






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享多伦多大学&华为诺亚最新的工作AutoSplat!自动驾驶视觉场景重建SOTA,新视角合成能力超越MARS等!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
编辑 | 自动驾驶之心
写在前面&出发点
真实的场景重建和视图合成对于通过模拟安全关键场景来推动自动驾驶系统的发展至关重要。3DGaussian Splatting在实时渲染和静态场景重建方面表现优异,但由于复杂的背景、动态目标和稀疏的视图,它在模拟驾驶场景时遇到了挑战。这里提出了AutoSplat,这是一个采用Gaussian Splatting技术的框架,以实现自动驾驶场景的高度逼真的重建。通过对代表道路和天空区域的高斯函数施加几何约束,方法能够实现对包括车道变更在内的挑战性场景的多视图一致模拟。利用3D模板,引入了一种反射高斯一致性约束,以监督前景目标的可见面和不可见面。此外,为了建模前景目标的动态外观,为每个前景高斯函数估计了残差球谐函数。在Pandaset和KITTI数据集上进行的广泛实验表明,AutoSplat在场景重建和新视图合成方面优于各种驾驶场景下的最先进方法。项目页面位于:https://autosplat.github.io/。
领域背景介绍
从捕获的图像中进行视图合成和场景重建是计算机图形学和计算机视觉中的基本挑战,对自动驾驶和机器人技术至关重要。从移动车辆上的稀疏传感器数据中重建详细的3D场景在高速行驶时尤其具有挑战性,因为此时无论是自动驾驶车辆还是周围物体都处于运动状态。这些技术通过模拟逼真的驾驶场景,特别是成本高昂或危险的极端情况,增强了安全性。
神经辐射场(NeRFs)的出现通过多层感知器(MLP)隐式表示场景,彻底改变了视图合成和重建领域。众多研究致力于解决NeRF面临的挑战,如训练和渲染速度慢,以及渲染质量,特别是在重建有界静态场景方面。同时,也探索了无界场景和大规模城市区域的扩展。各种方法已针对自动驾驶场景中的动态场景建模进行了研究。然而,基于NeRF的方法在训练和渲染包含多个动态目标的大规模场景时仍面临重大障碍。
与基于NeRF的方法相比,3D Gaussian Splatting(3DGS)使用各向异性的3D高斯函数明确表示场景,这使得它能够更快地进行训练,实现高质量的新视图合成,并进行实时光栅化。尽管3DGS在处理纯静态场景方面表现出色,但它无法重建包含动态目标的场景。此外,3DGS并非为重建自动驾驶场景而设计,而在自动驾驶场景中,视图通常是稀疏的。这导致在前景目标重建和新视图合成时出现扭曲,如图1所示的自动驾驶车辆变道场景。

