






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天为大家邀请到上海人工智能实验室的青年研究员蔡新雨,为大家分享ICRA 2023中稿的自动驾驶传感器部署策略优化方法!如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【硬件交流】技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
0. 摘要
近年来,车路协同感知越来越受到关注,激光雷达在该研究领域发挥着关键作用。但是,很少研究如何优化车路协同场景中激光雷达的最佳部署位置。在本工作中,我们研究了路端传感器放置问题,并提出了一种可以在仿真环境中高效且有效地找到车路协同场景中激光雷达最佳安装位置的技术路线。
为了更好地模拟和评估激光雷达的位置,我们建立了一个高一致性的激光雷达仿真库,可以模拟多种主流激光雷达的独特特征,并借助仿真引擎生成高保真的激光雷达点云。通过模拟在同一交通场景下,不同部署策略的路端激光雷达所采集到的点云数据,我们可以使用多款检测框架去评估这些方案的感知性能。
通过计算感兴趣区域的密度和均匀性,我们对点云分布与感知精度之间的相关性进行研究,验证了感兴趣区域点云密度和均匀性可以作为感知性能评价的相关性指标。实验表明,在标准车道场景下,使用相同数量和类型的激光雷达时,通过本文方法优化的放置方案比常规放置方案平均精度提高了15%。高一致性的激光雷达仿真库和相关部署策略优化方法的代码都已在下面的链接开源发布:https://github.com/PJLab-ADG/LiDARSimLib-and-Placement-Evaluation。
原文链接:https://arxiv.org/pdf/2211.15975.pdf。
开源链接:https://github.com/PJLab-ADG/LiDARSimLib-and-Placement-Evaluation。
1. 说明
众所周知,对驾驶环境准确的感知能力对于自动驾驶技术来说非常重要。随着深度学习神经网络的最新进展,单车感知算法的鲁棒性在物体检测[1], [2], [3], [4], [5], [6], [7]等多项任务中有了显著提高。但是,由于车辆传感器天然存在的盲区问题,一定程度上限制了自动驾驶感知性能。与单车感知相比,结合使用车端和路端传感器有许多显著的优势,包括提供超广视角,以覆盖单车感知受遮挡所致的盲区。目前V2X通信技术(尤其是5G通信)的进步使得车端、路端传感器[8], [9], [10]的数据实时协同交互成为可能。
近年来,少量的文献从激光雷达布放[11], [12]的角度来考虑激光雷达的感知问题,这是一个新的研究视角,也是至关重要的,因为不论是车端还是路端,激光雷达放置不当可能导致传感数据质量较差,从而从根本上导致感知性能较差。在模型一致的情况下,可能会导致各自的感知精度间有近10%甚至以上的差距。
随着V2X应用的快速发展,路端传感器的部署也越来越普遍。了解如何选择最优的部署策略,使路端传感器带来的效益最大化是非常必要的。但现有的部署方案仅仅通过手动调整激光雷达以让探测范围覆盖感兴趣区域。至于该部署方案是否为感知性能最佳方案,并没有去过多深究。
然而,现有的激光雷达布局研究主要集中在车辆上,而忽略了路端传感器的布局问题。相比于车端激光雷达部署策略来说,路端激光雷达的布置有更高的自由度——沿杆的高度和旋转、俯仰和偏航角度都需要考虑。另外,与车载激光雷达部署问题不同的是,不论是在城市交通路口还是在高速公路匝道口,可选的部署位置更多的是附着于路灯杆、红绿灯杆等杆状物上。路端激光雷达布置优化问题首先需要通过从这么多个潜在位置中选择一定数量的最佳位置来放置路端激光雷达,从而最大化对场景的感知能力。
