK_SIZE_K / 4)个线程一行读取,则应该除以(BLOCK_SIZE_K / 4)
const int A_TILE_ROW_STRIDE = BLOCK_SIZE_M / ldg_a_num; // 每轮搬运多少行
const int B_TILE_COL = tid % (BLOCK_SIZE_N / 4) * 4;
const int B_TILE_ROW = tid / (BLOCK_SIZE_N / 4);
const int B_TILE_ROW_STRIDE = BLOCK_SIZE_K / ldg_b_num;
// 申请共享内存空间
// 考虑到一个线程负责rm*rn个计算结果式读取A中一列rm和读取B中一行rn计算所得,因此不妨对A进行进行一次转置后再读取
__shared__ float sm_A_matrix[2][BLOCK_SIZE_K][BLOCK_SIZE_M]; // bm * bk
__shared__ float sm_B_matrix[2][BLOCK_SIZE_K][BLOCK_SIZE_N]; // bk * bn
// 由于A需要转置,存储的位置不是连续对齐位置,不能直接使用对齐的形式存储
// 4 * ldg_a_num确保最最多4轮搬运完成
float ldg_a_reg[4 * ldg_a_num];
float ldg_b_reg[4 * ldg_b_num];
float reg_a[2][THREAD_SIZE_M]; // rm
float reg_b[2][THREAD_SIZE_N]; // rn
/*
###### first loop ######
A,B,C矩阵让指针指向对于block中处理的数据最初开头位置的地址
*/
matrix_a += by * BLOCK_SIZE_M * K;
matrix_b += bx * BLOCK_SIZE_N;
matrix_c += by * BLOCK_SIZE_M * N + bx * BLOCK_SIZE_N;
// 申请寄存器空间用于保存rm*rn的结果
float sum[THREAD_SIZE_M][THREAD_SIZE_N] = {0};
// 首先第一代先需要加载数据到写入块中
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_M; i+=A_TILE_ROW_STRIDE){
int ldg_index = i / A_TILE_ROW_STRIDE * 4;
FLOAT4(ldg_a_reg[ldg_index]) = FLOAT4(matrix_a[(i + A_TILE_ROW) * K + A_TILE_COL]);
sm_A_matrix[0][A_TILE_COL][A_TILE_ROW + i] = ldg_a_reg[ldg_index];
sm_A_matrix[0][A_TILE_COL + 1][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 1];
sm_A_matrix[0][A_TILE_COL + 2][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 2];
sm_A_matrix[0][A_TILE_COL + 3][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 3];
}
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_K; i+=B_TILE_ROW_STRIDE)
{
FLOAT4(sm_B_matrix[0][B_TILE_ROW + i][B_TILE_COL]) = FLOAT4(matrix_b[(i + B_TILE_ROW) * N + B_TILE_COL]);
}
__syncthreads();
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm+=4){
FLOAT4(reg_a[0][rm]) = FLOAT4(sm_A_matrix[0][0][rm + ty * THREAD_SIZE_M]);
}
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn+=4){
FLOAT4(reg_b[0][rn]) = FLOAT4(sm_B_matrix[0][0][rn + tx * THREAD_SIZE_N]);
}
int write_index = 1; // 写入块的索引
