






 本文提出 D-NeRF 方法,扩展神经辐射场技术到动态领域,实现单目相机移动时刚性和非刚性目标的重建与渲染。通过引入时间变量,将场景映射到规范化空间并进行形变估计。
本文提出 D-NeRF 方法,扩展神经辐射场技术到动态领域,实现单目相机移动时刚性和非刚性目标的重建与渲染。通过引入时间变量,将场景映射到规范化空间并进行形变估计。
论文解读

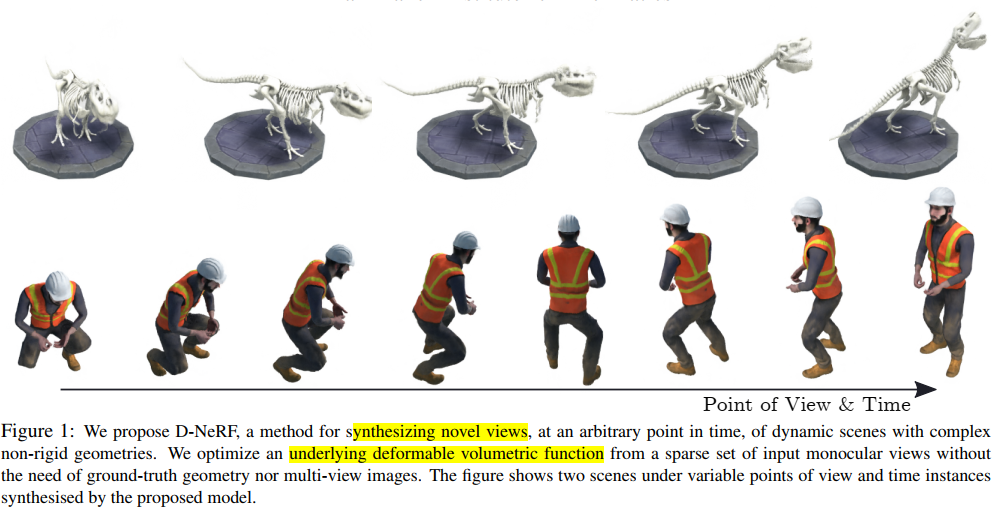
本文提出一个能够在任意时间点合成复杂非刚性动态场景的方法:D-NeRF。作者从不需要几何真值或多视图图像的一稀疏单目视图集下,优化一个潜在形变体函数。上图展示了用本文提出的方法,在视点变化和时间实例下合成的新颖图像。
摘要
结合机器学习和几何推理的神经渲染技术,已是从一组稀疏图像中合成新颖场景最有前途的方法之一。在所有技术当中,最具代表的是NeRF,通过训练一个神经网络将5D输入坐标映射到一个体积密度和依赖视角的辐射场。虽然NeRF在生成图像上实现了前所未有的真实图像,但NeRF只能应用到静态场景,从不同的图像上查询出相同的空间位置像素。本论文中,我们提出D-NeRF,扩展神经辐射到一个动态领域,能够在单目相机围绕场景移动情况下重建和渲染刚性和非刚性目标。作者为解决上述问题,考虑时间作为一个外部输入到系统中,并将学习分为两个阶段:一是编码场景到规范化空间;二是在特定时间下,映射这个规范化表示到形变场景。上述两步映射处理均是使用全连接网络。
方法
作者在NeRF的5D坐标下引入了时间t条件变为6D坐标,因此可将映射关系用下式表示:
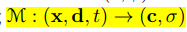
作者将映射关系分为两部分,如下所示。一个为t时刻场景到规范化场景的映射,另外一个为在规范化配置下表示场景。
