






水库的水位变化受到众多复杂因素的影响,水位数据不仅呈现非线性特点还具有时序性和复杂性等特点。水位预测的精度提高对水库管理等方面具有重大意义。属于多变量预测
1.RNN与LSTM
RNN是一种本身包含循环的特殊网络,可以通过其特定的结构,将过去时刻的影响反映到当前的预测之中;同时由于共享不同时刻的权值矩阵,减少了参数数目,大大提高训练效率,且可以处理任意长度的时间序列数据,因此在时间序列预测方面具有独特优势

然而,普通的RNN在实际应用过程中存在长期依赖问题,即信息经长时间或多阶段传递后,会出现梯度消失和梯度爆炸的现象,网络无法保留所有历史时刻的信息,从而使模型丧失了学习到更早信息的能力。RNN结构示意图见图1,![]() 为网络输入数据,
为网络输入数据,![]() 为网络输出数据,A为循环神经网络。
为网络输出数据,A为循环神经网络。
LSTM算法是一种目前使用最多的时间序列算法,是一种特殊的循环神经网络(Recurrent Neural Network,RNN)结构[3],能够学习长期的依赖关系,解决长序列训练过程中梯度消失与梯度爆炸的问题。
LSTM与RNN一样都具有神经网络的重复模块链的形式,不同的是,LSTM在RNN的基础上每个模块增加了遗忘门、输入门、输出门和内部记忆单元。
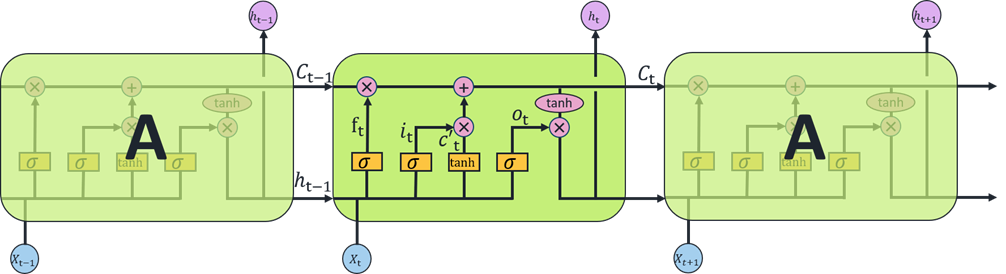
遗忘门通过判断当前输入信息的重要程度决定对过去信息的保留度:
![]() (1)
(1)
输入门通过判断当前输入信息的重要程度决定对输入信息的保留度:
![]() (2)
(2)
内部记忆单元:
![]() (4)
(4)
![]() (5)
(5)
输出门决定从本LSTM单元输出到下一个单元的数据:
![]() (6)
(6)
![]() (7)
(7)
式中:![]() ,
, ![]() 为三个门的输入权重、输入偏置,
为三个门的输入权重、输入偏置,![]() 为当前时刻t的输入,
为当前时刻t的输入,![]() 为t-1时刻LSTM单元输出,
为t-1时刻LSTM单元输出,![]() 为遗忘门输出,
为遗忘门输出,![]() 、
、 ![]() 为细胞状态和候选值。
为细胞状态和候选值。![]() 为
为![]() 激励函数,输出值的范围为0-1,当输出接近0或1时,符合物理意义上的关和开,主要起门控作用,tanh
激励函数,输出值的范围为0-1,当输出接近0或1时,符合物理意义上的关和开,主要起门控作用,tanh![]() 函数输出值的范围为-1至1,符合大多数场景下0中心的特征分布,且梯度在接近0处,收敛速度比
函数输出值的范围为-1至1,符合大多数场景下0中心的特征分布,且梯度在接近0处,收敛速度比![]() 快。LSTM通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息,适合长期记忆任务。
快。LSTM通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息,适合长期记忆任务。