int tile_idx = 0;
do{
tile_idx += BLOCK_SIZE_K;
// 这里代码虽然看上去串行,像是先加载到缓存,然后计算,再从缓存中读取到共享内存,再计算
// 实际上按照GPU设计SIMT,线程在缓存加载数据时,同时在计算数据
// 加载全局内存到寄存器中加载中间寄存器用于缓存
if(tile_idx < K){
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_M; i+=A_TILE_ROW_STRIDE)
{
int ldg_index = i / A_TILE_ROW_STRIDE * 4; // 第几代
FLOAT4(ldg_a_reg[ldg_index]) = FLOAT4(matrix_a[(i + A_TILE_ROW) * K + A_TILE_COL + tile_idx]);
}
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_K; i+=B_TILE_ROW_STRIDE)
{
int ldg_index = i / B_TILE_ROW_STRIDE * 4; // 第几代
FLOAT4(ldg_b_reg[ldg_index]) = FLOAT4(matrix_b[(i + tile_idx + B_TILE_ROW) * N + B_TILE_COL]);
}
}
int load_index = write_index ^ 1; // 写入和计算是0-1二进制对应的0或1
// 加载共享内存中的load_index块的数据到寄存器中,进行计算
// 可以看到i+1%2 与 i%2,是错开的,i=0时,reg[0]计算, reg[1]加载,i=1时,reg[1]计算,reg[0]加载
// 但是由于错开,如果加载BLOCK_SIZE_K时,计算BLOCK_SIZE_K-1这样会导致超出计算错误,因为
#pragma unroll
for(int j = 0; j < BLOCK_SIZE_K - 1; j++){
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm += 4){
FLOAT4(reg_a[(j+1) % 2][rm]) = FLOAT4(sm_A_matrix[load_index][j+1][rm + ty * THREAD_SIZE_M]);
}
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn += 4){
FLOAT4(reg_b[(j+1) % 2][rn]) = FLOAT4(sm_B_matrix[load_index][j+1][rn + tx * THREAD_SIZE_N]);
}
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm++){
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn++){
sum[rm][rn] += reg_a[j%2][rm] * reg_b[j%2][rn];
}
}
}
// 加载下一代数据到write_index写入块中
if(tile_idx < K){
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_M; i += A_TILE_ROW_STRIDE)
{
int ldg_index = i / A_TILE_ROW_STRIDE * 4;
sm_A_matrix[write_index][A_TILE_COL][A_TILE_ROW + i] = ldg_a_reg[ldg_index];
sm_A_matrix[write_index][A_TILE_COL + 1][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 1];
sm_A_matrix[write_index][A_TILE_COL + 2][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 2];
sm_A_matrix[write_index][A_TILE_COL + 3][A_TILE_ROW + i] = ldg_a_reg[ldg_index + 3];
}
#pragma unroll
for(int i = 0; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE){
