






非滤波单目视觉SLAM系统研究
转载 2017年01月11日 16:31:34 标签:SLAM /monocular salm /SVO /ORB /PTAM 997
非滤波单目视觉SLAM系统研究
A survey on non-filter-based monocular Visual SLAM systems
Taylor Guo, 2016年9月12日
摘要
滤波(卡尔曼滤波,粒子滤波)视觉SLAM更通用,非滤波(运动结构估计)方案更有效率。本文讲解各种视觉SLAM构建方法及其组成部分。
一 简介
基于相机的定位有两种方法。一种是基于图像的定位,需要先处理场景生成3D结构,场景图像和对应的相机视角。定位问题就可以变为将图像序列与数据库的进行匹配,和选择具有最佳匹配的相机位置。第二种技术是,没有先验场景信息;地图构建和定位同时进行、我们可以增量式地估计相机位姿------也就是视觉里程计;或者为了减少里程计中的漂移,在整个运行过程中维护地图和相机位姿。这个就是视觉SLAM。
二 概览
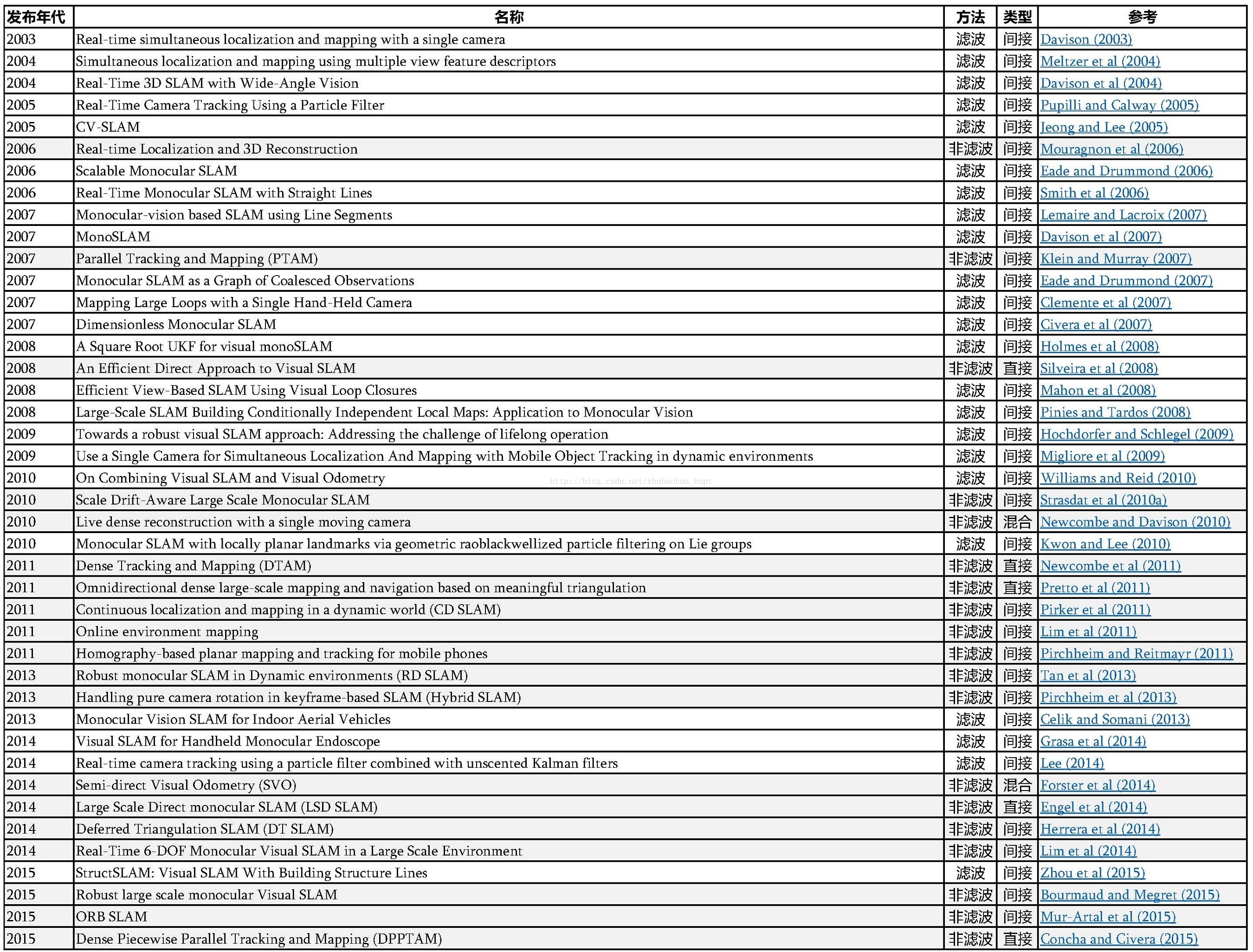
视觉SLAM方案可以基于滤波方案(卡尔曼滤波、粒子滤波),也可以基于非滤波方案(比如,将其视为优化问题)。图1a是滤波系统的不同部分的数据连接;相机位姿Tn估计需要使用地图中所有路标处理每幅图像并且更新。图1.b是非滤波系统,不同部分的数据连接,可以允许相机在Tn的位姿估计用整个地图的一个子集,不需要在每幅图像都更新地图数据。
图1:视觉SLAM系统中的数据连接:滤波与非滤波方法
三 视觉SLAM系统的设计
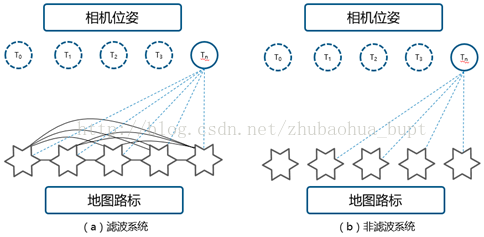
本章讨论视觉SLAM最近进展,分析最成功的开源非滤波方法视觉SLAM系统。具体讨论PTAM,SVO,DT SLAM, LSD SLAM, ORB SLAM, DPPTAM。一般的非滤波视觉SLAM系统主要有8部分组成,如图2所示,(1)数据输入类型,(2)数据关联,(3)初始化,(4)位姿估计,(5)地图生成,(6)地图维护,(7)失效恢复,(8)回环闭合。
图2:非滤波方法的视觉SLAM系统的8个模块
我们会详细介绍每一部分,视觉SLAM如何执行这些模块。需要注意的是,这些系统的内参是已知的,已经离线标定好了。
3.1 输入数据类型
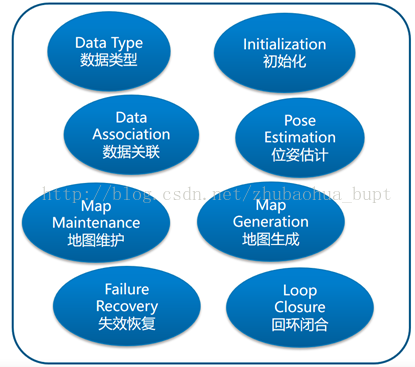
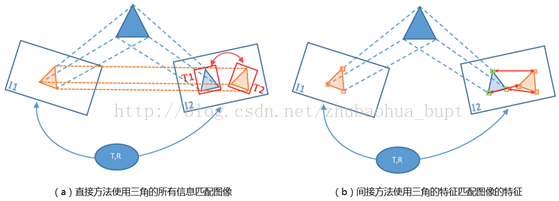
视觉SLAM方法被分为直接法,间接法,混合法。直接方法---也是稠密或半稠密方法---指的是采用图像上每个像素的信息(亮度值)估计描述相机位姿的参数。另外,间接法用于减少处理每个像素的计算复杂度;可以只使用显著的图像部位(即特征)用于位姿估计的计算(如图3 所示)。
图3:视觉SLAM系统使用的数据类型
3.1.1 直接方法
直接方法最基本的原理是亮度一致性约束,可以用一下公式描述:
J(x,y)=I(x+u(x,y)+v(x,y)), (1)
其中,x,y是像素坐标;u,v是同一场景的两幅图像I和J的像素(x,y)变换函数。每个像素都有一个亮度值,但它增加了2个未知数(u和v),系统变为欠定方程组,有2n个未知数但只有n个等式(其中n是图像上的像素数量)。为了解决这个问题,Lucas & Kanade采用 前向相加图像对齐Forward Additive Image Alignment 取代单一像素变换u和v的一般运动模型,这个模型参数的数量取决于运动类型。FAIA通过改变变换参数迭代地最小化模板和输入图像的像素亮度差值。为了减小计算复杂度,FAIA变化成其他形式,如 FCIA (Forward Compositional Image Alignment), ICIA (Inverse Compositional Image Alignment) and IAIA (Inverse Additive Image Alignment)。
直接方法使用了图像上所有的信息,在纹理较差的部分比间接法更鲁棒。但当场景中的光照变化后,直接法更容易失效,亮度一致性约束要求两幅图像之间的光度误差尽可能地小。第二个不利的因素是,每个像素的光度误差的计算非常密集;直接法的实时视觉SLAM的应用,之前认为一直不可行。由于最近出现了并行计算,直接法被整合到视觉SLAM中(比如DPPTAM, LSD-SLAM, SVO)。
3.1.2 间接方法
间接方法使用特征匹配。特征比较显著,对视角和光照变化具有不变性,对模糊和噪声有弹性。对纹理的提取计算高效快速。但这些目标很难同时获得,需要在计算速度和特征质量上取得平衡。
计算机视觉领域研究了很多不同的特征提取和特征描述,它们对旋转、尺度不变,和计算速度的性能都不一样。选择合适的特征检测依赖于平台的计算能力,视觉SLAM算法运行的环境,还有图像的帧率。特征检测有 Hessian corner detector (Beaudet, 1978), Harris detector (Harris and Stephens, 1988), Shi-Tomasi corners (Shi and Tomasi, 1994), Laplacian of Gaussian detector (Lindeberg, 1998), MSER (Matas et al, 2002), Difference of Gaussian (Lowe, 2004) and the accelerated segment test family of detectors (FAST, AGAST, OAST) (Mair et al, 2010).
为了降低计算要求,大部分间接系统使用FAST作为特征提取,与特征描述一起执行数据关联。特征描述包括但不限于BRIEF, BRISK, SURF, SIFT, HoG, FREAK, ORB 和低层像素级别局部区块。更多的有关特征提取和特征描述,可以参考论文综述。