这里提出了AutoSplat,一个专为自动驾驶场景模拟而设计的基于3DGS的框架。为了确保在背景重建过程中新视图的一致性和高质量合成,我们将道路和天空区域与其他背景区分开来。对这些区域的高斯函数施加约束,使其变得平坦,从而保证多视图的一致性。这在变道场景中尤为明显,如图1所示。此外,表示前景目标的3D点无法通过运动结构(SfM)方法捕获,且激光雷达点云稀疏且不完整。因此,我们利用密集的3D模板作为高斯函数初始化的先验,并对这些高斯函数进行微调以重建场景中的前景目标。这使我们能够引入反射高斯一致性约束,该约束通过利用真实相机视图将前景目标所有高斯函数反射到其对称平面上来监督前景目标的不可见部分。最后,为了捕捉前景目标的动态外观,估计了不同时间步长下每个高斯函数的残差球谐函数。总的来说,主要贡献有四个方面:
将背景进行分解,并对道路和天空区域施加几何约束,以实现多视图一致的光栅化;
利用3D模板对前景高斯函数进行初始化,并结合反射高斯一致性约束,通过从对称可见视图中重建不可见部分;
通过估计时间依赖的残差球谐函数来捕捉前景目标的动态视觉特征;
在Pandaset和KITTI数据集上将AutoSplat与最先进(SOTA)方法进行了全面比较;
相关工作
隐式表示与神经渲染:体渲染技术,特别是NeRF,已经在3D重建和新视图合成方面取得了显著进展。然而,NeRF面临着一些挑战,包括训练和渲染速度慢、内存使用率高以及几何估计不准确,特别是在视点稀疏的情况下。为了解决训练速度慢的问题,已经探索了不同的方法,如体素网格、张量分解以及哈希编码。为了改善渲染延迟,FasterNeRF设计了一种受图形启发的分解方法,以紧凑地缓存空间中每个位置的深度辐射图,并使用射线方向有效地查询该图。MobileNeRF和BasedSDF通过将隐式体转换为显式纹理网格来实现快速的渲染速度。为了解决NeRF渲染质量低的问题,Mip-NeRF有效地渲染了抗锯齿的圆锥形截锥体而不是射线。Mip-NeRF 360通过采用非线性场景参数化、在线提炼和基于失真的正则化器,解决了从小型图像集重建大型(无界)场景时固有的模糊性问题。