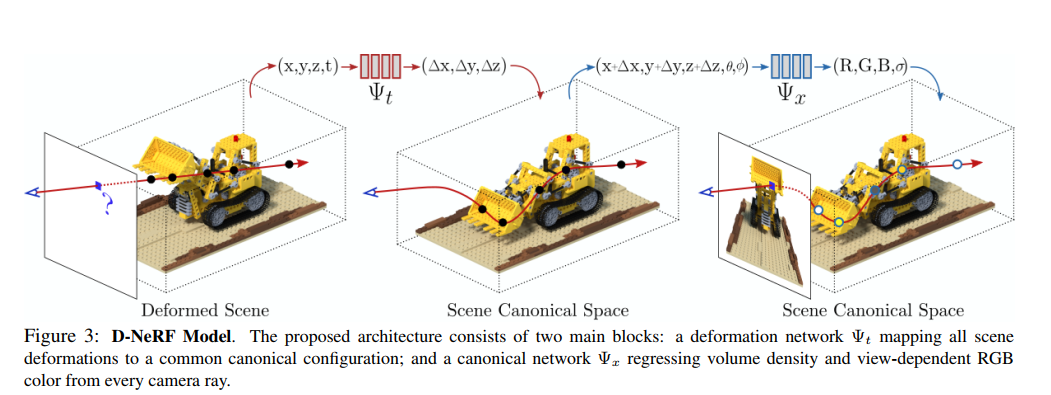
模型架构
规范化网络:通过一个规范化配置,我们试图寻找一个场景的表示,能够将所有图像上所有对应点的信息汇聚在一起。通过这样实施,从一个特定视点缺失的信息能够在规范空间索引到,它应该作为连接所有图像的核。
这个规范化网络通过训练来在规范化配置上编码场景的体透明度和颜色。具体地,给定一个一点的3D坐标,我们首先编码它到一个365维的特征向量。这个特征向量和相机视角方向级联在一起,通过一个全连接层来在规范化空间输出给定点的颜色和体透明度。
形变网络:形变网络通过优化来估计特定时间的场景和规范化配置场景的形变。给定在时间t的3D空间点x,形变网络训练输出偏移。为了保证通用性,我们将规范化场景设定在时间t为0处:
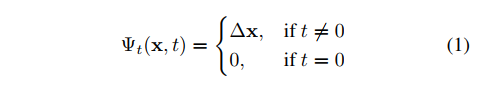
这里还将3D空间位置x、视角方向d、时间t分别都映射到高维空间,展示出较好的性能。
体渲染
这里大体上类似NeRF的积分公式,只不过这里分为两个阶段:形变和规范化。
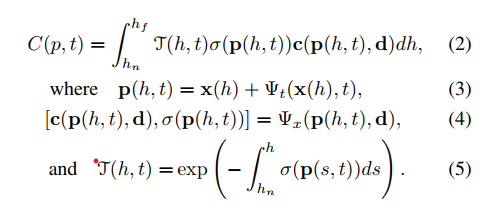
将上述积分转化为数值求积公式:
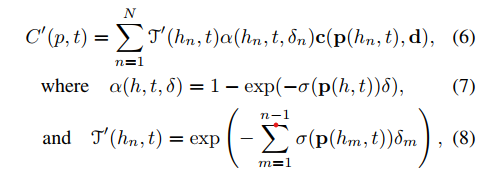
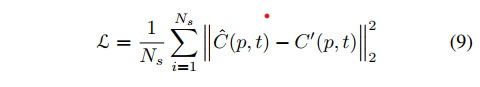
结论
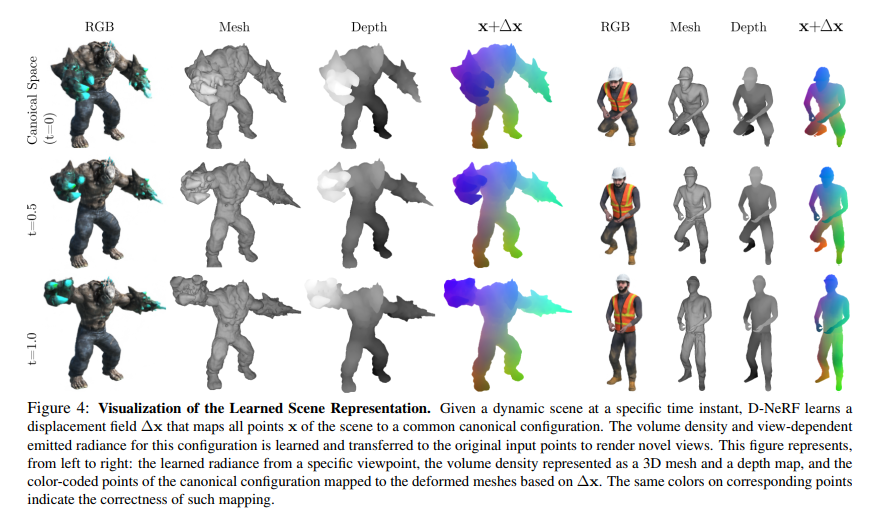
定量和定性观察一下,本文所提出网络的效果:

每天我们会定期发布最新关于《计算机视觉与图形学》相关论文和知识,请扫描下方二维码关注我们:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