3.1.3 混合方法
与直接法和间接法不同的,有的系统,比如SVO采用混合方法,用直接法构建特征对应,用间接法优化相机位姿估计。
表2总结了部分视觉SLAM系统使用的数据类型。开源的间接方法,PTAM, SVO, DT SLAM使用FAST特征, ORB SLAM使用ORB特征。
PTAM SVO DT SLAM LSD SLAM ORB SLAM DPPTAM
方法 间接法 混合法 间接法 直接法 间接法 直接法
表2:不同视觉SLAM系统采用的方法。
3.2 数据关联
数据关联就是在不同图像之间建立对应关系作为视觉SLAM其他模块的输入。这步是系统必须的,采用直接方法,在相机位姿里面还会讨论直接方法的数据关联。
构建特征对应的间接方法有3种,2D-2D,3D-2D和3D-3D。
3.2.1 2D-2D
没有地图,也没有2幅图像的相机变换,也没有场景结构时,使用2D-2D的数据关联。为了减少计算时间,避免错误数据关联的可能性,第一幅图像的特征2D位置用作定义一个搜索窗口在第2幅图像中进行搜索。每个特征有个描述子,与其他特征的相似度进行定量对比。描述子距离函数随描述子类型变化:对于像素描述子的局部区块,通常使用模板(patch)匹配中差值的平方和(SSD),或者 为了增加对于光照变化的鲁棒性,使用零均值像素灰度差平方和 (ZMSSD)。对于高层特征描述子,比如ORB,SIFT和SURF,可能会采用L1范数(向量中各个元素绝对值之和,就是绝对值相加,又称曼哈顿距离),L2范数(就是欧几里德距离)和汉明距离;但用这些方法做匹配计算量比较大,稍不注意可能会降低实时性能。这样,就采用特别的检索和执行方法来处理特征匹配,采用KD树或词袋。
3.2.2 3D-2D
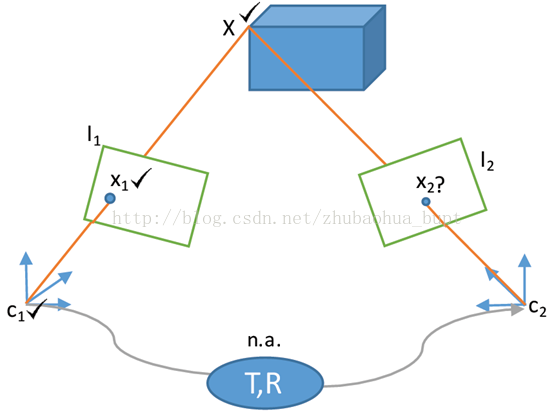
图4是3D-2D数据关联问题,前一相机位姿估计和3D结构已知,需要估计2D特征和3D路标影射的对应关系,这个3D路标影射到一个新的图像中并没有预先知道这两个图像之间的确切运动过程。这种数据关联方法在视觉SLAM的位姿估计中非常常用。
图4:3D-2D数据关联问题(n.a.表示执行任务过程中不存在)
3.2.3 3D-3D
估计和校正回环的累积漂移,就需要3D-3D的数据关联,2幅图像中观测到的3D路标的描述子可以与将要探测的路标之间进行匹配用于两个图像间的相似变换。表3总结了各种开源视觉SLAM系统采用的特征类型和描述子。
PTAM SVO DT SLAM LSD SLAM ORB SLAM DPPTAM
特征
类型
FAST FAST FAST 无 FAST 无
特征
描述
像素局部模板 像素局部模板 像素局部模板 像素局部模板 ORB 像素局部模板
表3:特征提取和描述子。像素局部模板:Local patch of pixels。
PTAM。PTAM成功初始化之后,每个图像会生成一个4层金字塔(比如,第一层:640x480,第二层:320x240)。金字塔可以使特征对于尺度变换更鲁棒,从而降低位姿估计模块的收敛半径。每层都会提取FAST特征并且每个特征都会计算Shi-Tomasi分值;在执行非极大值抑制(Non-maximum suppression)算法之前会去除低于一个Shi-Tomasi门限值的特征。这样是为了确保提取的特征的高度显著性,并限制它们的数量,可以使计算复杂度可控制。
每层金字塔都有不同的Shi-Tomasi门限值和非极大值抑制;从而可以控制特征强度和数量,在每层金字塔都可以追踪到。然后,用已知的位姿估计将3D路标影射到新图像上去,同样的方式用于2D-2D方法,在射影的路标位置附近的搜索窗口中构建特征匹配。3D路标特征匹配的描述子通常从2D图像中提取,在这个2D图像中已经提前观测到了3D路标;然而,当相机视角观察到显著变化,或者由于像素局部模板弯曲引起视角变化,有些系统建议更新描述子。
DT SLAM。与PTAM类似,DT SLAM采用相同的机制构建2D-3D特征匹配。
SVO。SVO中图像有5层金字塔:通过迭代执行直接图像对准方案从最高层金字塔到第3层金字塔进行数据关联。这一步的初步数据关联作为FAST特征匹配过程的已知知识,与PTAM保持显著性的图像变形技术相似,使用零均值像素灰度差平方和 (ZMSSD) 。
ORB SLAM 。ORB SLAM在8层金字塔上都提取FAST角点。为了确保整幅图像的一致性分布,每层金字塔被分成小单元格,FAST特征检测的参数可以在线调整以确保每个单元格至少提取5个角点。然后每个提取的特征计算256位ORB特征描述子。高层的ORB特征描述子用于建立特征间的对应关系。ORB SLAM把描述子分散存储到词袋中,也就是视觉字典,约束字典树上相同节点下的特征可以加速图像和特征匹配。
3.3 初始化
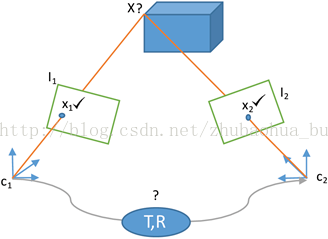
单目视觉SLAM系统需要进行初始化,这一过程主要生成3D路标地图和初始相机位姿。相同的场景要从同一基线的不同视角分离开。图5是视觉SLAM系统的初始化,只知道2幅图像间的关联数据,初始相机位姿和场景结构都是未知的。
图5:视觉SLAM系统的初始化
早期视觉SLAM系统,比如单目视觉SLAM,系统初始化要求相机摆放在距平面场景已知距离的地方,场景由4个角和2维平面组成,SLAM通过操作人员输入距离值实现初始化。
PTAM。图6显示了基于模型初始化的一般流程,比如PTAM,SVO,ORB SLAM。为了避免用户手动输入深度信息,PTAM使用5点算法估计和分解基本矩阵到非平面初始场景。后来PTAM初始化做了改变,使用单应,此时场景应该由2D平面组成。PTAM初始化要求用户两次输入获取地图中的前2个关键帧;它还需要用户在第一个和第二个关键帧之间,与场景平行地执行一个缓慢的,平滑的,相对明显的平移运动。
图6 初始化的一般流程
