







GEMM(General Matrix Multiplication,通用矩阵乘法)是典型的计算密集型算子,更是深度学习算法的基础算子,对于该算子的极致优化显然是重中之重。我也看了网上关于该算子的几乎所有优化内容,但是绝知此事要躬行,自己动手一步一步优化了代码,并最终在大size条件下超越了cublas。具体代码详看:HPCTest/CUDA/GEMM at master · Beichen-Wang/HPCTest · GitHub

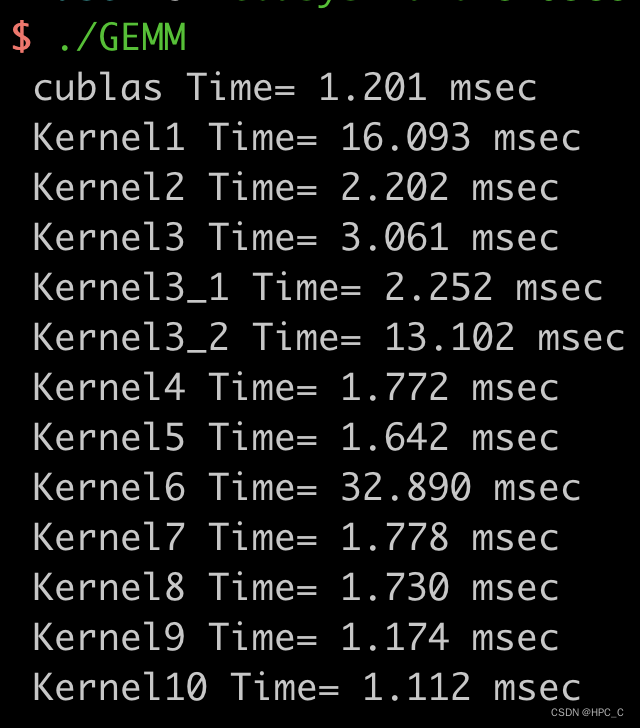
1.测试平台及测试结论
- 测试平台为: NVIDIA GeForce RTX 3080。
- CUDA版本:11.1
- cublas版本:11.2.1.74
- driver版本:470.63.01
- 测试结论:我们选用M,K,N均为2048的情况下,比cublas快了7.3%。
2.优化思路
先说一下我的优化思路,从kernel1到kernel10。
2.1Naive GEMM
首先是Kernel1,最简单的GEMM,只做了循环展开的优化:
__global__ void gemmKernel1(const float * a, const float * b, float *c, float alpha, float beta, int M, int N, int K){
unsigned int m = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int n = threadIdx.y + blockIdx.y * blockDim.y;
if(m >= M || n >= N){
return;
}
float tc = 0;
#pragma unroll
for(int k = 0; k < K; k++){
tc += a[k * M + m] * b[n * K + k];
}
c[n * M + m] = alpha * tc;
}此时为了达到最大的occupancy,选用的block size是(32,32),occupancy为66.7%。不过此时的效果很差,耗时是cublas的16倍。
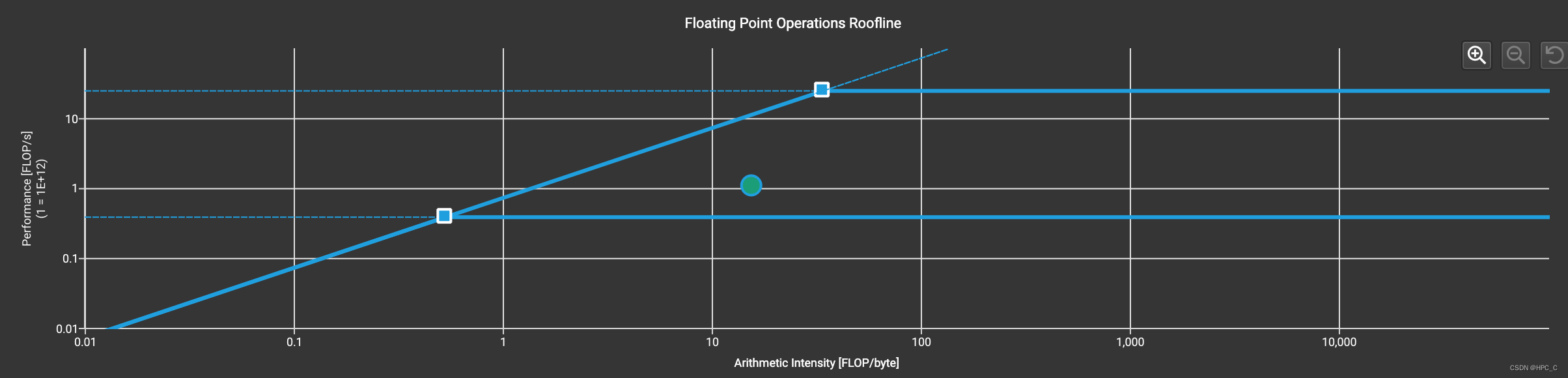 kernel1 的roofline
