






作者 | 汽车人 编辑 | 汽车人
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
后台回复【2D检测综述】获取鱼眼检测、实时检测、通用2D检测等近5年内所有综述!
检测 transformer(DETR)通过在训练期间使用一对一二分匹配将查询直接转换为唯一对象,并实现端到端目标检测。最近,这些模型以无可否认的优雅超越了COCO上的传统检测器,然而它们在多个设计(包括模型架构和训练)上与传统检测器不同,因此一对一匹配的有效性尚未完全理解。本文对DETR中的一对一匈牙利匹配和具有NMS的传统检测器中的一到多标签分配进行了严格的比较。令人惊讶的是,观察到NMS的一对多分配在相同设置下始终优于标准的一对一匹配,显著增益高达2.5%mAP。本文的检测器使用ResNet50主干在12个epoch内实现了COCO 50.2% mAP,在这种设置下优于所有现有的传统或基于transformer的检测器。在多个数据集、时间表和架构上一致地表明,对于高性能的检测transformer来说,二分匹配是不必要的。此外,论文将检测transformer的成功归因于其可解释性transformer架构!
代码链接:https://github.com/jozhang97/DETA
领域背景
传统的目标检测器将检测视为region(two-stage)或锚点(one-stage)分类,它们将GT标签分配给一个或多个区域/锚点,并为每个对象生成一组重叠预测。然后通过后处理(即非最大抑制(NMS))去除重复项。最近基于transformer的检测器通过严格的一对一二分匹配损失在训练中学习抑制策略。经过两年令人兴奋的发展,端到端检测器已经取得了重大进展,最近超过了最佳传统检测器的性能。然而,检测transformer与传统检测器在不同轴上有所不同:具有匈牙利匹配的端到端设计、更重的架构(12个attention层对2个线性层)、更长的训练计划(50–500个epoch vs 12个epoch)等,这使得准确确定哪些因素对良好的整体性能有着挑战性。
在本文中作者纠正了一个普遍认为的误解,即一对一映射对于高性能检测至关重要。相反,传统的一对多训练目标产生了同样熟练的检测transformer。论文设计了一个基于transformer的目标检测器,它像传统检测器一样直接为每个查询分配正负标签,并使用NMS来删除重复的预测,而不是使用端到端的一对一匹配。作者将检测器命名为DETA(带分配的检测transformer)。具体而言,论文遵循两阶段DETR框架,并在两个阶段中用一对多基于IoU的分配损失来替换一对一的匈牙利匹配损失。在第一阶段,使用IoU度量将来自transformer编码器的锚点分配给annotations 或背景;在第二阶段,类似地分配查询。论文的检测器产生重叠目标,并使用NMS进行后处理,DETA具有与其端到端对应的完全相同的体系结构。
本文的混合架构允许与端到端transformer检测器和传统检测器进行严格比较,与传统检测器相比,DETA具有更具表现力的头部:在第一阶段,DETA在卷积主干上使用6层transformer编码器,而传统RPN或RetinaNet使用2到4个卷积层;在第二阶段,DETA使用6层transformer解码器,而传统FasterRCNN使用2个线性层。与端到端transformer检测器相比,DETA仅在训练损耗方面有所不同,具有完全相同的架构。训练损失的有效性来自两个方面。首先,一对多映射产生更多的总体正预测,有助于加快模型收敛。其次使用了一种有助于稳定小对象匹配的目标平衡技术,这在端到端检测器中尤其具有挑战性,作者在受控实验中验证了这两种性质的优点。
论文显示,在可变形DETR中从标准二分匹配切换到我们的IoU分配带来了2.5%mAP改善,论文的模型收敛得更快 在标准1×schedule (12个epoch)和ResNet50主干下,COCO上的性能为50.2mAP。这比最好的基于NMS的检测器(CenterNet2的42.9 mAP)高7.3点,比强的端到端检测器(DINO的49.4 mAP)好0.8点。论文观察在不同的检测transformer架构(DETR和可变形DETR)和数据集(COCO和LVIS)中是一致的。