从第1个关键帧提取的FAST特征,后来的每一帧图像中,用2D-2D数据关联方法追踪,直到用户插入第2个关键帧。 匹配过程采用ZMSSD,不需要保持显著性的图像特征的变形技术,构建角点匹配的过程对运动模糊和由于相机旋转造成明显的外观特征改变比较敏感,因此,要在初始化过程中对用户的运动状态严格要求。为了使匹配错误最小化,特征需要搜索2遍;第一次从当前帧到上一帧,第二次从相反的方向搜索。如果两个方向的匹配不一致,特征就会被丢弃。PTAM初始化使用单应估计,那么初始化过程中的场景就应该是2维的。一旦第2个关键帧成功地放入地图中,一个随机抽样最大似然估计(Maximum Likelihood Estimation by Sample and Consensus, MLESAC)回环使用构建好的匹配生成一个单应,这个单应是在2个关键帧间的,在分解成8个可能的方案之前使用内点进行优化。选择正确的相机位姿对,这样所有三角化过的3D点就不会生成不真实的配置(两幅图中的逆深度)。
生成的初始地图大小可以变化,这样前两个关键帧之间估计的平移变换就可以对应成0.1个单位,在这之前仅基于结构的捆集调整BA(只优化路标的3D位姿)就会先运行。选用3D路标的均值作为世界坐标,同时选择z轴的正方向作为相机位姿的正方向。
PTAM初始化程序非常脆弱,需要技巧去运行,尤其是对于没有经验的用户。还有,初始化场景不是2维平面,或用户运动状态不恰当的时候,系统退化,容易崩溃,这样的退化无法检测。
SVO。类似的,SVO使用单应进行初始化,但SVO不需要用户输入,算法使用系统启动时的第一个关键帧;提取FAST特征,用图像间的KLT算法跟踪特征(KLT(Kanade-Lucas-Tomasi)算法是计算机视觉的跟踪算法,通过基于平移模型进行灰度匹配来实现特征点的跟踪,并进行基于跟踪算法的特征点选择,提高特征点跟踪质量。通过特征点选择算法在起始图像中选择特征点,然后利用平移模型进行特征点跟踪,对于第N幅图像上跟踪到的特征点,通过仿射模型进行连续性判断,对跟踪错误的特征点进行剔除。KLT算法中在研究不同图像之间的匹配问题时,通过计算两个平移窗口的灰度残差,并寻找最小化残差SSD(sum of square difference)来实现匹配。在优化过程中,KLT算法使用泰勒展开直接计算平移矢量,而不需要通过遍历进行搜索;同时使用Newton-Raphson迭代算法来避免泰勒展开带来的误差。)为了避免用户二次输入,SVO监控第一个关键帧和当前图像间的特征点基线中值,无论什么时候这个值达到一定的阈值,算法都认为已经获得了足够的视差,开始估计单应。然后,分解单应(矩阵);接着选择正确的相机位姿,路标对应的内点匹配会被三角化,用于估计初始场景的景深。在第二个图像作为第二个关键帧、送入地图管理线程之前,前2帧图像和它们关联的所有路标的捆集调整就开始运行了。
与PTAM一样,SVO的初始化要求同样的运动模型,倾向于突然运动和非平面场景;监控特征间的基线中值并不是一个用于选择一对初始关键帧的好方法,在退化状态下容易失效,而且没有办法检测到。
DT SLAM。DT SLAM没有外部初始化过程,用估计本质矩阵的方法,集成在跟踪模块中。表4总结了不同视觉SLAM系统所采用的初始化方法,在系统启动时对场景所做的配置。除了单目SLAM之外,本文提到的所有方法对于特定的场景都会受到退化的影响,也就是说在相机的低视差运动情况下,或者当场景结构对应的前提假设,即基本矩阵的前提是针对一般非2维场景,或者单应矩阵对应的平面场景,是不成立的。
表4:初始化
LSD SLAM。为了处理初始化问题,LSD SLAM从第1个视角随机初始化场景的深度,通过随后的图像进行优化。LSD SLAM初始化方法不需要使用两视图几何。不像其他SLAM系统跟踪两图像的特征,LSD SLAM只用单个图像进行初始化;兴趣像素点(高亮度梯度的图像位置)初始化时会被放入系统,深度随机分布、方差大。
第一个初始化的关键帧和后面的图像对齐后,跟踪直接开始。图像不断输入,初始特征的深度测量用滤波方法优化,直到收敛。这种方法不会因为两视图几何的原因退化;但估计深度在算法收敛之前需要处理大量图像,需要一个中间跟踪过程,生成的地图也不可靠。
DPPTAM。DPPTAM借用了LSD SLAM的初始化过程,因此,也会受到随机深度初始化的影响,在它得到一个稳定的配置之前,必须要往系统中加入几个关键帧。
为了解决上述局限,Mur-Artal建议并行计算基本矩阵和单应(用RANSAC算法),根据对称传输误差(多视图几何)处理不同的模型,最终是为了选择合适的模型。完成之后,就会进行适当的分解,在捆集调整优化地图之前,场景结构和相机位姿都会重构。如果选择的模型跟踪质量差,图像上的特征对应少,初始化就会迅速被系统丢弃,再用不同的图像进行重启动。值得注意的是,上述初始化方法,除单目SLAM以外,图像坐标和对应的3D坐标都可以由未知系数λ决定。
3.4 位姿估计
因为数据关联计算量巨大,大部分SLAM系统都有一个先决条件,即对于每个新图像的位姿,用于数据关联工作都有具体要求和限制。这个先决条件通常都是位姿估计的第一个任务。图7描述了位姿估计问题;两幅图像之间的地图和数据关联已知,先给定一个位姿,去估计第二幅图像的位姿。PTAM,DT SLAM,ORB SLAM,DPPTAM都在平滑的相机运动状态下采用恒定速度运动模型和用跟踪到的两幅图像的位姿变化估计当前图像的先验知识(先决条件)。但是,在相机运动方向上突然改变时,这样的模型就容易失效。LSD SLAM和SVO都假设在随后的图像上(这种情况下都是用高帧率相机),相机位姿没有明显改变,因此,他们给当前图像位姿和前一个跟踪到的图像分配相同的先验信息(先决条件)。
图7 视觉SLAM系统的位姿估计。
图8是位姿估计的一般流程。前一幅图像的位姿用于指导数据关联流程。它帮助地图中的当前图像获取一组可视化特征,从而减少盲目投影整个地图的计算开销。另外,它还可以估计当前图像的特征位置,这样特征匹配只在很小的区域内进行搜索,而不是搜索整个图像。最后,它还是用于优化相机位姿的最小化流程的起始点。
图8 位姿估计的一般流程
直接和间接方式都是最小化图像间的测量误差估计相机位姿;直接方法测量光度误差,间接方法通过最小化地图中图像上一位姿的路标的重投影误差估计相机位姿。重投影误差用图像之前位姿投影的3D路标和它对应的图像上的2D位置的像素距离构建函数。