那么归纳一下,在这个课题中,现有问题包括,不佳的部署策略确实会影响采集到的传感器数据质量,更进一步会影响模型的感知性能。另外,在现实生活中,如何去寻找最优的部署策略,目前还没有比较合适的解决方案。
我们能够直接想到的是,找到最佳安装位置最直接的方法是去逐个评估现实世界中不同激光雷达位置选择的感知性能。然而,这种方法是不可行的,因为它非常费时费力。而且不同安装位置、不同安装角度的组合将让部署方案数量带来指数级的上涨,根本没有办法在现实中实施。此外,因为在公开道路,在评估不同的部署策略时,不可能确保车流量、交通场景完全相同,这将带来不公平的比较。
另一种解决方案是通过高一致性的自动驾驶仿真框架+高一致性传感器仿真模型来复现相同的交通场景,采集每个路端放置方案的仿真点云数据,借助“模型训练-数据仿真-感知性能评估”这一评测管道,评估每个放置方案所对应的感知精度。
目前已经有的一些自动驾驶仿真框架包括Prescan、Carsim、VTD和CARLA等,他们大都能够在场景建模、动力学仿真、天气仿真、交通流仿真等方面做到很好。但由于传感器这个门类,技术路线多样,型号各异,现有的自动驾驶仿真框架可以完成基本的传感器仿真,但很少能够针对不同型号的传感器做到精细化的特性建模与仿真。
例如主流开源仿真框架之一的CARLA[11], [12], [13], [14],在进行数据采集和评估时,对于激光雷达的仿真,仅支持均匀线束的机械旋转式激光雷达(Surround LiDAR)仿真,无法仿真微振镜式(MEMS LiDAR)和转镜式(Risley Prism LiDAR)等其他技术路线。另外,激光雷达的一些物理特性,例如运动畸变和鬼影效应,目前的仿真框架也无法涉及,这样严重限制了仿真数据对现实环境的泛化。
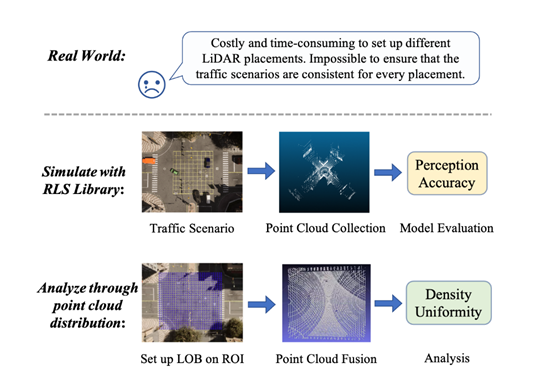
2. 高一致性激光雷达仿真库
为了获得准确和高一致性的激光雷达点云,并促进V2X在现实环境中的应用,我们开发了高一致性激光雷达仿真库(Realistic LiDAR Simulation Library),该库能精确模拟不同激光雷达的物理特性,并可以作为插件安装在CARLA中。我们的RLS Library包含3种类型的14种流行的激光雷达设备。经对多种主流产品的调研和评测,我们在掌握各型号激光雷达物理特性之后,分别根据机械旋转式、微振镜式、转镜式等技术路线,为光束扫描探测过程和运动畸变、鬼影效应等激光雷达物理特性分别建模,建立了激光雷达仿真模型库。另外,其API调用方式便捷,基本与CARLA自带的功能调用方式一致。

除了模拟不同激光雷达的线束特性外,我们的RLS Library还可以模拟不同的激光雷达的运动失真、鬼影效应和噪声与丢弃,这些都或多或少存在于真实的点云数据中。
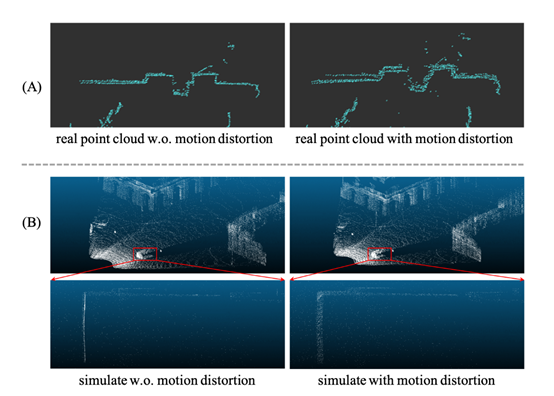
2.1.运动畸变
在真实的交通场景中,交通参与者和激光雷达在激光雷达收集的每个数据帧的周期内都在不断移动。当激光雷达与周围环境的相对位置发生变化时,无论是抖动还是移动,采集到的点云数据都会出现运动畸变。如果运动速度足够快,运动畸变就不容忽视。例如A图中的真实采集的激光雷达点云,墙壁的点云由于激光雷达的运动畸变而变厚。
然而在大多数仿真框架中,考虑到仿真性能,默认的做法是激光雷达每一帧的点云采集只在一个仿真帧中触发。此时周围环境完全静止,获取的是“快照”点云数据,而不是不断采集点云数据。而在我们开发的RLS Library中,我们为激光雷达运动畸变仿真功能设置了一个开关。开启运动畸变状态,将输出如右图所示的点云,车辆的点云由于激光雷达运动畸变而变厚。
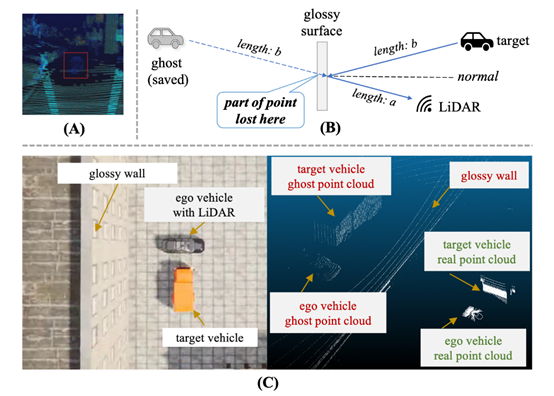
2.2.激光雷达鬼影效应
