







包含全部示例的代码仓库见GIthub
1 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
2 K-means 算法
2.1 数据准备
data_list = []
for i in range(1,8):
try:
data = pd.read_csv('./dataset/lianjia{}.csv'.format(i), encoding='gbk')
except:
data = pd.read_csv('./dataset/lianjia{}.csv'.format(i))
finally:
data_list.append(data)
data = pd.concat(data_list)
data = data.dropna()
data.cjdanjia = np.round(data.cjdanjia.str.replace('元/平','').astype(np.float32).map(lambda x:x/10000),2)
data1 = data[data.cjxiaoqu.str.contains('龙锦苑东一区 3室2厅 124平')]
data1
# output
cjtaoshu mendian cjzongjia zhiwei haoping cjdanjia cjxiaoqu xingming cjzhouqi biaoqian cjlouceng cjshijian congyenianxian bankuai
384 31 龙跃店 240.0 店经理 94% 226 1.93 龙锦苑东一区 3室2厅 124平 孙阿伟 41 房东信赖;销售达人;带看活跃 南 北/高楼层/6层 签约时间:2015-12-16 3-4年 回龙观
3778 23 流星花园店 204.0 经纪人 97% 104 1.64 龙锦苑东一区 3室2厅 124平 唐生 45 房东信赖;销售达人 南 北/高楼层/6层 签约时间:2012-12-22 5年以上 回龙观
6805 34 上北社区一店 260.8 店经理 95% 392 2.10 龙锦苑东一区 3室2厅 124平 盛起云 41 房东信赖;销售达人;带看活跃 南 北/中楼层/6层 签约时间:2014-02-22 3-4年 回龙观
10369 43 龙泽城铁店 290.0 店经理 99% 245 2.34 龙锦苑东一区 3室2厅 124平 苑文超 30 房东信赖;销售达人 南 北/高楼层/6层 签约时间:2016-03-21 5年以上 回龙观
12006 45 和谐家园社区店 226.0 店经理 97% 183 1.82 龙锦苑东一区 3室2厅 124平 张晓维 65 房东信赖;销售达人;带看活跃 南 北/高楼层/6层 签约时间:2013-03-15 5年以上 回龙观
... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
33919 16 龙锦东一店 243.5 店经理 96% 121 1.96 龙锦苑东一区 3室2厅 124平 李志杨 23 房东信赖 南 北/低楼层/6层 签约时间:2014-08-24 3-4年 回龙观
33921 16 龙锦东一店 170.0 店经理 96% 121 1.37 龙锦苑东一区 3室2厅 124平 李志杨 23 房东信赖 南 北/低楼层/6层 签约时间:2014-07-30 3-4年 回龙观