图9 位姿估计的一般过程。Cm是用运动模型估计的新图像位姿,C2是真实的相机位姿。
图9演示了相机位姿是如何估计的。运动模型用于Cm处的新图像位姿,一列可见的地图3D路标重投影到新图像上。投影的路标周围有一个搜索窗口Sw用于数据关联。系统使用刚体变换参数最小化重投影误差d。为了获得对离群点(错误匹配的特征)的鲁棒性,目标函数最小化会处理掉重投影误差比较大的特征。
PTAM。PTAM用SE(3)变换表示相机位姿,最少可以用6个参数表示。SE(3)上的映射变换到它的最小表示Sξ(3),反过来也能通过李代数上的对数和指数映射解决。最小表示Sξ(3)变换非常重要,它将参数从12个减到6个,在优化过程中可以明显提速。
PTAM中,位姿估计流程是先用恒定速度运动模型估计一个图像位姿的先验信息。然后优化先验信息,用一个小的模糊图像代表这个图像,采用ESM算法(ESM 是 Efficient Second-order Minimization 的缩写,源自 Benhimane 和 Malis 在 2004年 在 IROS 上发表的工作。该算法采用重构误差平方作为衡量 R 和 T 相似性的指标,然后对于姿态空间进行了在李群(Lie Group)上的重新构建使得搜索的步长更为理性,在寻优上面使用的二阶近似的快速算法。这个算法的结构清晰,各模块都容易独立扩展,所以在其基础上衍生出了不少改进算法,通常是针对实用场景中不同的调整(比如处理强光照或者运动模糊)。)。先验信息(图像)的速度定义为当前图像的位姿估计与前一相机位姿的改变快慢。如果速率快,PTAM会预计到一个快速运动发生,那么运动状态就是模糊的;会导致程序失效,PTAM会限制跟踪线程使其只运行在最高层金字塔上(对运动模糊的弹性最大),这只是一个粗略的跟踪过程。但是,当相机静止时,这个粗糙的步骤可能会导致相机抖动---因此,它会被关闭。
初始相机先验信息(模糊图像)可以用最小化重投影误差的Tukey双向加权法来优化,向下权重观测值误差大。如果跟踪线程没有问题,就从金字塔最低层选取特征,上述流程就会被重复。
为了判断追踪的质量,PTAM中的位姿估计线程监控图像中成功匹配的特征的比率,而不是特征匹配的总数量。如果跟踪质量有问题,追踪线程还是会照常运行但是没有关键帧加入系统。如果连续3个图像都认为跟踪性能不好,跟踪就被认为是丢失了,失效恢复就启动了。
表5 总结了不同视觉SLAM的位姿估计方法。
SVO。SVO用金字塔算法中基于稀疏模型的图像对齐方法估计初始相机位姿。它先假定t时刻相机位姿与t-1时刻相机位姿相同,是为了最小化当前图像中已知深度的2D图像位置的光度误差,即同一位置的t-1(与t)时刻的,根据同幅图像的相关相机位姿变换不同。最小值取逆向合成图像对齐方法中高斯-牛顿算法的30次迭代值。然而对SVO引入了很多限制,因为ICIA要求图像间(1个像素)更小的位移。这就要求SVO使用高帧率相机(典型的是大于70fps)这样位移的限制就不会超出范围。还有,ICIA基于亮度一致性约束表现更容易因光照条件而变化。
SVO没有对每个图像采用外部特征匹配;但可以内在地通过图像对齐步骤来顺带获得。一但图像对齐,当前图像上的可见路标,就投影到图像上去。投影的路标2D位置可以用最小化区块内的光度误差调好,2D位置是从当前图像的初始投影位置中提取的,最近的关键帧生成的扭曲路标可以观察到。为了减小计算复杂度,只维护最强的特征,图像分成网格,每个网格只用到一个投影的路标(最强的)。然而,这个最小化违反了整幅图像的对极约束,但在跟踪模块中需要。单结构捆集调整优化路标的3D位置,在前一步骤中优化过相机位姿;然后再处理单运动捆集调整。
最后,联合(位姿和结构)局部捆集调整优化好相机位姿估计。在位姿估计模块中,跟踪的质量会持续监控;如果图像中的观测值数量低于某个阈值,或者如果连续图像间的特征数量下降过快,跟踪质量就不好,失效恢复就会启动。
DT SLAM。DT SLAM基于3个模式维护相机位姿:全位姿估计,本质矩阵估计和纯旋转估计。如果有足够数量的3D匹配,就可以估计完全位姿;否则,如果有足够多的2D匹配,平移也小,就会估计一个本质矩阵;最后,如果出现纯旋转状况,就会用2点估计匹配的绝对方向。位姿估计模块进行迭代处理3D-2D重投影和2D-2D匹配的最小化误差向量。如果跟踪丢失,系统就构建新地图,继续收集数据跟踪不同的地图;但,地图构建线程会继续同时查找新地图和老地图的关键帧之间的匹配,匹配建好后,地图就融合在一起,因此系统可以在不同的尺度上处理多个子图。
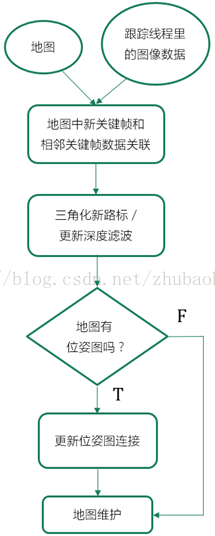
3.5 地图生成
地图生成模块将世界表示成稠密(直接)或稀疏(间接)的云点。图10是地图生成模块的一般流程。系统将2D兴趣点三角化成3D路标,并持续跟踪3D坐标,然后定位相机,这就是度量地图。但是,相机在大场景运行时,度量地图的大小就会无限增大,最终导致系统失效。
图10 地图生成的一般流程
逻辑地图可以减少这一弊端,它尽量将地图中的度量信息最小化,减少几何信息(尺度,距离和方向)而采用连接信息。视觉SLAM中,逻辑地图是一个无向图,节点通常表示关键帧,关键帧通过边连接,边缘是具有相同的数据的节点。
逻辑地图在大场景下尺度性能比较好,为了估计相机位姿,也需要度量地图;从逻辑地图到度量地图的变化并不是一件容易的事情,最近的视觉SLAM系统都采用混合地图,具有局部度量地图和全局逻辑地图。混合地图可以使系统: (1) 在高层次上理解世界,逻辑地图用于回环闭合和失效恢复更有效率;(2)将地图范围限制到相机周围的局部区域可以增加度量位姿估计的效率。
在度量地图中,地图制作过程会处理新路标添加到地图中,还有离群点检测和处理。场景的3D结构可以从2幅图像的变换和对应的数据关联中获得。由于数据关联的噪声和图像的位姿估计, 关联特征的投影射线在3D空间中不会相交。图11显示了优化的三角化方法,估计对应特征的路标位姿,可以最小化2图的重投影误差e1和e2。为了对离群点更有弹性,获得更好的精度,有些系统采用了相似的优化,这些特征关联的图像超过2个视图。