激光雷达点云鬼影效应是指激光雷达光线投射到高反或者高光滑度表面后发生多次反射回波所造成的在一些其他方位也会形成形状大小类似的成像点云。我们根据深入研究鬼影的成因,对点云鬼影特性进行仿真。
我们发现,激光雷达的鬼影效应有相当一部分基于图B所示的原理造成的。当激光雷达光束照射到具有高光滑度和高反射率的表面时,将触发镜面反射。反射的光将重新击中靠近光泽镜的其他对象。回波光将沿着发射光路返回到激光雷达接收端。然而,大多数激光雷达无法判断出射光是否发生了镜面反射,只会认为该光束在当前光路的直线方向a+b距离处有目标物体,并存储该部分的点云数据。在现实世界中,玻璃、水等都很容易引发鬼影效应。为了提高仿真与真实世界的一致性,有必要对激光雷达的鬼影效应进行仿真。
图C所示的是,使用RLS Library采集到的高反墙壁旁自车与他车场景的点云数据样例图。其中,我们将激光雷达所有光束中触发鬼影的比例设置为50%,即50%击中光面墙的点生成墙的点云,其他点生成鬼影点云。
2.3.激光雷达噪声和丢弃模型仿真
我们知道,受到大气损失等因素干扰,激光雷达在不同天气下的噪声也不同。另外,因激光雷达的探测模块存在阈值限制,当接收回波强度(Echo Energy)低于阈值时,尽管该探测点存在回波,也无法被激光雷达探测到,这就造成了激光雷达的丢弃现象。
根据评测,我们获取了部分激光雷达在部分天气下真实点云损失比例,根据激光雷达探测方程去探究了损失比例与大气因素、波长因素、探测距离、表面反射角度等的影响关系,以映射到不同天气状况的对应点云损失情况;同样根据评测,我们也获取了激光雷达测距真实标准差,并完成测距噪声仿真。
所以借助RLS Library,我们可以获得每个激光雷达位置的真实点云数据,并在多传感器部署策略寻优、3D感知模型训练测试数据集搭建、多传感器标定算法验证等方面完成应用。

3. 车路协同场景激光雷达布置分析
A.利用RLS Library进行仿真评估
利用最新提出的RLS Library,我们能够模拟由不同类型的激光雷达产生的高一致性的点云数据。给定特定的路端激光雷达位置(如将激光雷达设置在双向红绿灯上),评估其感知性能的一个直接方法是模拟交通场景,评估目标检测的精度。为了公平比较,我们对每个路端激光雷达位置使用相同的训练和测试交通场景(相同的场景、相同的汽车、相同的轨迹),并使用相同的Multi-agent感知模型进行评估。3D对象检测的AP越高,表明路端激光雷达放置得越好。
B.使用点云分布进行分析
然而,按照上述提出的技术路线进行部署策略优化时,虽然相较于在真实环境中按照调整测试的方式更加合理和可执行,但是模拟数据采集和评估管道的成本仍然较高,包括激光雷达部署、数据收集、模型训练和性能评估的过程。虽然我们使用相同的交通场景进行实验,但评估仍然依赖于训练和测试交通场景,即训练和测试数据。为了加快路端激光雷达放置的评估速度,避免交通场景的影响,我们深入研究了感知性能和点云分布之间的相关性,设计了两个与交通无关的替代性的评价指标:点云密度和点云分布均匀度。这两个指标帮助我们快速评估激光雷达的布局,以选择更好的布局方案。
首先,我们对感兴趣区域提出了虚拟LOB的概念。LOB也就是LiDAR Occupation Board,翻译过来是激光雷达占用板[33],最初是为了评估车辆上的激光雷达而提出的。LOB是放置在车辆激光雷达周围的几块真实的板,用于评估有效激光雷达点数。在这一思想的启发下,我们创新性的设计了一个有助于解决路端激光雷达部署策略优化问题的虚拟LOB,称为InfraLOB。InfraLOB是根据路口的实际情况,考虑到激光雷达可能的安装位置和路口的车流量,我们划定的一个尽可能大的矩形区域。
为了量化InfraLOB中的点云分布,我们使用点云密度(InfraD)和点云归一化均匀系数(InfraNUC)。InfraD描述了InfraLOB内的点云密度,可以计算为:
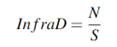