使用NeRF进行城市场景重建:建模城市级场景具有挑战性,因为需要处理成千上万张具有不同光照条件的图像,每张图像仅捕捉到场景的一小部分,这带来了巨大的计算需求。MegaNeRF和BlockNeRF将场景划分为多个块,并为每个块训练单独的NeRF模型。然而,这些方法并没有对自动驾驶场景中常见的动态目标进行建模。NSG和MARS通过引入场景图来进行动态场景建模。与NSG不同,SUDS解决了在自动驾驶车辆运动过程中的重建问题,利用激光雷达数据来改善深度感知,并利用光流来减轻对目标标注的严格要求。EmerNeRF通过学习驾驶场景的空间时间表示,并通过分层场景和使用诱导流场来提高动态目标的渲染精度。尽管进行了优化努力和采用了创新策略,但基于NeRF的方法仍然计算量大,并且需要密集重叠的视图。此外,模型容量的限制使得在建模具有多个目标的长期动态场景时难以保证准确性,从而导致视觉伪影。
3D Gaussian Splatting(3DGS):3DGS利用了一种显式的场景表示方法。其核心在于优化各向异性的3D高斯函数,这些高斯函数负责场景的忠实重建,同时结合了快速、可见性感知的光栅化算法。这不仅加速了训练过程,还促进了实时光栅化。然而,由于3DGS假设场景是静态的,并且可用的相机视角有限,因此它在重建大规模自动驾驶场景时仍面临相当大的障碍。此外,3DGS中背景区域缺乏几何约束,导致在合成新视图时质量显著下降,如图1所示。最近,PVG在3DGS的基础上,通过使用基于周期性振动的时间动态来模拟自动驾驶场景中的动态场景。然而,该方法并没有解决新场景的模拟问题,例如自动驾驶车辆的车道变换和物体轨迹的调整。相比之下,我们的方法在重建动态场景和模拟多种新场景方面表现出色,包括改变自动驾驶车辆和前景物体的轨迹。
AutoSplat方法介绍
3DGS通过使用从一组3D点初始化的各向异性3D高斯函数来显式地表示一个场景。它被定义为:
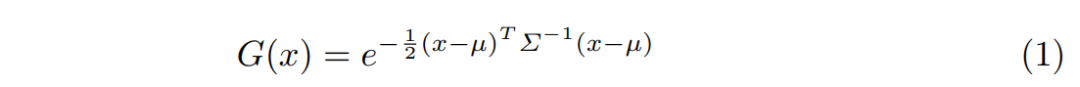
其中,µ 和 分别表示每个3D高斯函数的中心向量和协方差矩阵。此外,在3DGS中,每个高斯函数都被赋予了一个不透明度o和颜色c属性,其中颜色c使用球谐系数来表示。为了优化方便,协方差矩阵Σ被分解为缩放矩阵S和旋转矩阵R:
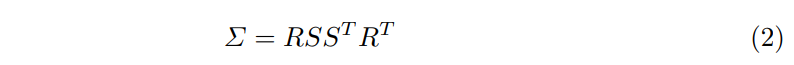
对于可微渲染,3D高斯函数通过近似其在二维空间中的投影位置和协方差,被涂抹到图像平面上。通过根据高斯函数在相机空间中的深度进行排序,查询每个高斯函数的属性,并通过混合N个重叠高斯函数的贡献来计算像素的最终光栅化颜色C,如下所示:
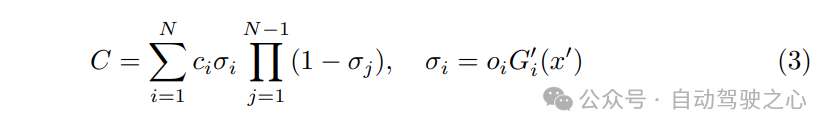