一些相关的工作
传统的基于NMS的检测器将输入图像映射到下采样的密集特征图。特征图中的每个像素都被分类为对象类或背景,从而导致每个目标的重叠预测。RetinaNet和YOLO通过预定义的IoU阈值定义目标或背景,CenterNet、FCOS、ATSS和GFL将基于IoU的正负定义改进为自适应标准。虽然多种积极选择策略与论文的方法兼容,但作者使用了最常见和最直接的固定IoU阈值。可选地,可以通过第二阶段来改进基于NMS的检测器,其中使用IoU阈值来细化区域特征。同样,第二级输出是重复的,需要NMS进行后处理。本文的工作使用了传统检测器中基于IoU的简单标准,但也使用了transformer架构。
端到端检测器。DETR通过使用self-attention将查询直接映射到唯一对象来消除检测器预测中的重复。vanilla DETR很难训练,并通过多次后续工作进行了改进。可变形DETR通过可变形操作引入多尺度特征,可变形DETR、TSP-RCNN和EfficientDETR将学习的对象查询识别为缓慢收敛的原因因素,并用第一阶段检测器替换它们。ConditionalDETR和DAB-DETR将隐式查询具体化为显式点位置或框,DN-DETR通过添加辅助查询去噪损失来简化一对一匹配任务。DINO结合了两阶段查询和学习查询,最终超过了任何现有的基于NMS的检测器的性能。所有这些工作都带来了基于NMS的检测器的部分智慧,但保持匈牙利匹配损失不变。本文的工作是对这些想法的补充:作者表明,简单的匹配变化可以提供显著的改进。GroupDETR和H-DETR同时将一对一匹配识别为训练瓶颈。它们在transformer解码器中使用附加查询进行训练,以增加匹配查询的数量,并观察到更快的收敛和更好的性能。这验证了更多的阳性样本有帮助。FQDet发现,传统检测器的技术,如IoU分配和多锚定比率,提高了检测transformer的收敛性,然而,它们并没有像本文的检测transformer那样表现出显著的性能改进。除了添加NMS之外,本文的检测器不修改架构,只修改训练损失。
DETA
DETA改变等式(1)中的赋值过程,论文密切关注传统两级检测器的分配策略。首先放松了一对一匹配约束,而是允许一对多赋值,论文允许将多个输出i和j分配给相同的GT σi=σj。其次,论文切换到基于固定重叠的分配策略,而不是方程(1)中基于损失的匹配。
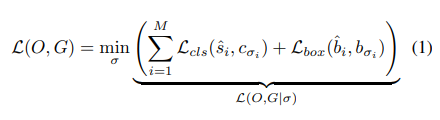
等式1为DETR中的优化目标!
First stage assignments
论文从可变形DETR架构导出的固定初始查询特征F开始,每个查询i都锚定在图像中的特定位置(xi,yi)。然而,提案没有框重叠度量所需的自然宽度和高度。作者使用恒定的box大小和,其中{,,}是特征分辨率,W和H是图像的宽度和高度。这将生成初始框定义,作者将这些初始框用于位置嵌入和基于重叠的赋值过程,如果重叠大于阈值τ,将每个预测i分配给最高重叠的GT!
在训练开始时,GT有时没有与阈值τ重叠的预测,无论保持目标不匹配还是分配给最近的不匹配预测,都没有发现差异。为了数学上的方便,假设后者,如果条件为:
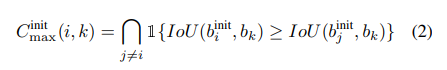
满足,然后,分配程序为:
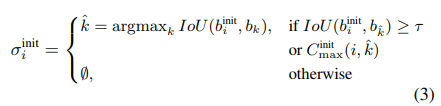
本文使用阈值τ=0.7作为第一阶段,由于第一阶段使用每个查询特征的单个框宽度和高度,因此得到的重叠度量IoU与无锚检测器中的中心度估计非常相似。
Second stage assignments
第二阶段的分配程序紧跟第一阶段的分配过程。然而,论文使用第一阶段的输出来定义一个等价的赋值σ,而不是使用一组固定的初始框,本文使用与DETR ,σ相同的loss来训练第二阶段。遵循Faster RCNN,论文使用超参数γ平衡前景目标比率,具体来说,当肯定查询的数量大于N×。为了鼓励更多的postive查询,将第二阶段的重叠标准放宽到τ=0.6。这种重叠标准的简单放松已经适用于大多数中等大小和大型目标,但是,小目标采样不足!
