







 本文详细解读了如何使用torchdiffeq库中的神经ODE功能,通过官方推荐的案例,复现了一个动力学模型的模拟,并剖析了代码中的关键逻辑和参数设置,帮助读者理解神经网络如何求解ODE方程。
本文详细解读了如何使用torchdiffeq库中的神经ODE功能,通过官方推荐的案例,复现了一个动力学模型的模拟,并剖析了代码中的关键逻辑和参数设置,帮助读者理解神经网络如何求解ODE方程。
本系列文章板块规划
提示:以下内容仅为个人学习感悟,无法保证完全的正确和权威,大家酌情食用谢谢。
第一部分 torchdiffeq背后的数理逻辑
第二部分 torchdiffeq的基本用法
第三部分 trochdiffeq的升级用法
第四部分 torchdiffeq的案例和代码解析
第五部分 总结
第三部分的参考网站:https://github.com/rtqichen/torchdiffeq
torchdiffeq的案例和代码解析
先复现,学会使用工具
首先关于这部分内容,Github上给出了很多含有细节的案例。我们就来拿官方推荐的经典案例来做一个解释,理解neural ODE是怎样运作的。
这个案例的内容为使用torchdiffeq学习一个动力学模型来模拟一个螺旋ODE。
案例复现非常简单,代码都已经给出了,找一个有GPU的平台运行这句命令就可以:
!python ode_demo.py --viz
会得到一个png文件夹,下面有可视化的训练进度。
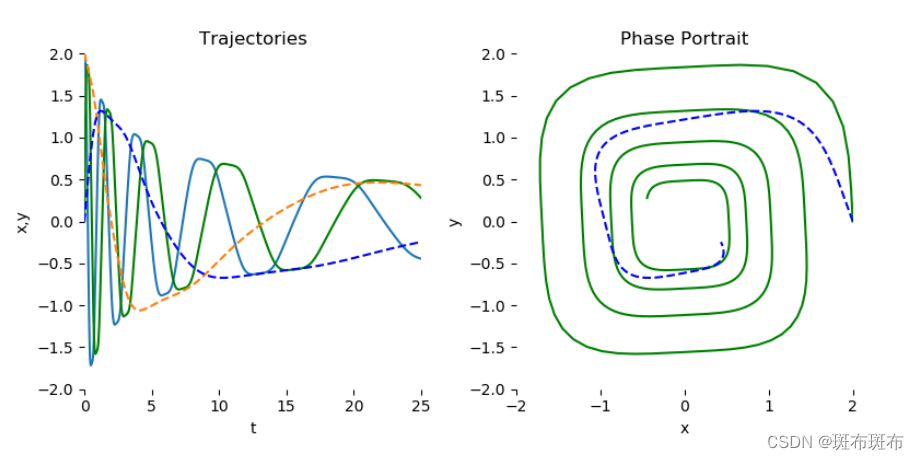
官方甚至给出了成功案例的结果:
复现的过程我们知道了,这个neuralODE做的事情原来就是使用一个神经网络去求解一个动力学方程。
复现完成后我们来看看这段代码中隐含的细节和逻辑。深入扒一扒这段代码做了什么,这样我们才能知道如何将代码改成我们需要的东西。
注意:有所的代码的解释均在代码行上方
引入必备模块和包,创建ArgumentParser对象,用于解析命令行参数
import os
# 当脚本运行时,它将处理任何传递给脚本的命令行参数,并将这些参数值赋给args变量
# 并将这些参数值赋给args变量,以便在脚本的其余部分中使用这些参数
import argparse》
import time
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
parser = argparse.ArgumentParser('ODE demo')
# 确定ODE的数值方法
parser.add_argument('--method', type=str, choices=['dopri5', 'adams'], default='dopri5')
# 指定数据集大小
parser.add_argument('--data_size', type=int, default=1000)
parser.add_argument('--batch_time', type=int, default=10)
parser.add_argument('--batch_size', type=int, default=20)
# 指训练循环的迭代次数
parser.add_argument('--niters', type=int, default=2000)
parser.add_argument('--test_freq', type=int, default=20)
# 是否启用可视化
parser.add_argument('--viz', action='store_true')
parser.add_argument('--gpu', type=int, default=0)
# 用伴随方法进行梯度计算(这在神经ODE中是一个常见的技术)。
parser.add_argument('--adjoint', action='store_true')
args = parser.parse_args()
设置了一个ODE求解环境,包括选择求解器、计算设备、初始条件、评估时间点以及系统的动态参数。这些设置都是为了在接下来的步骤中进行ODE求解准备的.