图11 优化路标三角化
图12 基于滤波方法的路标估计
图12所示,基于滤波的路标估计技术恢复路标位置,用路标位置均匀分布(D1)填入粒子滤波,路标可以在多个视图中观测到后就更新。这一过程会一直持续直到滤波从均匀分布到高斯小方差(D3)收敛。在这种类型的路标估计中,离群点很容易被识别为路标,这些离群点的分布基本保持一致。在路标用于位姿跟踪之前,基于滤波的方法会产生时间延迟,与优化三角化方法中2视图路标三角化后就可用的状况不同。
这些方法的主要局限是它们需要图像中观测特征的基线,当相机是纯旋转状态时,比较容易失效。为了控制这样的失效模式,DT SLAM 在将它们三角化成3D路标之前引入2D地图路标。
表6总结了不同视觉SLAM的地图生成方法,主要采用两种方法:优化三角化(PTAM和ORB SLAM)和基于滤波的路标估计(SVO,LSD SLAM和DPPTAM)。
表6 地图生成
非滤波单目视觉SLAM系统研究
非滤波单目视觉SLAM系统研究
A survey on non-filter-based monocular Visual SLAM systems
Taylor Guo, 2016年9月12日
摘要
滤波(卡尔曼滤波,粒子滤波)视觉SLAM更通用,非滤波(运动结构估计)方案更有效率。本文讲解各种视觉SLAM构建方法及其组成部分。
一 简介
基于相机的定位有两种方法。一种是基于图像的定位,需要先处理场景生成3D结构,场景图像和对应的相机视角。定位问题就可以变为将图像序列与数据库的进行匹配,和选择具有最佳匹配的相机位置。第二种技术是,没有先验场景信息;地图构建和定位同时进行、我们可以增量式地估计相机位姿------也就是视觉里程计;或者为了减少里程计中的漂移,在整个运行过程中维护地图和相机位姿。这个就是视觉SLAM。
二 概览
视觉SLAM方案可以基于滤波方案(卡尔曼滤波、粒子滤波),也可以基于非滤波方案(比如,将其视为优化问题)。图1a是滤波系统的不同部分的数据连接;相机位姿Tn估计需要使用地图中所有路标处理每幅图像并且更新。图1.b是非滤波系统,不同部分的数据连接,可以允许相机在Tn的位姿估计用整个地图的一个子集,不需要在每幅图像都更新地图数据。
三 视觉SLAM系统的设计
本章讨论视觉SLAM最近进展,分析最成功的开源非滤波方法视觉SLAM系统。具体讨论PTAM,SVO,DT SLAM, LSD SLAM, ORB SLAM, DPPTAM。一般的非滤波视觉SLAM系统主要有8部分组成,如图2所示,(1)数据输入类型,(2)数据关联,(3)初始化,(4)位姿估计,(5)地图生成,(6)地图维护,(7)失效恢复,(8)回环闭合。
我们会详细介绍每一部分,视觉SLAM如何执行这些模块。需要注意的是,这些系统的内参是已知的,已经离线标定好了。
3.1 输入数据类型
视觉SLAM方法被分为直接法,间接法,混合法。直接方法---也是稠密或半稠密方法---指的是采用图像上每个像素的信息(亮度值)估计描述相机位姿的参数。另外,间接法用于减少处理每个像素的计算复杂度;可以只使用显著的图像部位(即特征)用于位姿估计的计算(如图3 所示)。
3.1.1 直接方法
直接方法最基本的原理是亮度一致性约束,可以用一下公式描述:
J(x,y)=I(x+u(x,y)+v(x,y)), (1)
其中,x,y是像素坐标;u,v是同一场景的两幅图像I和J的像素(x,y)变换函数。每个像素都有一个亮度值,但它增加了2个未知数(u和v),系统变为欠定方程组,有2n个未知数但只有n个等式(其中n是图像上的像素数量)。为了解决这个问题,Lucas & Kanade采用 前向相加图像对齐Forward Additive Image Alignment 取代单一像素变换u和v的一般运动模型,这个模型参数的数量取决于运动类型。FAIA通过改变变换参数迭代地最小化模板和输入图像的像素亮度差值。为了减小计算复杂度,FAIA变化成其他形式,如 FCIA (Forward Compositional Image Alignment), ICIA (Inverse Compositional Image Alignment) and IAIA (Inverse Additive Image Alignment)。
直接方法使用了图像上所有的信息,在纹理较差的部分比间接法更鲁棒。但当场景中的光照变化后,直接法更容易失效,亮度一致性约束要求两幅图像之间的光度误差尽可能地小。第二个不利的因素是,每个像素的光度误差的计算非常密集;直接法的实时视觉SLAM的应用,之前认为一直不可行。由于最近出现了并行计算,直接法被整合到视觉SLAM中(比如DPPTAM, LSD-SLAM, SVO)。
3.1.2 间接方法
间接方法使用特征匹配。特征比较显著,对视角和光照变化具有不变性,对模糊和噪声有弹性。对纹理的提取计算高效快速。但这些目标很难同时获得,需要在计算速度和特征质量上取得平衡。
计算机视觉领域研究了很多不同的特征提取和特征描述,它们对旋转、尺度不变,和计算速度的性能都不一样。选择合适的特征检测依赖于平台的计算能力,视觉SLAM算法运行的环境,还有图像的帧率。特征检测有 Hessian corner detector (Beaudet, 1978), Harris detector (Harris and Stephens, 1988), Shi-Tomasi corners (Shi and Tomasi, 1994), Laplacian of Gaussian detector (Lindeberg, 1998), MSER (Matas et al, 2002), Difference of Gaussian (Lowe, 2004) and the accelerated segment test family of detectors (FAST, AGAST, OAST) (Mair et al, 2010).