目标平衡
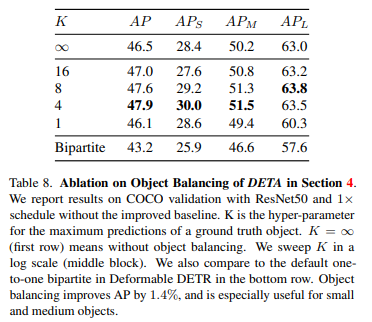
与一对一映射不同的是,对于每个GT,总是有一个匹配的预测,本文的IoU分配可能会在GT目标之间分配数量有着显著不同的预测。较大的目标自然比较小的目标更可能包含许多重叠的预测,这种不平衡会影响性能。作者提出了一种简单的目标平衡技术,对每个GT最多采样n个正赋值,设µ是annotation k的第n个最高IoU,µτ,µ 是新的动态阈值,作者修改了等式(3)中的赋值过程:
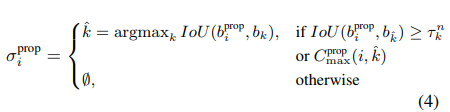
实验
本文在COCO和LVIS数据集上进行了实验,以mAP指标为准!具体而言,在第一阶段设置IoU阈值τ0=0.7,在第二阶段设置τ=0.6。前景比率γ在第一和第二阶段分别为0.5和0.25,在第一和第二阶段使用0.9、0.7的NMS阈值。NMS之前,在第一阶段过滤到每个功能级别1000个box,在第二阶段过滤到10000个box,设置了目标平衡参数K=4(第4节),如表8所示。
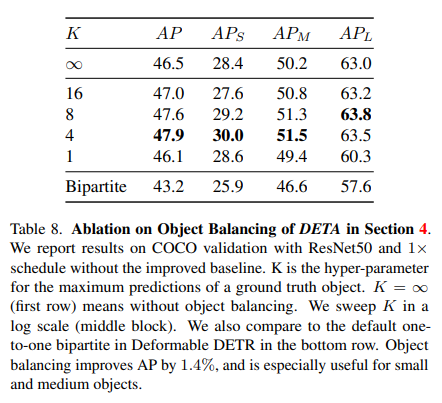
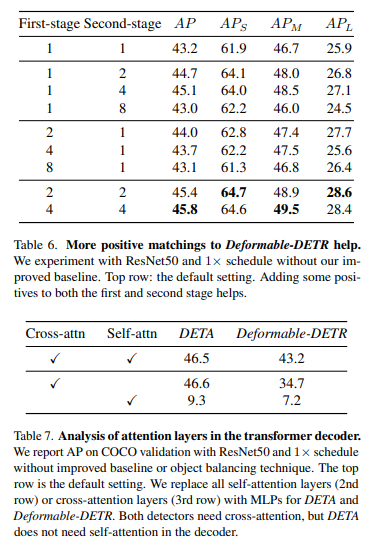
论文将来自原始DETR的匈牙利匹配与表1中多个数据集和架构下的IoU分配进行了比较,在1×schedule下使用COCO上的可变形DETR架构进行评估,在50 epoch下使用COCO上的DETR架构(LVIS在180k次迭代下)。首先报告了原始2级可变形DETR的结果,以及第5.1节所述的改进基线。从改进的基线来看,简单地用简单的传统IoU分配替换匈牙利匹配,NMS在COCO上提高了1.0 mAP。除了NMS,这些改进没有额外的成本,NMS只需几毫秒即可运行,这表明传统的重叠分配同样可以训练transformer。