针对本文中的任务,遗忘门![]() 决定在t时刻要丢弃
决定在t时刻要丢弃![]() 和
和![]() 的哪些水位影响信息;输入门
的哪些水位影响信息;输入门![]() 用来确定在t时刻需要将多少
用来确定在t时刻需要将多少![]() 和
和![]() 的水位影响信息传递到
的水位影响信息传递到![]() ,以便来更新
,以便来更新![]() 存储的信息。LSTM用输出门来控制单元状态
存储的信息。LSTM用输出门来控制单元状态![]() ,在当前t时刻,有多少
,在当前t时刻,有多少![]() 和
和![]() 中的水位影响信息要进行输出。LSTM能够分析和处理影响水库水位的时间序列数据,分析这些数据的时间依赖性和关联关系,预测水库水位数据。
中的水位影响信息要进行输出。LSTM能够分析和处理影响水库水位的时间序列数据,分析这些数据的时间依赖性和关联关系,预测水库水位数据。
2.麻雀算法
麻雀搜索算法(Sparrow Search Algorithm,SSA)是一种新型的群智能优化方法,受麻雀的觅食行为和反捕食行为的启发而得,具有寻优能力强、收敛速度快和稳定性好[4]等特点。在觅食过程中,麻雀种群分为发现者和追随者,发现者负责探索觅食区域和方向,跟随者追随它们来获得食物。当麻雀种群察觉到周围存在捕食者时,会发出危险信号,并作出反捕食行为。麻雀不断寻找最好事物的过程就是寻找最优解的过程。
3.算法流程
为了提高预测精度和稳定性,本文采用SSA-LSTM模型,利用SSA优化LSTM的两个隐含层节点、训练次数和学习率。算法流程如下:
(1)将原始数据分成70%训练集和30%测试集,进行归一化处理。
(2)将LSTM模型中的超参数(两个隐含层节点数、训练次数、学习率)作为优化对象。
(3)SSA相关参数初始化并设定需优化的超参数范围,确定最大迭代次数。
(4)计算初始种群的适应度值并进行排序,找出最优和最差的适应度值。
(5)更新发现者的位置、跟随者的位置以及察觉到危险的麻雀的位置。
(6)获取当前最优值,如果优于上一次迭代的最优值,则进行更新操作,否则不进行更新;继续进行迭代直至满足条件位置,最终得到全局最佳的适应度值和全局最优解值。
(7)将SSA得到的最优超参数构建LSTM模型,对训练集进行训练并对测试集进行预测。
将测试集的真实值和预测值进行反归一化处理,使用不同评价指标对模型的预测性能进行评估。
4.结果
水位水库预测中数据集我采用的是千里眼水雨情信息查询系统的数据,其中数据集中包括每小时的水位、水势、蓄水量和出库流量信息,对LSTM的第一层神经元、第二层神经元、迭代次数以及学习率进行优化,并使用MSE、RMSE、MAE进行评价,下面是预测值与真实值的结果
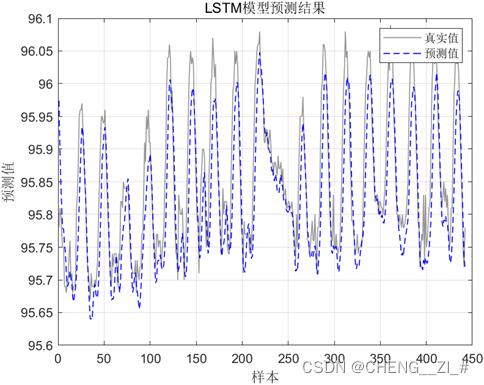
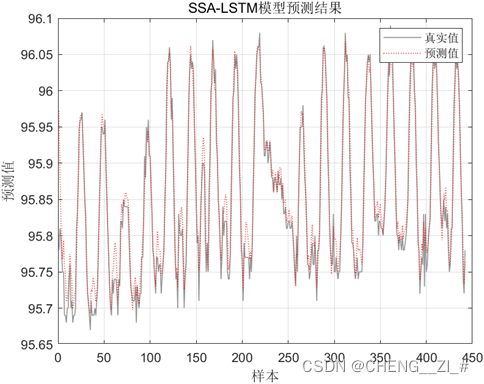
















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