为了降低计算要求,大部分间接系统使用FAST作为特征提取,与特征描述一起执行数据关联。特征描述包括但不限于BRIEF, BRISK, SURF, SIFT, HoG, FREAK, ORB 和低层像素级别局部区块。更多的有关特征提取和特征描述,可以参考论文综述。
3.1.3 混合方法
与直接法和间接法不同的,有的系统,比如SVO采用混合方法,用直接法构建特征对应,用间接法优化相机位姿估计。
表2总结了部分视觉SLAM系统使用的数据类型。开源的间接方法,PTAM, SVO, DT SLAM使用FAST特征, ORB SLAM使用ORB特征。
| PTAM | SVO | DT SLAM | LSD SLAM | ORB SLAM | DPPTAM | |
| 方法 | 间接法 | 混合法 | 间接法 | 直接法 | 间接法 | 直接法 |
3.2 数据关联
数据关联就是在不同图像之间建立对应关系作为视觉SLAM其他模块的输入。这步是系统必须的,采用直接方法,在相机位姿里面还会讨论直接方法的数据关联。
构建特征对应的间接方法有3种,2D-2D,3D-2D和3D-3D。
3.2.1 2D-2D
没有地图,也没有2幅图像的相机变换,也没有场景结构时,使用2D-2D的数据关联。为了减少计算时间,避免错误数据关联的可能性,第一幅图像的特征2D位置用作定义一个搜索窗口在第2幅图像中进行搜索。每个特征有个描述子,与其他特征的相似度进行定量对比。描述子距离函数随描述子类型变化:对于像素描述子的局部区块,通常使用模板(patch)匹配中差值的平方和(SSD),或者 为了增加对于光照变化的鲁棒性,使用零均值像素灰度差平方和 (ZMSSD)。对于高层特征描述子,比如ORB,SIFT和SURF,可能会采用L1范数(向量中各个元素绝对值之和,就是绝对值相加,又称曼哈顿距离),L2范数(就是欧几里德距离)和汉明距离;但用这些方法做匹配计算量比较大,稍不注意可能会降低实时性能。这样,就采用特别的检索和执行方法来处理特征匹配,采用KD树或词袋。
3.2.2 3D-2D
图4是3D-2D数据关联问题,前一相机位姿估计和3D结构已知,需要估计2D特征和3D路标影射的对应关系,这个3D路标影射到一个新的图像中并没有预先知道这两个图像之间的确切运动过程。这种数据关联方法在视觉SLAM的位姿估计中非常常用。
3.2.3 3D-3D
估计和校正回环的累积漂移,就需要3D-3D的数据关联,2幅图像中观测到的3D路标的描述子可以与将要探测的路标之间进行匹配用于两个图像间的相似变换。表3总结了各种开源视觉SLAM系统采用的特征类型和描述子。
| PTAM | SVO | DT SLAM | LSD SLAM | ORB SLAM | DPPTAM | |
| 特征
类型 | FAST | FAST | FAST | 无 | FAST | 无 |
| 特征
描述 | 像素局部模板 | 像素局部模板 | 像素局部模板 | 像素局部模板 | ORB | 像素局部模板 |
表3:特征提取和描述子。像素局部模板:Local patch of pixels。
PTAM。PTAM成功初始化之后,每个图像会生成一个4层金字塔(比如,第一层:640x480,第二层:320x240)。金字塔可以使特征对于尺度变换更鲁棒,从而降低位姿估计模块的收敛半径。每层都会提取FAST特征并且每个特征都会计算Shi-Tomasi分值;在执行非极大值抑制(Non-maximum suppression)算法之前会去除低于一个Shi-Tomasi门限值的特征。这样是为了确保提取的特征的高度显著性,并限制它们的数量,可以使计算复杂度可控制。
每层金字塔都有不同的Shi-Tomasi门限值和非极大值抑制;从而可以控制特征强度和数量,在每层金字塔都可以追踪到。然后,用已知的位姿估计将3D路标影射到新图像上去,同样的方式用于2D-2D方法,在射影的路标位置附近的搜索窗口中构建特征匹配。3D路标特征匹配的描述子通常从2D图像中提取,在这个2D图像中已经提前观测到了3D路标;然而,当相机视角观察到显著变化,或者由于像素局部模板弯曲引起视角变化,有些系统建议更新描述子。
DT SLAM。与PTAM类似,DT SLAM采用相同的机制构建2D-3D特征匹配。
SVO。SVO中图像有5层金字塔:通过迭代执行直接图像对准方案从最高层金字塔到第3层金字塔进行数据关联。这一步的初步数据关联作为FAST特征匹配过程的已知知识,与PTAM保持显著性的图像变形技术相似,使用零均值像素灰度差平方和 (ZMSSD) 。
ORB SLAM 。ORB SLAM在8层金字塔上都提取FAST角点。为了确保整幅图像的一致性分布,每层金字塔被分成小单元格,FAST特征检测的参数可以在线调整以确保每个单元格至少提取5个角点。然后每个提取的特征计算256位ORB特征描述子。高层的ORB特征描述子用于建立特征间的对应关系。ORB SLAM把描述子分散存储到词袋中,也就是视觉字典,约束字典树上相同节点下的特征可以加速图像和特征匹配。
3.3 初始化
单目视觉SLAM系统需要进行初始化,这一过程主要生成3D路标地图和初始相机位姿。相同的场景要从同一基线的不同视角分离开。图5是视觉SLAM系统的初始化,只知道2幅图像间的关联数据,初始相机位姿和场景结构都是未知的。
早期视觉SLAM系统,比如单目视觉SLAM,系统初始化要求相机摆放在距平面场景已知距离的地方,场景由4个角和2维平面组成,SLAM通过操作人员输入距离值实现初始化。
PTAM。图6显示了基于模型初始化的一般流程,比如PTAM,SVO,ORB SLAM。为了避免用户手动输入深度信息,PTAM使用5点算法估计和分解基本矩阵到非平面初始场景。后来PTAM初始化做了改变,使用单应,此时场景应该由2D平面组成。PTAM初始化要求用户两次输入获取地图中的前2个关键帧;它还需要用户在第一个和第二个关键帧之间,与场景平行地执行一个缓慢的,平滑的,相对明显的平移运动。
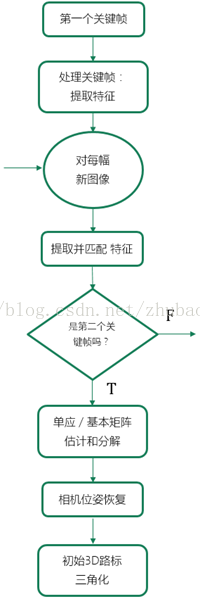
图6 初始化的一般流程
