



作者 | 小书童 编辑 | 自动驾驶之心
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【3D目标检测】技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!

由于缺乏准确的3D信息,单目3D检测是一项具有挑战性的任务。现有的方法通常依赖于几何约束和密集的深度估计来促进学习,但往往无法充分利用Frustum和3D空间中的3D特征提取的好处。
在本文中提出了一种用于单目3D检测的学习「Occupancy」的方法OccupancyM3D。它直接学习Frustum和3D空间中的Occupancy,从而产生更具鉴别力和信息量的3D特征和表示。
具体来说,通过使用同步的原始稀疏激光雷达点云,定义了空间状态并生成了基于Voxel的Occupancy标签。将Occupancy预测公式化为一个简单的分类问题,并设计相关的Occupancy损失。使用所得到的Occupancy估计来增强原始Frustum/3D特征。
因此,在KITTI和Waymo开放数据集上的实验表明,所提出的方法达到了新的技术水平,并显著优于其他方法。
代码: https://github.com/SPengLiang/OccupancyM3D
1、简介
3D目标检测是许多现实应用中的一项关键任务,如自动驾驶和机器人导航。早期的方法[47,76,52]通常依赖于激光雷达传感器,因为它们可以产生稀疏但准确的3D点测量。相比之下,相机提供了密集的纹理特征,但缺乏3D信息。最近,用于3D检测的基于单目的方法[38,50,35,46],也称为单目3D检测,由于其成本效益和便于部署的特性,受到了工业界和学术界的极大关注。
从单个RGB图像中恢复准确的3D信息是一个挑战。尽管先前的研究采用了几何约束[42,25,6,35]和密集深度估计[64,36,50]来促进3D推理,但它们往往忽视了3D空间中判别性和信息性3D特征的重要性,这对于有效的3D检测至关重要。他们主要关注改善2D空间中的特征,很少关注在Frustum和3D空间中更好的特征编码和表示。
为了实现这一目标,在本文中建议学习Frustum和3D空间中的 Occupancy,以获得更具鉴别力和信息量的3D特征/表示,用于单目3D检测。具体而言,在训练阶段,使用同步的原始稀疏激光雷达点云在Frustum和3D空间中生成基于Voxel的Occupancy标签。
关于激光雷达点的稀疏性,作者定义了3种Occupancy状态:空闲、Occupancy和未知。基于此对3D空间进行Voxel化,并在每个激光雷达点上使用光线跟踪来获得Occupancy标签。有了Occupancy标签,可以对中间3D特征进行明确的3D监督。它允许网络学习当前3D空间的Voxel化Occupancy,这增强了原始3D特征。该过程也在Frustum空间中执行,由于相机图像的透视特性,使得能够以更细粒度的方式提取近距离物体的3D特征。
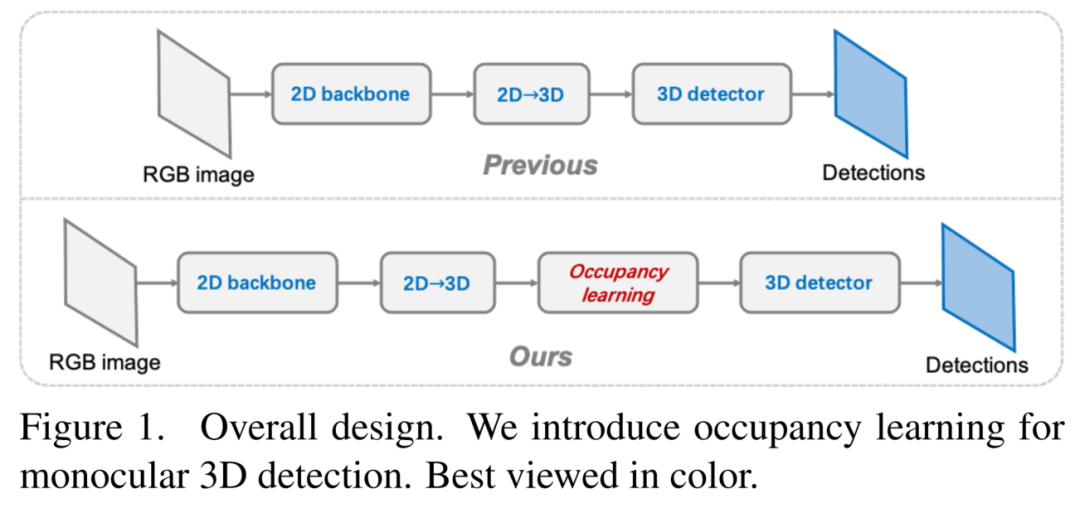
总体而言,将所提出的Occupancy学习方法称为「OccupancyM3D」,并在图1中说明了框架概述。
为了证明OccupancyM3D方法的有效性,作者在竞争性的KITTI和Waymo开放数据集上进行了实验。因此,与其他方法相比,所提出的方法以显著的优势获得了最先进的结果。
本文贡献总结如下:
强调了在Frustum和3D空间中进行特征编码和表示对于单目3D检测的重要性,并建议学习这两个空间中的Occupancy情况。
提出了一种使用同步原始稀疏激光雷达点生成Occupancy标签的方法,并引入相应的Occupancy损失,使网络能够学习Frustum和3D空间中的Voxel化Occupancy。这种Occupancy学习过程有助于提取网络中的判别性和信息性3D特征。
