






作者 | 小书童 编辑 | 集智书童
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
「首先恭喜YOLOv7登录CVPR2023的顶会列车!!!」
YOLOv7-u6分支的实现是基于Yolov5和Yolov6进行的。并在此基础上开发了Anchor-Free方法。所有安装、数据准备和使用与Yolov5相同,大家可以酌情尝试,如果电费不要钱,那就不要犹豫了!!!
先看原始的YOLOv7的精度
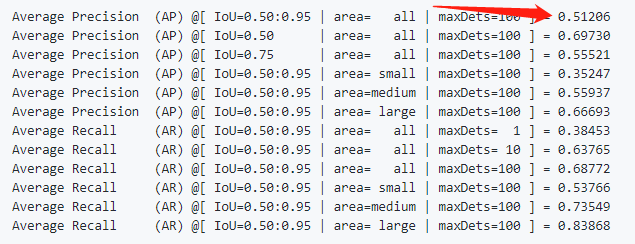
当时原始版本就是无敌的存在,YOLOv7的base版本就有51.2的精度了!!!
再看Anchor-Free版本YOLOv7的精度

再看原作复现的Anchor-Free版本,相对于原始版本的51.2的精度,分别提升了1.1个点和1.4个点(使用了albumentation数据增强),可以看出还是很给力的结构。
架构改进部分
其实,关于复现的YOLOv7-u6(Anchor-Free),Backbone和Neck部分是没有发生变化的,下面看一下Head部分的变化。
1、YOLOv7的Anchor-Base Head
通过下图的YAML知道,YOLOv7的head使用了重参结构,并且也加入了隐藏知识Trick的加入。

2、YOLOv7的Anchor-Free Head
去除了RepConv卷积,使用了最为基本的Conv模块,同时检测头换为了YOLOv6的Head形式,同时加入了IDetect的隐藏知识Implicit层思想。
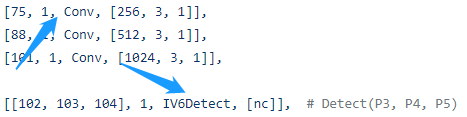
3、IV6Detect的实现如下
class IV6Detect(nn.Module):
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.inplace = inplace # use inplace ops (e.g. slice assignment)
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max(ch[0] // 4, 16), max(ch[0], self.no - 4) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
self.cv3 = nn.ModuleList(
nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
# DFL层
self.dfl = DFL(self.reg_max)
# Implicit层
self.ia2 = nn.ModuleList(ImplicitA(x) for x in ch)
self.ia3 = nn.ModuleList(ImplicitA(x) for x in ch)
self.im2 = nn.ModuleList(ImplicitM(4 * self.reg_max) for _ in ch)
self.im3 = nn.ModuleList(ImplicitM(self.nc) for _ in ch)
def forward(self, x):
shape = x[0].shape # BCHW
for i in range(self.nl):
x[i] = torch.cat((self.im2[i](self.cv2[i](self.ia2[i](x[i]))), self.im3[i](self.cv3[i](self.ia3[i](x[i])))), 1)
box, cls = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2).split((self.reg_max * 4, self.nc), 1)
if self.training:
return x, box, cls
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, (x, box, cls))
def bias_init(self):
m = self # self.model[-1] # Detect() module
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2)关于损失函数与样本匹配的穿搭
一句话吧,其实就是YOLOv8本来的样子,也可能YOLOv8是原来YOLOv7-u6本来的样子。使用了TaskAligned Assigner,BCE Loss、CIOU Loss以及DFL Loss。可以说是标准搭配了!!!
class ComputeLoss:
def __init__(self, model, use_dfl=True):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
# 分类损失
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]], device=device), reduction='none')
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get("label_smoothing", 0.0)) # positive, negative BCE targets
# Focal loss
g = h["fl_gamma"] # focal loss gamma
if g > 0:
BCEcls = FocalLoss(BCEcls, g)
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.BCEcls = BCEcls
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.device = device
# 正负样本匹配
self.assigner = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
# 回归损失函数
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.proj = torch.arange(m.reg_max).float().to(device) # / 120.0
self.use_dfl = use_dfl参考
[1].https://github.com/WongKinYiu/yolov7/tree/u6.

国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 6088
6088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