给定按顺序捕获和校准的多传感器数据,其中包括由相机拍摄的N个图像序列(Ii),以及相应的内参(Ki)和外参(Ei)矩阵,还有3D激光雷达点云Li和对应的动态物体轨迹Ti,我们的目标是利用3DGS来重建3D场景,并在任何相机姿态下合成新的视图,同时赋予新的物体轨迹。提出的方法的概述如图2所示。首先从重建一个具有几何感知的静态背景开始。然后,从3D模板中重建前景物体,在建模其动态外观的同时,确保可见区域和不可见区域之间的一致性。最后将前景和背景高斯函数融合,以产生精细且统一的表示。
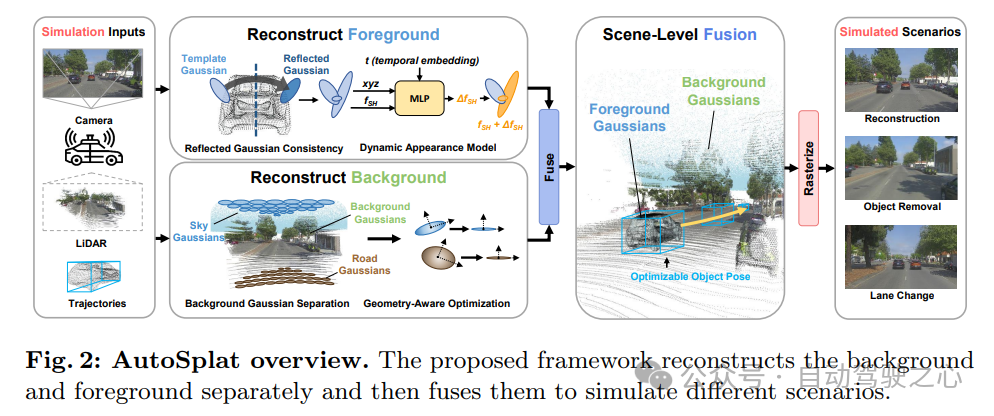
1)Background重建
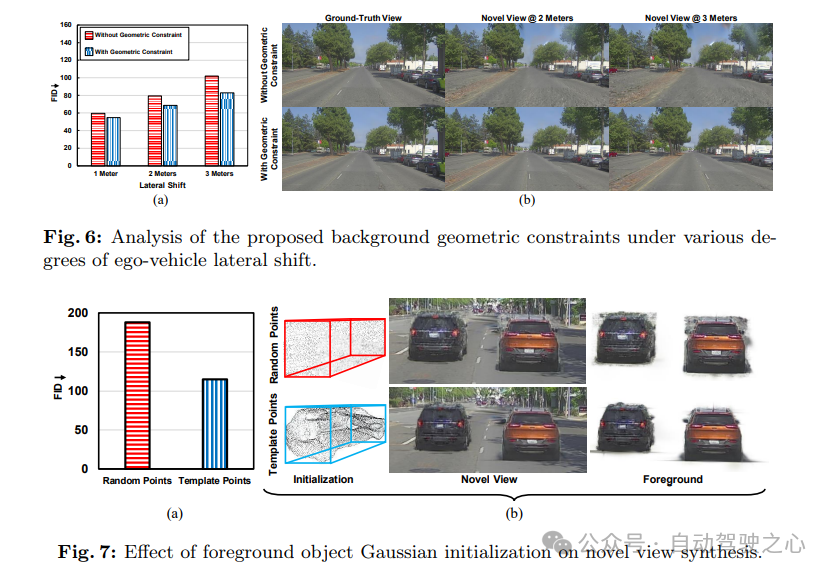
自动驾驶场景既广阔又无边界,而传感器的观测数据则相对稀疏。单纯地使用3DGS从这些有限的观测数据中表示背景,对于实现逼真的重建和模拟是不够的。此外,用于重建道路和天空区域的高斯函数存在几何上的错误,并会产生浮动伪影。虽然这些高斯函数能够根据真实视图重建场景,但由于其几何形状不正确,在模拟新场景(如图1所示的自动驾驶车辆横向移动)时会产生明显的失真。
为了解决这些问题,提出的框架中背景训练分为两个阶段进行。在第一阶段,使用现成的预训练分割模型获得的语义掩码,将道路和天空区域从背景的其他部分中分解出来。通过在校准矩阵的帮助下将每个时间步i的LiDAR点投影到图像平面上,每个高斯函数都被分配到道路、天空或其他类别之一。这种分解有两个目的。首先,这可以防止非天空和非道路的高斯函数重建天空和道路区域。其次,当涂抹天空和道路高斯函数时,可以约束它们产生多视图一致的结果。由于LiDAR点不包括天空点,我们在最大场景高度以上添加了一个代表天空的平面点集。上述区域使用和损失项进行监督。为了确保在涂抹道路和天空高斯函数时跨视图的一致性,这些高斯函数被约束为平坦的。这是通过最小化它们的翻滚角和俯仰角以及垂直尺度来实现的。因此,第一阶段背景训练的整体损失项定义为:
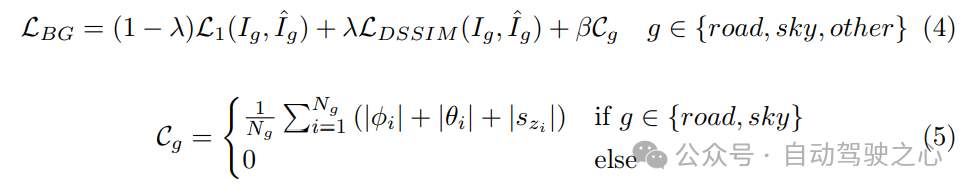
其中,和分别表示区域g的语义掩码真实图像和光栅化图像,g可以是道路、天空或其他。Cg是对道路和天空区域施加的约束,其中ϕi、θi和szi分别表示第i个高斯函数的翻滚角、俯仰角以及垂直尺度(沿Z轴)。此外,β用于加权几何约束。提出的约束保证了无论视点如何变化,道路和天空高斯函数的光栅化都能保持一致。