# 判断是否调入伴随方法
if args.adjoint:
from torchdiffeq import odeint_adjoint as odeint
else:
from torchdiffeq import odeint
# 查看是否有GPU
device = torch.device('cuda:' + str(args.gpu) if torch.cuda.is_available() else 'cpu')
# 初始化真实的初始条件,可以看到这里的情况是一个1x2的张量
true_y0 = torch.tensor([[2., 0.]]).to(device)
# 创建时间点的张量,可能用于在这些时间点上评估ODE的解
t = torch.linspace(0., 25., args.data_size).to(device)
# 定义ODE的系数矩阵,代表系统的动态行为
true_A = torch.tensor([[-0.1, 2.0], [-2.0, -0.1]]).to(device)
生成批量训练数据
# Lambda 类代表了一个常微分方程的动态行为
class Lambda(nn.Module):
# 定义了forward方法,它指定了ODE的具体形式。对于每个时间点t和状态y,forward方法返回y的三次方与系数矩阵true_A的矩阵乘积
def forward(self, t, y):
return torch.mm(y**3, true_A)
# 无梯度下求解ODE
with torch.no_grad():
# 注意,这里的odeint需要一个模型,odeint需要一个模型(此处为Lambda()实例)
# (接上)一个初始状态(true_y0),一组时间点(t),以及一个求解器方法(此处为dopri5,即显式Runge-Kutta方法的一种)
true_y = odeint(Lambda(), true_y0, t, method='dopri5')
# 生成批量训练数据
# 这些步骤使得此代码段能够在训练神经网络模型时提供批量的输入数据和标签
def get_batch():
s = torch.from_numpy(np.random.choice(np.arange(args.data_size - args.batch_time, dtype=np.int64), args.batch_size, replace=False))
batch_y0 = true_y[s] # (M, D)
batch_t = t[:args.batch_time] # (T)
batch_y = torch.stack([true_y[s + i] for i in range(args.batch_time)], dim=0) # (T, M, D)
return batch_y0.to(device), batch_t.to(device), batch_y.to(device)
生成存储文件
# 生成存储文件
def makedirs(dirname):
if not os.path.exists(dirname):
os.makedirs(dirname)
结果可视化
# 结果可视化
def visualize(true_y, pred_y, odefunc, itr):
if args.viz:
ax_traj.cla()
ax_traj.set_title('Trajectories')
ax_traj.set_xlabel('t')
ax_traj.set_ylabel('x,y')
ax_traj.plot(t.cpu().numpy(), true_y.cpu().numpy()[:, 0, 0], t.cpu().numpy(), true_y.cpu().numpy()[:, 0, 1], 'g-')
ax_traj.plot(t.cpu().numpy(), pred_y.cpu().numpy()[:, 0, 0], '--', t.cpu().numpy(), pred_y.cpu().numpy()[:, 0, 1], 'b--')
ax_traj.set_xlim(t.cpu().min(), t.cpu().max())
ax_traj.set_ylim(-2, 2)
ax_traj.legend()
ax_phase.cla()
ax_phase.set_title('Phase Portrait')
ax_phase.set_xlabel('x')
ax_phase.set_ylabel('y')
ax_phase.plot(true_y.cpu().numpy()[:, 0, 0], true_y.cpu().numpy()[:, 0, 1], 'g-')
ax_phase.plot(pred_y.cpu().numpy()[:, 0, 0], pred_y.cpu().numpy()[:, 0, 1], 'b--')
ax_phase.set_xlim(-2, 2)
ax_phase.set_ylim(-2, 2)
ax_vecfield.cla()
ax_vecfield.set_title('Learned Vector Field')
ax_vecfield.set_xlabel('x')
ax_vecfield.set_ylabel('y')
y, x = np.mgrid[-2:2:21j, -2:2:21j]
dydt = odefunc(0, torch.Tensor(np.stack([x, y], -1).reshape(21 * 21, 2)).to(device)).cpu().detach().numpy()
mag = np.sqrt(dydt[:, 0]**2 + dydt[:, 1]**2).reshape(-1, 1)
dydt = (dydt / mag)
dydt = dydt.reshape(21, 21, 2)
ax_vecfield.streamplot(x, y, dydt[:, :, 0], dydt[:, :, 1], color="black")
ax_vecfield.set_xlim(-2, 2)
ax_vecfield.set_ylim(-2, 2)
fig.tight_layout()
plt.savefig('png/{:03d}'.format(itr))
plt.draw()
plt.pause(0.001)
微分方程(ODE)求解的训练循环
# 设置神经网络
class ODEFunc(nn.Module):
# 初始化
def __init__(self):
super(ODEFunc, self).__init__()
self.net = nn.Sequential(
nn.Linear(2, 50), #线性层
nn.Tanh(), # 激活层
nn.Linear(50, 2), # 线性层
)
#权重和偏置的初始化
for m in self.net.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.1)
nn.init.constant_(m.bias, val=0)
# 前向传播
def forward(self, t, y):
return self.net(y**3)
class RunningAverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, momentum=0.99):
self.momentum = momentum
self.reset()
# 初始化或重置状态
def reset(self):
self.val = None
self.avg = 0
# 用于接收新的观测值val并更新平均值avg
def update(self, val):
if self.val is None:
self.avg = val
else:
self.avg = self.avg * self.momentum + val * (1 - self.momentum)
self.val = val
if __name__ == '__main__':
ii = 0
func = ODEFunc().to(device)
# 使用优化算法及学习率
optimizer = optim.RMSprop(func.parameters(), lr=1e-3)
end = time.time()
# 初始化时间记录器
time_meter = RunningAverageMeter(0.97)
# 损失记录器
loss_meter = RunningAverageMeter(0.97)
# 训练循环
for itr in range(1, args.niters + 1):
# 梯度归零
optimizer.zero_grad()
batch_y0, batch_t, batch_y = get_batch()
# 前向传播和损失计算
pred_y = odeint(func, batch_y0, batch_t).to(device)
loss = torch.mean(torch.abs(pred_y - batch_y))
loss.backward()
optimizer.step()
time_meter.update(time.time() - end)
loss_meter.update(loss.item())
#定期评估和可视化
if itr % args.test_freq == 0:
with torch.no_grad():
pred_y = odeint(func, true_y0, t)
loss = torch.mean(torch.abs(pred_y - true_y))
print('Iter {:04d} | Total Loss {:.6f}'.format(itr, loss.item()))
visualize(true_y, pred_y, func, ii)
ii += 1
# 时间更新
end = time.time()

















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









