








Title: VisorGPT: Learning Visual Prior via Generative Pre-Training
Paper: https://arxiv.org/abs/2305.13777
Code: https://github.com/Sierkinhane/VisorGPT
导读

可控扩散模型如ControlNet、T2I-Adapter和GLIGEN等可通过额外添加的空间条件如人体姿态、目标框来控制生成图像中内容的具体布局。使用从已有的图像中提取的人体姿态、目标框或者数据集中的标注作为空间限制条件,上述方法已经获得了非常好的可控图像生成效果。
那么,如何更友好、方便地获得空间限制条件?或者说如何自定义空间条件用于可控图像生成呢?例如自定义空间条件中物体的类别、大小、数量、以及表示形式(目标框、关键点、和实例掩码)。
本文将空间条件中物体的形状、位置以及它们之间的关系等性质总结为视觉先验(Visual Prior),并使用Transformer Decoder以Generative Pre-Training的方式来建模上述视觉先验。因此,我们可以从学习好的先验中通过Prompt从多个层面,例如表示形式(目标框、关键点、实例掩码)、物体类别、大小和数量,来采样空间限制条件。
我们设想,随着可控扩散模型生成能力的提升,以此可以针对性地生成图像用于特定场景下的数据补充,例如拥挤场景下的人体姿态估计和目标检测。
动机
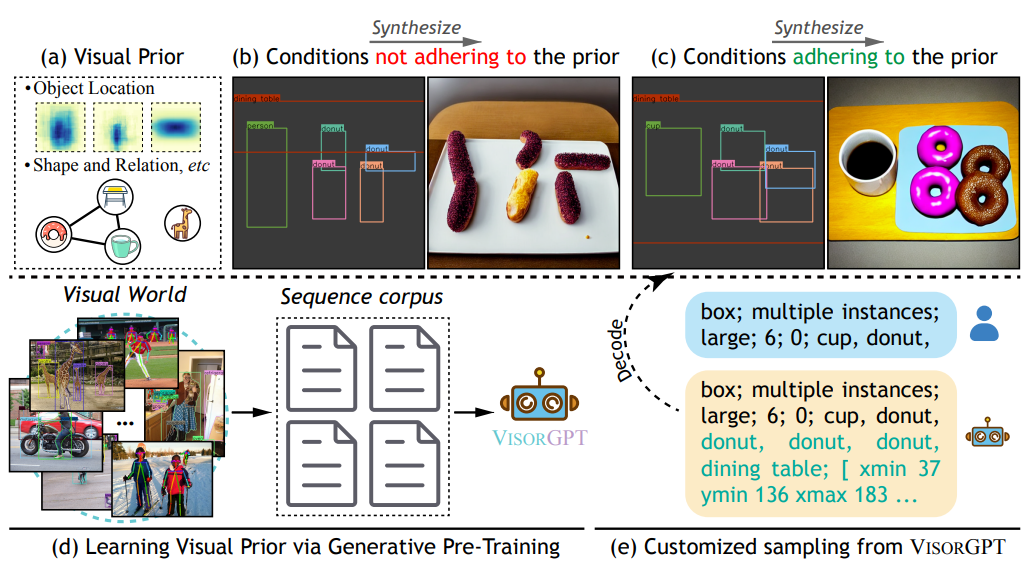
先来看下上面的示意图,这里:
(a):视觉先验(visual prior)的概念,指代场景中对象的位置、形状和关系等元素。
(b):展示了一个合成图像失败的案例,其中图像合成的空间条件不符合先验要求。具体来说,一个“甜甜圈”的形状不是正方形,并且它悬浮在空中而不是放在“餐桌”上。
©:展示了一个成功的案例,其中从VISORGPT中采样的条件导致了更准确的合成结果。
(d):说明了VISORGPT通过从视觉世界中转换为序列语料库来学习视觉先验。
(e):给出了一个示例,展示了用户如何通过提示(prompt)自定义从VISORGPT中采样的结果。
这些内容在总体上旨在阐明作者的研究目标和方法,以及VISORGPT对于学习视觉先验的应用和定制化采样的能力。
方法
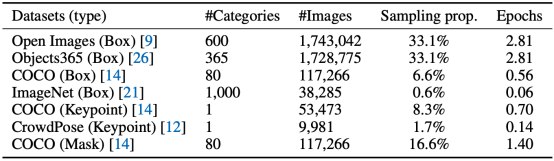
本文从当前公开的数据集中整理收集了七种数据,如表1所示。为了以 Generative Pre-Training 的方式学习视觉先验并且添加序列输出的可定制功能。
以下是论文提出的两种Prompt模板:

使用上述模板可以将表1中训练数据中每一张图片的标注格式化成一个序列 x x x。在训练过程中,我们使用 BPE 算法将每个序列 x x x 编码成 t o k e n s = u 1 , u 2 , … , u 3 tokens={u_1,u2,…,u3} tokens=u1,u2,…,u3,并通过极大化似然来学习视觉先验,如下所述:
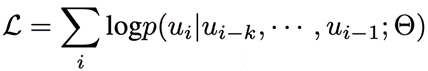
最后,我们可以从上述方式学习获得的模型中定制序列输出,如下图所示:

效果

总结
本文主要为大家介绍了VISORGPT方法,这是一种通过生成式预训练学习视觉先验的机制。它利用序列数据和语言建模的方法来学习关于位置、形状和类别之间关系的先验知识,并提供了对学习先验进行定制化采样的方法。

















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