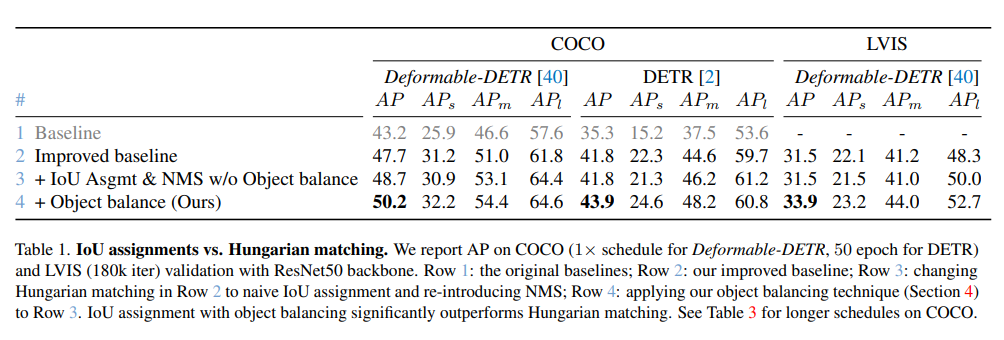
然而,仅通过分配,LVIS AP和DETR的COCO AP没有变化。在LVIS上,传统分配在小目标AP上表现不佳(21.5对22.1),而在大目标AP上则表现出色(50.0对48.3)。在DETR中也看到了这种趋势,COCO上小目标AP从22.3下降到21.3,大目标AP从59.7上升到61.2。假设传统的赋值会导致每个对象的正样本数不平衡,因为较大的对象有更多的匹配。进一步平衡匹配GT的数量会在所有设置上带来额外的增益,在LVIS上,目标平衡将AP提高2.4点。在COCO上,目标平衡分别为可变形DETR和普通DETR提高了1.5、2.1 mAP的性能。对于COCO上的小物体,这种改进更为明显。
和其它SOTA模型对比
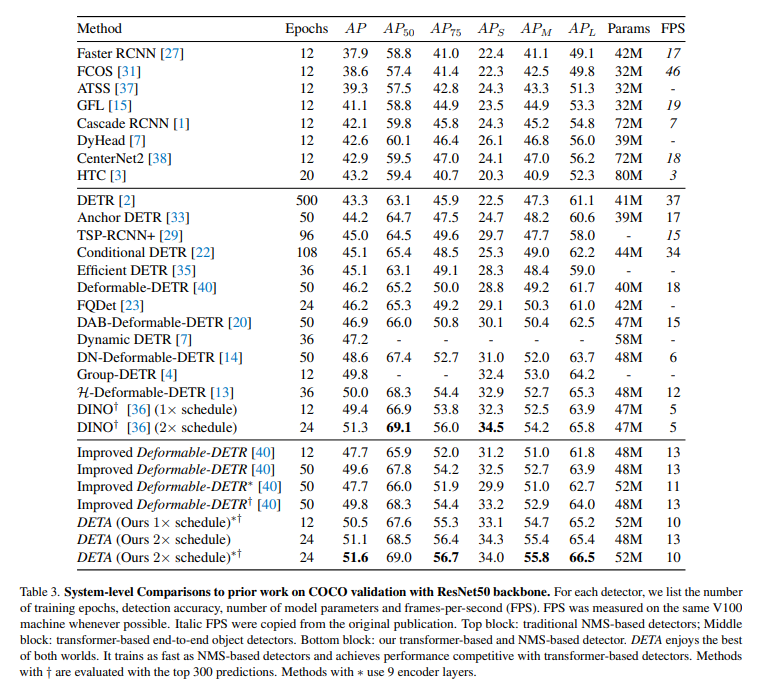
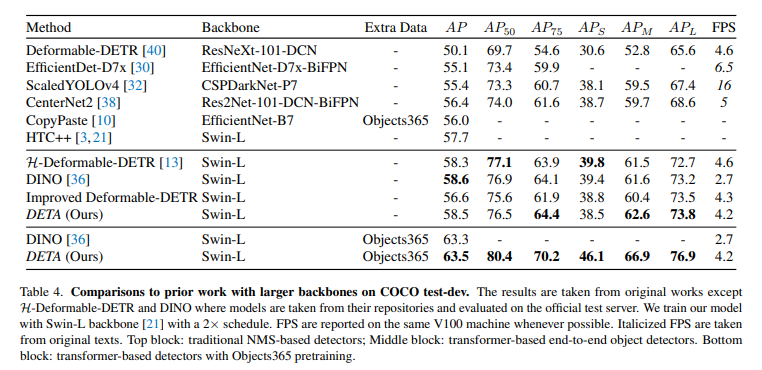
消融实验对比:
总结
论文提出的基于IoU的标签分配训练比检测transformer的普通一对一匹配更有效,论文实证分析了基于任务的训练受益于1) 学习更容易的解码功能,2)从更多pos样本中学习,以及3)不需要通过self-attention进行全局优化。从本文的分析中,展示了与最近的检测transformer方法相比,可以更简单的替代训练机制。这种替代方案在训练效率方面具有显著优势,尤其是在训练时间较短的情况下。作者推断,检测transformer的有效性来自于其transformer编码器和解码器架构。
参考
[1] NMS Strikes Back

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