36048 4 龙腾东店 318.0 高级经纪人 98% 107 2.56 龙锦苑东一区 3室2厅 124平 刘亚茹 29 带看活跃 南 北/中楼层/6层 签约时间:2016-04-16 <1年 回龙观
36144 22 龙泽苑西区店 218.0 高级经纪人 98% 112 1.76 龙锦苑东一区 3室2厅 124平 王洪洋 68 房东信赖 南 北/低楼层/6层 签约时间:2012-12-03 5年以上 回龙观
37784 13 云趣园小区店 234.0 高级经纪人 94% 92 1.89 龙锦苑东一区 3室2厅 124平 李飞玲 32 带看活跃 南 北/低楼层/6层 签约时间:2013-06-17 4-5年 回龙观
plt.scatter(range(1,len(data1)+1), data1.cjdanjia)
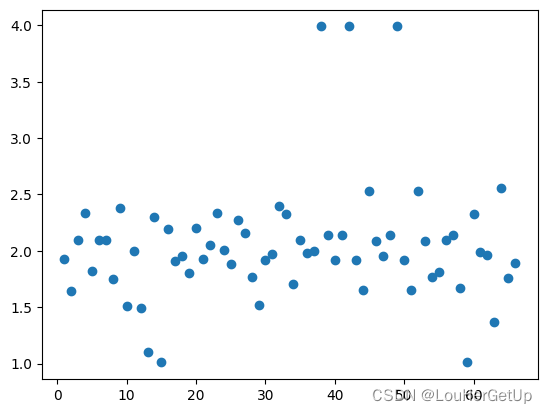
2.2 模型构建
y_pred = KMeans(n_clusters=2).fit_predict(data1[['cjdanjia']])
y_pred
# output
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
结果绘图
plt.scatter(range(1,len(data1)+1), data1.cjdanjia, c = y_pred)
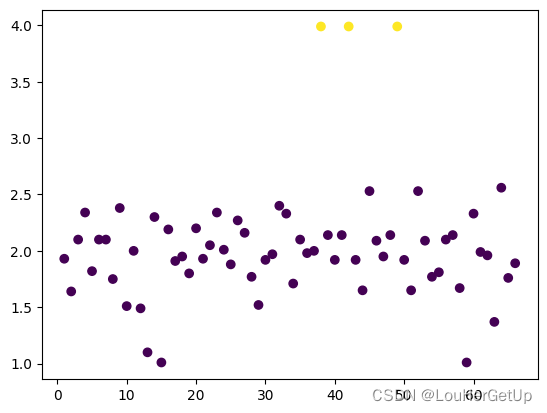
2.3 数据准备二
data2 = data[data.cjxiaoqu.str.contains('龙锦苑东五区 3室2厅 124平')]
plt.scatter(range(1,len(data2)+1), data2.cjdanjia)
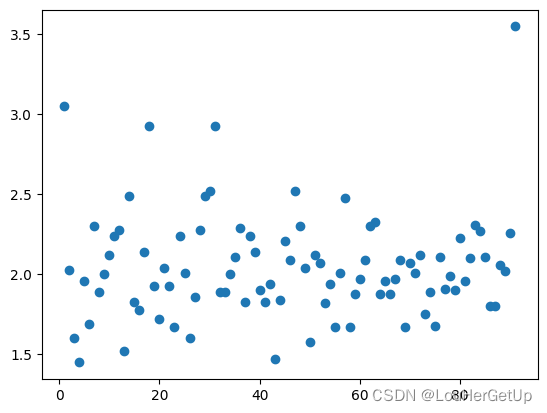
2.4 模型构建二
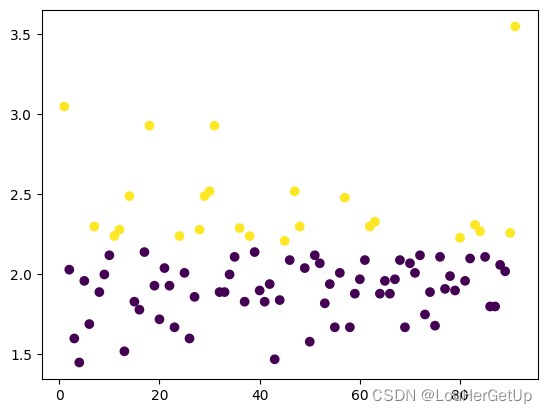
y_pred = KMeans(n_clusters=2).fit_predict(data2[['cjdanjia']])
从结果可以看出 K-means 对于这种数据的分类效果并不好
plt.scatter(range(1,len(data2)+1), data2.cjdanjia, c = y_pred)
3 DBSCAN 算法
y_pred = DBSCAN().fit_predict(pd.DataFrame(data2.cjdanjia))
plt.scatter(range(1,len(data2)+1), data2.cjdanjia, c = y_pred)
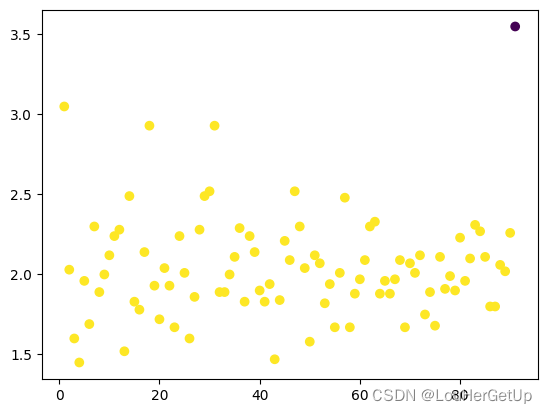
epslion 密度阈值,min_samples 最小个数
y_pred = DBSCAN(eps=0.4).fit_predict(data2[['cjdanjia']])
plt.scatter(range(1,len(data2)+1), data2.cjdanjia, c = y_pred)
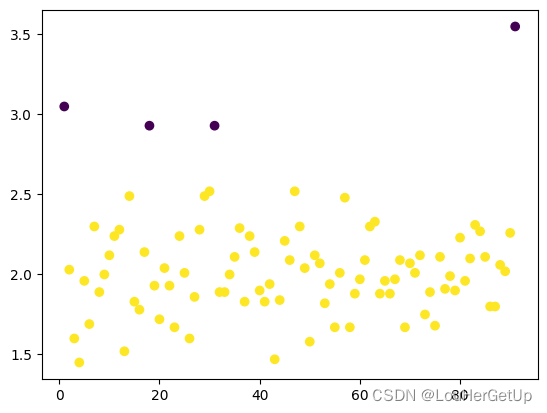
















 5413
5413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