int ldg_index = i / B_TILE_ROW_STRIDE * 4;
FLOAT4(sm_B_matrix[write_index][B_TILE_ROW + i][B_TILE_COL]) = FLOAT4(ldg_b_reg[ldg_index]);
}
__syncthreads();
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm += 4){
FLOAT4(reg_a[0][rm]) = FLOAT4(sm_A_matrix[write_index][0][rm + ty * THREAD_SIZE_M]);
}
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn += 4){
FLOAT4(reg_b[0][rn]) = FLOAT4(sm_B_matrix[write_index][0][rn + tx * THREAD_SIZE_N]);
}
write_index ^= 1;
}
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm++){
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn++){
sum[rm][rn] += reg_a[1][rm] * reg_b[1][rn];
}
}
}while(tile_idx < K);
// 存储计算结果矩阵C中
#pragma unroll
for(int rm = 0; rm < THREAD_SIZE_M; rm++){
#pragma unroll
for(int rn = 0; rn < THREAD_SIZE_N; rn+=4){
FLOAT4(matrix_c[(ty * THREAD_SIZE_M + rm) * N + tx * THREAD_SIZE_N + rn]) = FLOAT4(sum[rm][rn]);
}
}
}
实验结果
针对GEMM性能优化,本文程序在RTX3090消费级显卡上进行实验,实验设置从两个方面进行测试:
- bm,bn,bk,rm,rn参数对性能的影响有多大?
- 不同矩阵大小相比于cublas差距多大?
实验一:
以M=N=K=4096进行矩阵乘法计算,并对bm,bn,bk,rm,rn设置多组组合进行比较:
| bm | bk | bn | rm | rn | GFLOPS | 耗时(ms) | MyGEMM/cublas(%) |
|---|---|---|---|---|---|---|---|
| 64 | 4 | 64 | 8 | 8 | 15833.26 | 8.680 | 66.4 |
| 64 | 8 | 64 | 8 | 8 | 17398.68 | 7.899 | 73.1 |
| 64 | 16 | 64 | 8 | 8 | 17191.34 | 7.995 | 72.4 |
| 64 | 32 | 64 | 8 | 8 | 15422.89 | 8.911 | 64.8 |
| 64 | 16 | 64 | 4 | 4 | 14501.11 | 9.478 | 61.1 |
| 64 | 32 | 64 | 4 | 4 | 13798.68 | 9.960 | 58.2 |
| 128 | 16 | 64 | 8 | 8 | 18225.73 | 7.541 | 76.8 |
| 128 | 8 | 128 | 8 | 8 | 19858.25 | 6.921 | 85.3 |
从表格中可以看出,最好的配置下性能能达到85.3%。
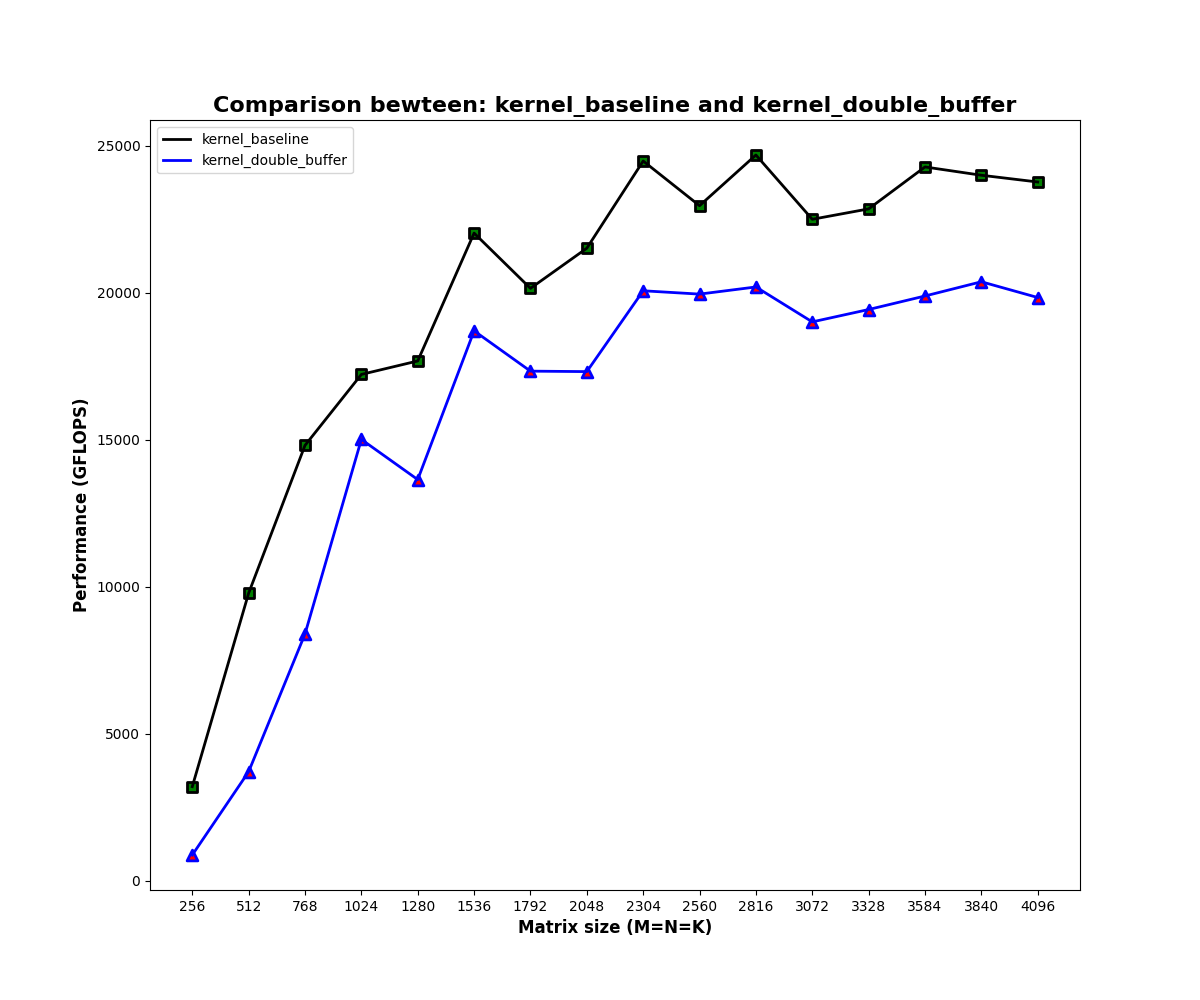
实验二:
对多组不同的矩阵大小进行测试
参考文章
深入浅出GPU优化系列
CUDA 矩阵乘法终极优化指南
CUDATutorial
总结
在本篇文章里,我们实现了上述关于GEMM所列举的五种优化技巧,主要是从如何优化访存效率,如何优化内存事务次数以及如何优化计算访存比三个方面进行展开。而我们在不使用任何汇编的情况下,并且保持较好的代码可读性同时,我们手写的Sgemm平均性能能够达到cublas的84%。文章中对代码进行了详细的解析以及注释,希望大家能够通过本文深入地了解GEMM在GPU上的优化技巧。
最后,感谢大家看到这里。关于优化cuda中Kernel性能系列,还会持续更新。如有错误,请大佬指正,非常感谢。

















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