从第1个关键帧提取的FAST特征,后来的每一帧图像中,用2D-2D数据关联方法追踪,直到用户插入第2个关键帧。 匹配过程采用ZMSSD,不需要保持显著性的图像特征的变形技术,构建角点匹配的过程对运动模糊和由于相机旋转造成明显的外观特征改变比较敏感,因此,要在初始化过程中对用户的运动状态严格要求。为了使匹配错误最小化,特征需要搜索2遍;第一次从当前帧到上一帧,第二次从相反的方向搜索。如果两个方向的匹配不一致,特征就会被丢弃。PTAM初始化使用单应估计,那么初始化过程中的场景就应该是2维的。一旦第2个关键帧成功地放入地图中,一个随机抽样最大似然估计(Maximum Likelihood Estimation by Sample and Consensus, MLESAC)回环使用构建好的匹配生成一个单应,这个单应是在2个关键帧间的,在分解成8个可能的方案之前使用内点进行优化。选择正确的相机位姿对,这样所有三角化过的3D点就不会生成不真实的配置(两幅图中的逆深度)。
生成的初始地图大小可以变化,这样前两个关键帧之间估计的平移变换就可以对应成0.1个单位,在这之前仅基于结构的捆集调整BA(只优化路标的3D位姿)就会先运行。选用3D路标的均值作为世界坐标,同时选择z轴的正方向作为相机位姿的正方向。
PTAM初始化程序非常脆弱,需要技巧去运行,尤其是对于没有经验的用户。还有,初始化场景不是2维平面,或用户运动状态不恰当的时候,系统退化,容易崩溃,这样的退化无法检测。
SVO。类似的,SVO使用单应进行初始化,但SVO不需要用户输入,算法使用系统启动时的第一个关键帧;提取FAST特征,用图像间的KLT算法跟踪特征(KLT(Kanade-Lucas-Tomasi)算法是计算机视觉的跟踪算法,通过基于平移模型进行灰度匹配来实现特征点的跟踪,并进行基于跟踪算法的特征点选择,提高特征点跟踪质量。通过特征点选择算法在起始图像中选择特征点,然后利用平移模型进行特征点跟踪,对于第N幅图像上跟踪到的特征点,通过仿射模型进行连续性判断,对跟踪错误的特征点进行剔除。KLT算法中在研究不同图像之间的匹配问题时,通过计算两个平移窗口的灰度残差,并寻找最小化残差SSD(sum of square difference)来实现匹配。在优化过程中,KLT算法使用泰勒展开直接计算平移矢量,而不需要通过遍历进行搜索;同时使用Newton-Raphson迭代算法来避免泰勒展开带来的误差。)为了避免用户二次输入,SVO监控第一个关键帧和当前图像间的特征点基线中值,无论什么时候这个值达到一定的阈值,算法都认为已经获得了足够的视差,开始估计单应。然后,分解单应(矩阵);接着选择正确的相机位姿,路标对应的内点匹配会被三角化,用于估计初始场景的景深。在第二个图像作为第二个关键帧、送入地图管理线程之前,前2帧图像和它们关联的所有路标的捆集调整就开始运行了。
与PTAM一样,SVO的初始化要求同样的运动模型,倾向于突然运动和非平面场景;监控特征间的基线中值并不是一个用于选择一对初始关键帧的好方法,在退化状态下容易失效,而且没有办法检测到。
DT SLAM。DT SLAM没有外部初始化过程,用估计本质矩阵的方法,集成在跟踪模块中。表4总结了不同视觉SLAM系统所采用的初始化方法,在系统启动时对场景所做的配置。除了单目SLAM之外,本文提到的所有方法对于特定的场景都会受到退化的影响,也就是说在相机的低视差运动情况下,或者当场景结构对应的前提假设,即基本矩阵的前提是针对一般非2维场景,或者单应矩阵对应的平面场景,是不成立的。

表4:初始化
LSD SLAM。为了处理初始化问题,LSD SLAM从第1个视角随机初始化场景的深度,通过随后的图像进行优化。LSD SLAM初始化方法不需要使用两视图几何。不像其他SLAM系统跟踪两图像的特征,LSD SLAM只用单个图像进行初始化;兴趣像素点(高亮度梯度的图像位置)初始化时会被放入系统,深度随机分布、方差大。
第一个初始化的关键帧和后面的图像对齐后,跟踪直接开始。图像不断输入,初始特征的深度测量用滤波方法优化,直到收敛。这种方法不会因为两视图几何的原因退化;但估计深度在算法收敛之前需要处理大量图像,需要一个中间跟踪过程,生成的地图也不可靠。
DPPTAM。DPPTAM借用了LSD SLAM的初始化过程,因此,也会受到随机深度初始化的影响,在它得到一个稳定的配置之前,必须要往系统中加入几个关键帧。
为了解决上述局限,Mur-Artal建议并行计算基本矩阵和单应(用RANSAC算法),根据对称传输误差(多视图几何)处理不同的模型,最终是为了选择合适的模型。完成之后,就会进行适当的分解,在捆集调整优化地图之前,场景结构和相机位姿都会重构。如果选择的模型跟踪质量差,图像上的特征对应少,初始化就会迅速被系统丢弃,再用不同的图像进行重启动。值得注意的是,上述初始化方法,除单目SLAM以外,图像坐标和对应的3D坐标都可以由未知系数λ决定。
3.4 位姿估计
因为数据关联计算量巨大,大部分SLAM系统都有一个先决条件,即对于每个新图像的位姿,用于数据关联工作都有具体要求和限制。这个先决条件通常都是位姿估计的第一个任务。图7描述了位姿估计问题;两幅图像之间的地图和数据关联已知,先给定一个位姿,去估计第二幅图像的位姿。PTAM,DT SLAM,ORB SLAM,DPPTAM都在平滑的相机运动状态下采用恒定速度运动模型和用跟踪到的两幅图像的位姿变化估计当前图像的先验知识(先决条件)。但是,在相机运动方向上突然改变时,这样的模型就容易失效。LSD SLAM和SVO都假设在随后的图像上(这种情况下都是用高帧率相机),相机位姿没有明显改变,因此,他们给当前图像位姿和前一个跟踪到的图像分配相同的先验信息(先决条件)。
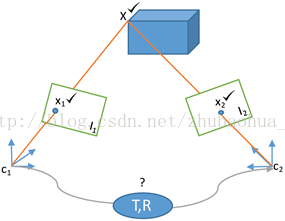
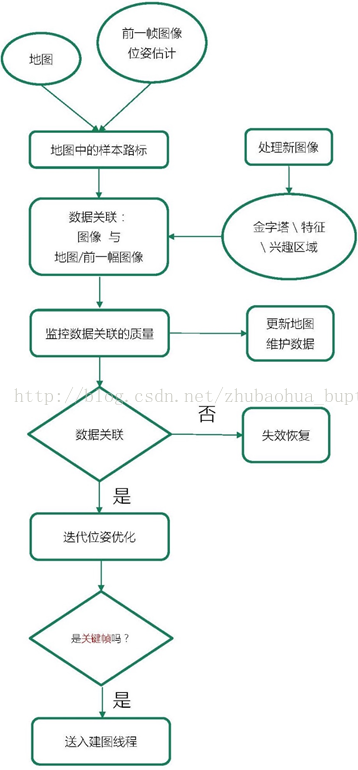
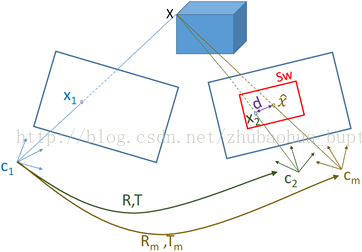
图9演示了相机位姿是如何估计的。运动模型用于Cm处的新图像位姿,一列可见的地图3D路标重投影到新图像上。投影的路标周围有一个搜索窗口Sw用于数据关联。系统使用刚体变换参数最小化重投影误差d。为了获得对离群点(错误匹配的特征)的鲁棒性,目标函数最小化会处理掉重投影误差比较大的特征。
PTAM。PTAM用SE(3)变换表示相机位姿,最少可以用6个参数表示。SE(3)上的映射变换到它的最小表示Sξ(3),反过来也能通过李代数上的对数和指数映射解决。最小表示Sξ(3)变换非常重要,它将参数从12个减到6个,在优化过程中可以明显提速。