其中N是虚拟LOB内的点数,S是虚拟LOB的面积。
而InfraNUC是归一化均匀度系数(NUC)[34]的变体。NUC是对测试数据集中所有对象上的点集的总体一致性的度量。在我们的问题中,只有一个目标,即虚拟LOB。首先,根据感兴趣区域的大小,计算虚拟LOB的面积。然后,在该区域内,利用激光雷达的语义信息获取目标路面的标签,过滤出虚拟LOB中路面对应的点云数据。然后,我们在虚拟LOB区域中随机选择一定数量的大小相同的圆盘。遍历所有圆盘并计算每个圆盘中的点云数量及其平均值。然后计算圆盘上点数的标准差,作为归一化均匀度系数。InfraNUC可计算为:
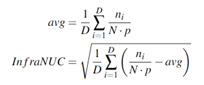
其中,ni为磁盘区域内的点数,N为InfraLOB区域内的点数,D为磁盘数量,p为磁盘面积与InfraLOB区域的比例。Avg是所有磁盘中点云数量的平均值。InfraNUC中为归一化均匀性系数,用于量化InfraLOB区域内点云分布均匀性。
4. 实验
在这里,我们在测试集中展示了三个常见的交通场景,作为评估车路协同场景下激光雷达布局的示例。

A.实验设置
我们在实验中使用了真实的自动驾驶模拟器CARLA[14]。由于需要在所有其他环境因素固定的情况下公平评估不同的激光雷达布局,我们使用CARLA来模拟在相同交通场景下,但具有不同路端激光雷达部署策略的现实场景。我们基于OPV2V[23]数据集的模拟场景,构建了训练和测试数据集。特别地,我们利用OPV2V场景中定义的车辆轨迹,并在CARLA模拟器中使用所提出的RLS Library收集点云数据。在本次实验中,我们使用RLS Library中的64通道Hesai Pandar64激光雷达,在CARLA中采集频率为10Hz的点云数据。
我们利用Multi-agent感知模型进行评估,包括中间融合、后融合(收集来自智能体的所有检测输出并应用非最大抑制来产生最终结果)和前融合(直接聚合来自附近传感器的原始激光雷达点云)分别进行了实验。对于中间融合策略,我们使用四种最先进的方法进行评估,包括OPV2V[23],F-Cooper[35],V2VNet[22]和V2X-ViT[8]。所有的模型都使用PointPillar[1]作为backbone。我们使用基准模型来评估在激光雷达不同位置收集的点云数据,并以mAP作为最终感知性能的评价指标。
B.车路协同场景下激光雷达布置实验
然后,我们依据上述的实验结果,也就是不同部署策略所对应的mAP,继续进行了分析。我们尝试在不同的路端激光雷达部署策略下,研究感兴趣区域的感知精度与点云分布之间的关系。为了计算不同激光雷达位置的InfraNUC和InfraD,我们去掉场景中的交通流,采集对应虚拟LOB区域内的点云数据。然后对InfraLOB区域内的点云数据和对象进行分割,计算每个测试场景下的InfraLOB的InfraD和InfraNUC。
在下图中,场景A是城市道路的丁字路口。我们在T字结点分别放置一个、两个和三个激光雷达,以分析激光雷达的数量如何影响感知精度。可以观察到,更多的激光雷达带来更高的InfraD,这也导致了整体性能的增益。场景B是城市道路的交叉路口。我们首先将2个激光雷达放置在不同的位置,虽然这两个位置在InfraLOB中有相同数量的激光雷达和类似的InfraD,但在对角线上放置两个激光雷达具有更好的均匀性,也就是更高的InfraNUC,从而导致更好的性能。我们还增加了两个传感器,增加了InfraD,但对InfraNUC只有一点点贡献。最终的实验结果显示相对于前一种方案只能略微提高精度,这表明了点云均匀性的重要性,特别是在点云密度已经足够大的情况下。场景C为城市道路的双向四车道。我们在道路两侧的同一位置放置了四个激光雷达,但设置了不同的俯仰和偏航角度,以分析旋转角度如何影响精度。我们观察到设置适当的旋转角度可以获得更好的性能,而过多的向下倾斜会导致点云分布不均匀,损害感知性能。通过上述实验,我们发现InfraD和InfraNUC可以作为感知精度的指标。