在背景重建的第二阶段,将所有高斯函数合并在一起,并使用LBG对整个图像进行监督,其中g∈{road ∪ sky ∪ other}。在这一阶段,背景的道路、天空和其他区域被混合以优化最终的背景图像。需要指出的是,在训练的两个阶段中,都屏蔽了动态前景区域。
2)前景重建
尽管自动驾驶场景中存在遮挡和动态外观等挑战,但前景重建对于实现逼真的模拟至关重要。在此,我们介绍了在3DGS范式中解决这些复杂性的新策略。
构建模板高斯函数 3DGS在重建前景目标时面临挑战,因为它依赖于为静态场景量身定制的运动恢复结构(SfM)技术,并且缺乏运动建模能力。为了克服这些限制,我们需要一种替代方法来初始化代表这些前景目标的高斯函数并优化其属性。这可以通过利用随机初始化的点、累积的LiDAR扫描或使用单帧或少量帧的3D重建方法来实现。尽管LiDAR能够捕获详细的几何形状,但它存在盲点,并且对于远距离物体的表面细节捕捉不够。因此,我们使用具有真实车辆几何形状的3D模板来建模前景目标。在提出的方法中,给定包含K个前景目标的帧序列,模板将被复制K次,并根据目标轨迹放置在场景中。每个前景目标的高斯函数都从这个模板初始化,并计算每个轴上的缩放因子以调整模板的大小,以匹配目标目标3D边界框的尺寸。在训练过程中,这些模板相关联的高斯函数会经过迭代优化,以收敛到目标外观。通过利用模板中丰富的几何信息,提出的方法提高了前景重建的真实感和保真度。同时,保留了对模板高斯函数位置的明确控制,使我们能够通过修改前景目标的轨迹来生成新场景。
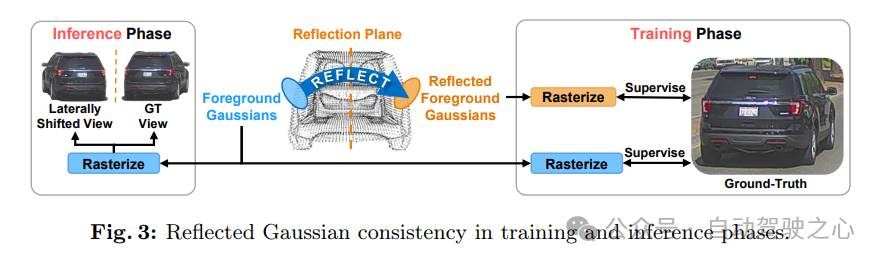
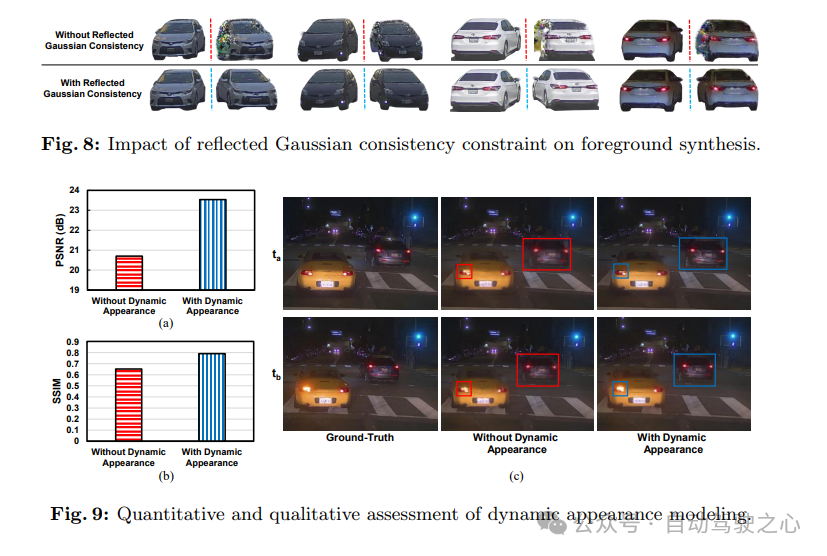
反射高斯一致性:前景目标在其结构上展现出对称性。利用这一假设有助于提高重建质量,特别是在视角受限的场景中。通过在3DGS范式中强制执行前景目标可见面和对称不可见面之间的一致性来拓宽这一假设的应用范围。此过程如图3所示。更具体地说,对于每个前景目标,其高斯函数会在目标的对称平面上进行反射。然后,根据真实视图对反射后的高斯函数进行光栅化和监督。这将为不可见的高斯函数提供监督。高斯函数的反射矩阵M可以定义为:
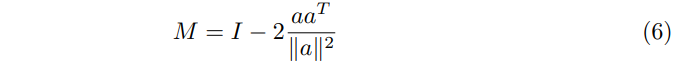
其中,a表示反射轴,I表示单位矩阵。每个高斯函数的位置x、旋转R和球谐特征通过以下方式进行反射:
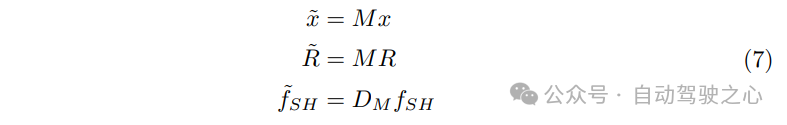
