








过拟合
在进行逻辑回归和线性回归时可能出现欠拟合和过拟合现象,欠拟合和过拟合均无法有效的应用到未测试数据中,过拟合对输入的实验数据的拟合效果异常完美,但是对未加入的数据拟合结果很差。下面三个图分别代指欠拟合,拟合良好和过拟合。(图片来自大牛吴恩达的课程)
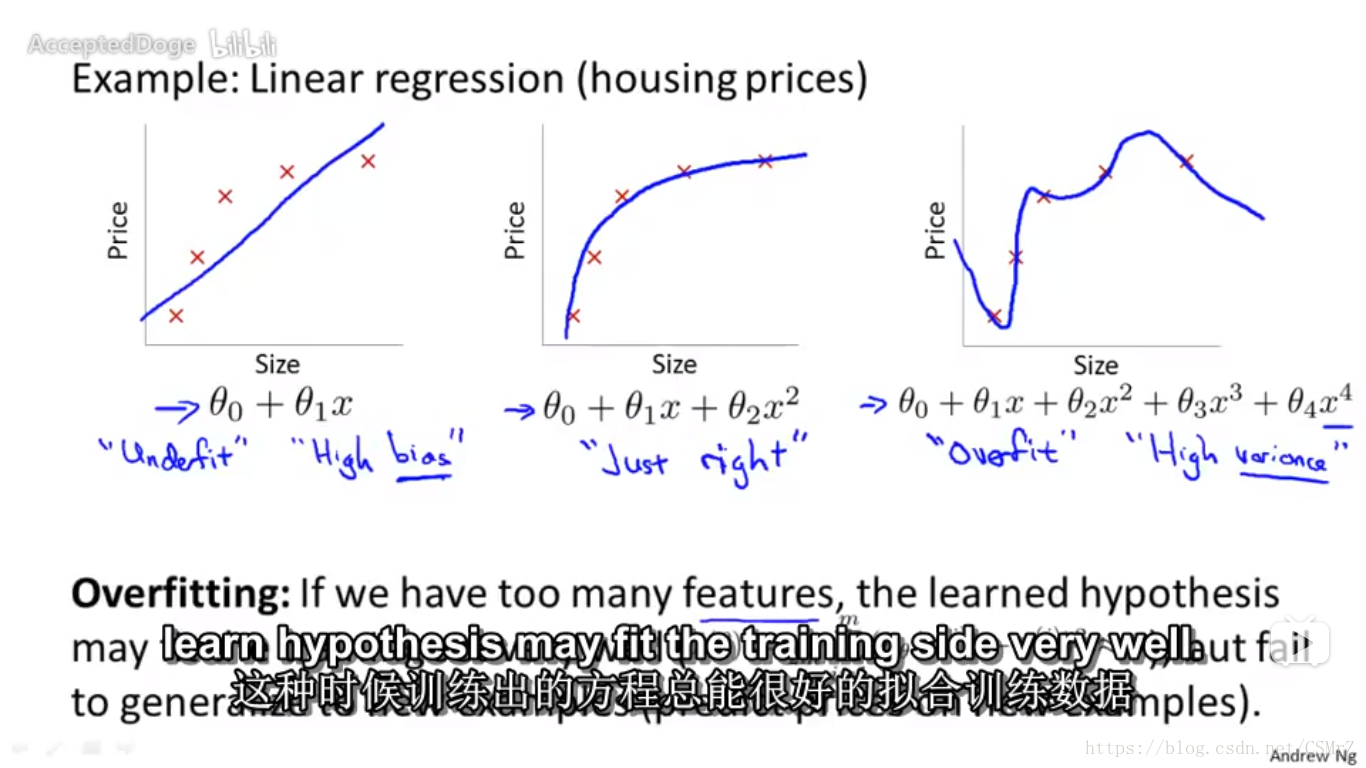
产生过拟合的原因
特征量太多,而测试数据太少。
解决方法
1.人为的舍弃特征量(略)
2.正则化
正则化的基本思想是在代价函数中加入惩罚因子,将特征量的影响力减小。例如假设函数 h(θx)=θ0+θ1x1+θ2x22+θ3x1x2 h ( θ x ) = θ 0 + θ 1 x 1 + θ 2 x 2 2 + θ 3 x 1 x 2 ,我们在原代价函数的基础上加上 1000θ22+1000θ23 1000 θ 2 2 + 1000 θ 3 2 ,这样我们在最小化代价函数时, θ3 θ 3 和 θ2 θ 2 的值趋近于0,即弱化了后两项的影响力。当我们不知道弱化具体哪些项时,可以将所有项均弱化,这就叫做正则化,默认不弱化 θ0 θ 0 项。
线性回归中的正则化
1.梯度下降
代价函数变成如下形式:
更新 θj θ j (除 θ0 θ 0 ):
2.正规方程
正规方程变为如下形式,在原来的基础上添加了一个除第一行对角线为0,其余对角线上均为1的矩阵。(不清楚为什么,但是解决了
XTX
X
T
X
的不可逆问题)
逻辑回归中的正则化
代价函数变为如下形式:
更新 θj θ j (除了 θ0) θ 0 ) :

















 5185
5185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