并且得出结论,更优的部署策略应该产生具有兼顾高密度和良好均匀性的点云数据。
5. 总结
我们的贡献总结如下:
据我们所知,我们是第一个研究车路协同场景下激光雷达部署策略问题的团队。我们提出了一个仿真库和工具包来评估不同的路端激光雷达布局,这有助于其在现实环境中的应用。
我们提出了高一致性的激光雷达仿真库(RLS Library),可以模拟14种流行的激光雷达设备的独特特征,包括激光雷达光束、运动失真和鬼影效应。使用RLS Library,我们可以在更加真实的仿真环境中评估不同的部署方案。
我们评估了多个激光雷达的布置,并调查了感知精度和点云数据分布之间的关系。通过我们的观察,点云数据的密度和均匀性可以帮助预测感知的准确性,这有助于我们进行部署方案的快速评估。
关于后续工作:
我们之前做的更倾向于是车流无关的,默认车流是均匀通过整个感兴趣区域(路口等),但这个假设不太符合实际情况。例如高速上下匝道口,显然车流的分布是有疏密之分的。考虑通过整个场景点云Density Map去预测Score Map,进而以Density Map为metrics来优化基于车流信息的车路协同场景激光雷达部署方案。这部分的工作也已经投稿到了今年的ICCV23,可以敬请期待。
6. 参考文献(部分)
[1] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, "Pointpillars: Fast encoders for object detection from point clouds," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705.
[2] M. Simon, S. Milz, K. Amende, and H. M. Gross, "Complexyolo: Real-time 3d object detection on point clouds," arXiv preprint arXiv.1803.06199, 2018.
[3] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner, "Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks," in 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017.
[4] W. Ali, S. Abdelkarim, M. Zahran, M. Zidan, and A. E. Sallab, "Yolo3d: End-to-end real-time 3d oriented object bounding box detection from lidar point cloud," in ECCV 2018: "3D Reconstruction meets Semantics" workshop, 2018.
[5] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, "Pointnet: Deep learning on point sets for 3d classification and segmentation," in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)

国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