其中,是一个Wigner D-矩阵,用于描述反射,而x̃、R̃、f̃SH分别表示高斯函数的反射位置、旋转和球谐特征。这种反射一致性约束强制要求目标两侧对称面的高斯函数的渲染结果相似。在推理阶段,这使我们的方法能够在其对称视图中光栅化出高质量的前景。
动态外观建模:捕捉前景目标的动态外观对于自动驾驶模拟至关重要。这包括指示灯、前大灯和尾灯等重要信号,它们传达意图并影响驾驶行为。此外,逼真的模拟还需要模拟各种光照条件的变化,如阴影。为了捕捉动态外观,通过为每个高斯函数学习残差球谐特征来学习前景目标外观的4D表示。换句话说,估计的残差特征被用于将动态外观赋予静态表示。在这里使用一个简单的多层感知机(MLP)来模拟动态外观,更具体地说,利用时间嵌入,认识到外观的变化与时间的演变密切相关。在每个时间步,将相应的时间嵌入、高斯位置和球谐特征输入到模型中。然后,将估计的残差特征添加到原始的球谐特征中。因此,前景目标在每个时间步的动态外观通过以下方式建模:
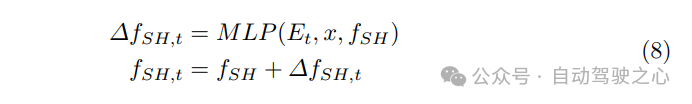
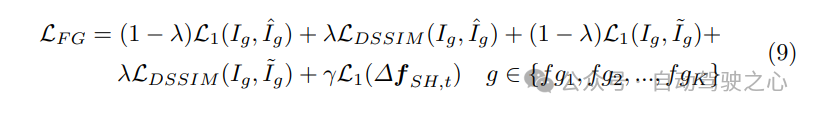
3) Scene-Level Fusion
场景级融合包括将前景和背景高斯函数进行混合。当分别优化时,这两组高斯函数在光栅化到一起时会出现失真,特别是在前景目标边界附近尤为明显。为了解决这些失真问题,将前景和背景高斯函数一起进行微调,并在整个图像上进行监督。这将生成一个融合的前景-背景图像,其中两个组件的失真都得到缓解。此外,为了解决目标轨迹中的噪声问题,我们对每个目标优化了一个变换校正,包括旋转和平移偏移。这些校正被应用于前景目标轨迹,以克服3D边界框中的噪声。最终的损失项计算如下:

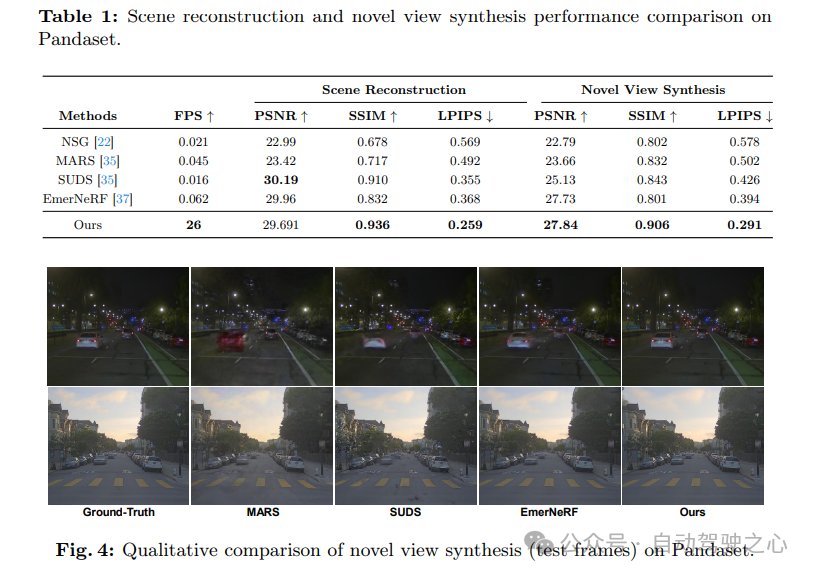
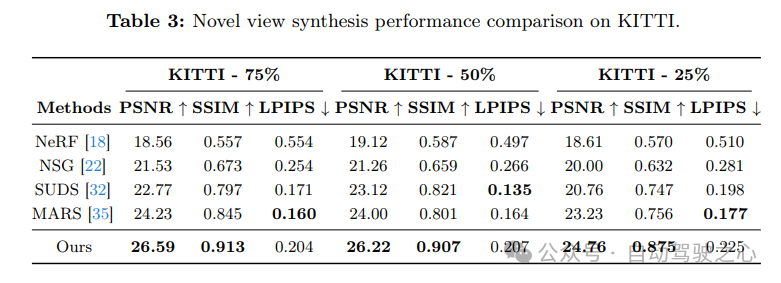
实验对比


参考
[1] AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
重磅自动驾驶之心『三维重建』交流群正式成立了。添加小助理微信AIDriver004加入交流群!

备注:昵称+学校/公司+研究方向
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵















 4004
4004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