PTAM中,位姿估计流程是先用恒定速度运动模型估计一个图像位姿的先验信息。然后优化先验信息,用一个小的模糊图像代表这个图像,采用ESM算法(ESM 是 Efficient Second-order Minimization 的缩写,源自 Benhimane 和 Malis 在 2004年 在 IROS 上发表的工作。该算法采用重构误差平方作为衡量 R 和 T 相似性的指标,然后对于姿态空间进行了在李群(Lie Group)上的重新构建使得搜索的步长更为理性,在寻优上面使用的二阶近似的快速算法。这个算法的结构清晰,各模块都容易独立扩展,所以在其基础上衍生出了不少改进算法,通常是针对实用场景中不同的调整(比如处理强光照或者运动模糊)。)。先验信息(图像)的速度定义为当前图像的位姿估计与前一相机位姿的改变快慢。如果速率快,PTAM会预计到一个快速运动发生,那么运动状态就是模糊的;会导致程序失效,PTAM会限制跟踪线程使其只运行在最高层金字塔上(对运动模糊的弹性最大),这只是一个粗略的跟踪过程。但是,当相机静止时,这个粗糙的步骤可能会导致相机抖动---因此,它会被关闭。
初始相机先验信息(模糊图像)可以用最小化重投影误差的Tukey双向加权法来优化,向下权重观测值误差大。如果跟踪线程没有问题,就从金字塔最低层选取特征,上述流程就会被重复。
为了判断追踪的质量,PTAM中的位姿估计线程监控图像中成功匹配的特征的比率,而不是特征匹配的总数量。如果跟踪质量有问题,追踪线程还是会照常运行但是没有关键帧加入系统。如果连续3个图像都认为跟踪性能不好,跟踪就被认为是丢失了,失效恢复就启动了。
表5 总结了不同视觉SLAM的位姿估计方法。

SVO。SVO用金字塔算法中基于稀疏模型的图像对齐方法估计初始相机位姿。它先假定t时刻相机位姿与t-1时刻相机位姿相同,是为了最小化当前图像中已知深度的2D图像位置的光度误差,即同一位置的t-1(与t)时刻的,根据同幅图像的相关相机位姿变换不同。最小值取逆向合成图像对齐方法中高斯-牛顿算法的30次迭代值。然而对SVO引入了很多限制,因为ICIA要求图像间(1个像素)更小的位移。这就要求SVO使用高帧率相机(典型的是大于70fps)这样位移的限制就不会超出范围。还有,ICIA基于亮度一致性约束表现更容易因光照条件而变化。
SVO没有对每个图像采用外部特征匹配;但可以内在地通过图像对齐步骤来顺带获得。一但图像对齐,当前图像上的可见路标,就投影到图像上去。投影的路标2D位置可以用最小化区块内的光度误差调好,2D位置是从当前图像的初始投影位置中提取的,最近的关键帧生成的扭曲路标可以观察到。为了减小计算复杂度,只维护最强的特征,图像分成网格,每个网格只用到一个投影的路标(最强的)。然而,这个最小化违反了整幅图像的对极约束,但在跟踪模块中需要。单结构捆集调整优化路标的3D位置,在前一步骤中优化过相机位姿;然后再处理单运动捆集调整。
最后,联合(位姿和结构)局部捆集调整优化好相机位姿估计。在位姿估计模块中,跟踪的质量会持续监控;如果图像中的观测值数量低于某个阈值,或者如果连续图像间的特征数量下降过快,跟踪质量就不好,失效恢复就会启动。
DT SLAM。DT SLAM基于3个模式维护相机位姿:全位姿估计,本质矩阵估计和纯旋转估计。如果有足够数量的3D匹配,就可以估计完全位姿;否则,如果有足够多的2D匹配,平移也小,就会估计一个本质矩阵;最后,如果出现纯旋转状况,就会用2点估计匹配的绝对方向。位姿估计模块进行迭代处理3D-2D重投影和2D-2D匹配的最小化误差向量。如果跟踪丢失,系统就构建新地图,继续收集数据跟踪不同的地图;但,地图构建线程会继续同时查找新地图和老地图的关键帧之间的匹配,匹配建好后,地图就融合在一起,因此系统可以在不同的尺度上处理多个子图。
3.5 地图生成
地图生成模块将世界表示成稠密(直接)或稀疏(间接)的云点。图10是地图生成模块的一般流程。系统将2D兴趣点三角化成3D路标,并持续跟踪3D坐标,然后定位相机,这就是度量地图。但是,相机在大场景运行时,度量地图的大小就会无限增大,最终导致系统失效。
逻辑地图可以减少这一弊端,它尽量将地图中的度量信息最小化,减少几何信息(尺度,距离和方向)而采用连接信息。视觉SLAM中,逻辑地图是一个无向图,节点通常表示关键帧,关键帧通过边连接,边缘是具有相同的数据的节点。
逻辑地图在大场景下尺度性能比较好,为了估计相机位姿,也需要度量地图;从逻辑地图到度量地图的变化并不是一件容易的事情,最近的视觉SLAM系统都采用混合地图,具有局部度量地图和全局逻辑地图。混合地图可以使系统: (1) 在高层次上理解世界,逻辑地图用于回环闭合和失效恢复更有效率;(2)将地图范围限制到相机周围的局部区域可以增加度量位姿估计的效率。
在度量地图中,地图制作过程会处理新路标添加到地图中,还有离群点检测和处理。场景的3D结构可以从2幅图像的变换和对应的数据关联中获得。由于数据关联的噪声和图像的位姿估计, 关联特征的投影射线在3D空间中不会相交。图11显示了优化的三角化方法,估计对应特征的路标位姿,可以最小化2图的重投影误差e1和e2。为了对离群点更有弹性,获得更好的精度,有些系统采用了相似的优化,这些特征关联的图像超过2个视图。
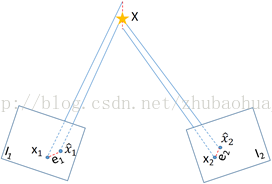
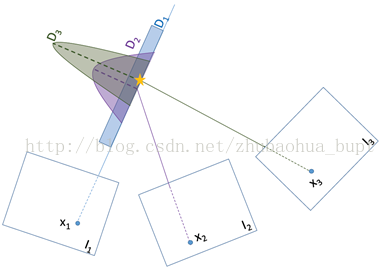
图12所示,基于滤波的路标估计技术恢复路标位置,用路标位置均匀分布(D1)填入粒子滤波,路标可以在多个视图中观测到后就更新。这一过程会一直持续直到滤波从均匀分布到高斯小方差(D3)收敛。在这种类型的路标估计中,离群点很容易被识别为路标,这些离群点的分布基本保持一致。在路标用于位姿跟踪之前,基于滤波的方法会产生时间延迟,与优化三角化方法中2视图路标三角化后就可用的状况不同。
这些方法的主要局限是它们需要图像中观测特征的基线,当相机是纯旋转状态时,比较容易失效。为了控制这样的失效模式,DT SLAM 在将它们三角化成3D路标之前引入2D地图路标。
表6总结了不同视觉SLAM的地图生成方法,主要采用两种方法:优化三角化(PTAM和ORB SLAM)和基于滤波的路标估计(SVO,LSD SLAM和DPPTAM)。
表6 地图生成



















 7546
7546


 到【灌水乐园】发言
到【灌水乐园】发言