kernel1 的roofline
2.2使用宽指令(float4)
通过查看kernel1的roofline,看到性能点在memory bound,此时想到可以使用float4。
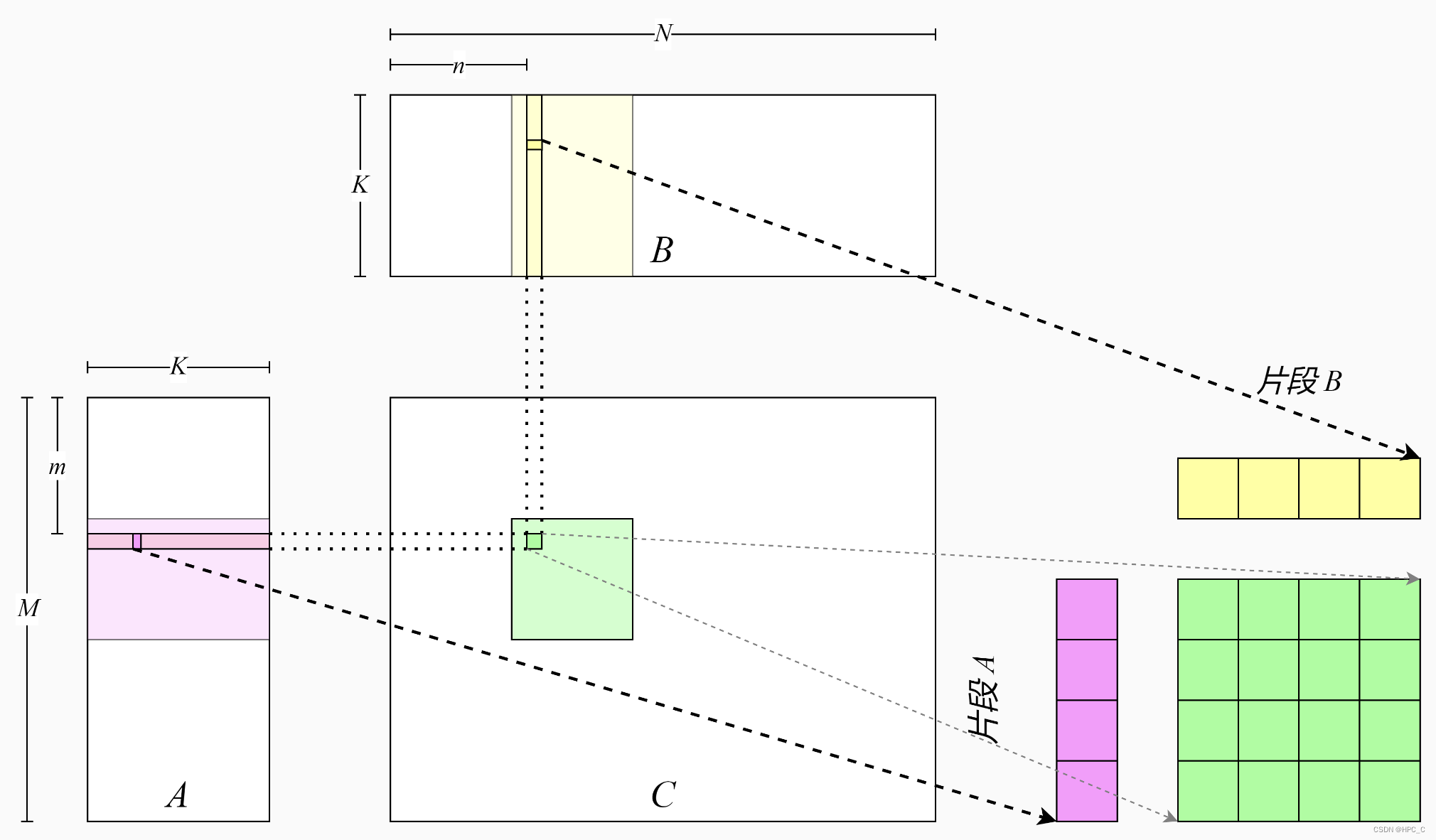
kernel2 使用float4 计算GEMM的原理
float4主要使用的是汇编代码LDG.E.128和STG.E.128来完成,优点在于:
- 减少内存访问次数,提高访存带宽;
- 一个线程算的是4*4个点,增加计算强度。
具体的kernel2为:
__global__ void gemmKernel2(const float * a, const float * b, float *c, float alpha, float beta, int M, int N, int K){
unsigned int m = (threadIdx.x + blockDim.x * blockIdx.x) * 4;
unsigned int n = (threadIdx.y + blockDim.y * blockIdx.y) * 4;
if(m >= M || n >= N){
return;
}
float4 tc_zero = make_float4(0.0f, 0.0f, 0.0f, 0.0f);
float4 tc[4] = {tc_zero,tc_zero,tc_zero,tc_zero};
#pragma unroll
for (unsigned k = 0; k < K; ++k) {
float4 fragmentA = *(const float4 *)(a + k * M + m);
float4 fragmentB = make_float4(*(b + n * K + k), *(b + (n + 1) * K + k),*(b + (n + 2) * K + k), *(b + (n + 3) * K + k));
mma 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2063
2063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