实验证明了所提出方法的优越性。在具有挑战性的KITTI和Waymo开放数据集上进行评估,OccupancyM3D方法获得了新的最先进(SOTA)结果,并显著优于其他方法。
2、相关工作
2.1、基于激光雷达的3D目标检测
基于激光雷达的方法[65,55,24,69,18,74,66]由于其精确的深度测量,目前在3D目标检测精度方面占据主导地位。由于点云的无序性,需要基于激光雷达的方法来组织输入数据。
基于输入数据表示有4种主流:
Point-Based方法
Voxel-Based方法
基于距离视图的方法
基于混合的方法
PointNet族[48,49]是从原始点云中提取特征的有效方法,允许基于点的方法[47,54,56,68]直接执行3D检测。基于Voxel的方法[76,67,70,74,13]将点云组织成Voxel网格,使其与常规卷积神经网络兼容。基于距离视图的方法[1,15,4]将点云转换为距离视图,以适应激光雷达扫描模式。基于混合的方法[53,69,7,43]使用不同表示的组合来利用其各自的优势。单目和基于激光雷达的方法之间仍然存在显著的性能差距,这鼓励研究人员推进单目3D检测。
2.2、单目3D目标检测
近年来,在推进单目3D检测方面取得了重大进展。从单个图像中恢复实例级3D信息的不适定问题具有挑战性和重要性,吸引了许多研究。这也是单目3D检测中的核心子问题。
早期的工作[8,42]采用场景先验和几何投影来解决目标的3D位置。最近的单目方法[2,39,25,34,73,27,29]采用了更多的几何约束和额外的先验,如CAD模型来实现这一目标。AutoShape通过学习区分的2D和3D关键点,将感知形状的2D/3D约束纳入3D检测框架。MonoJSG将实例深度估计重新表述为一个渐进细化问题,并提出了一个语义和几何联合成本量来对深度误差进行建模。由于RGB图像缺乏明确的深度信息,许多工作依赖于密集的深度估计。
一些方法[64,37,36]直接将深度图转换为伪激光雷达或3D坐标补丁,一些工作[50]使用深度分布将2D图像特征提升到3D空间。因此,先前设计良好的LiDAR 3D检测器可以很容易地用于这种明确的3D特征。
其他研究[14,61,44,12,11,46]也利用深度图或激光雷达点云作为特征提取和辅助信息的指导。虽然之前的工作利用了几何约束和密集深度估计,但它们还没有完全探索Frustum和3D空间中的特征编码和表示。为了解决这一问题,作者提出的方法侧重于单目3D检测的学习Occupancy。
2.3、3D场景表示
最近的研究[40,41,72]迅速推进了隐式表征。隐式表示在对3D场景建模时具有任意分辨率的优点。这种性质对于诸如3D重建和语义分割之类的细粒度任务是有益的。
与他们不同的是,单目3D检测是一项实例级任务,作者探索了使用固定大小Voxel的显式Occupancy学习。这项任务的隐式Occupancy表示可以在未来的工作中进行探索,这是一个有趣且有前途的话题。
此外,最近提出了许多基于鸟瞰图(BEV)的作品[51,50,19,32,28,26]。这些工作通常采用BEV表示,并取得了巨大的成功,尤其是在多摄像机BEV检测方面。与本文最相关的工作是CaDDN。除了提出的Occupancy学习模块外,遵循其架构设计,并用轻量级DLA34取代其2D Backbone。需要注意的是,本文的工作侧重于单目设置,将该方法扩展到多摄像头设置是未来研究的潜在途径。
3、OccupancyM3D
3.1、初步和概述
1、任务定义
首先介绍了这项任务的初步内容和方法。在推理中,单目3D检测只获取单个RGB图像,并输出当前场景中感兴趣的3D边界框。在训练阶段,本文的方法需要RGB图像、在激光雷达点上注释的3D框标签和同步的激光雷达数据。值得注意的是,该系统已经校准,并且可以获得相机和激光雷达之间的相机内参和外参信息。
2、网络概述
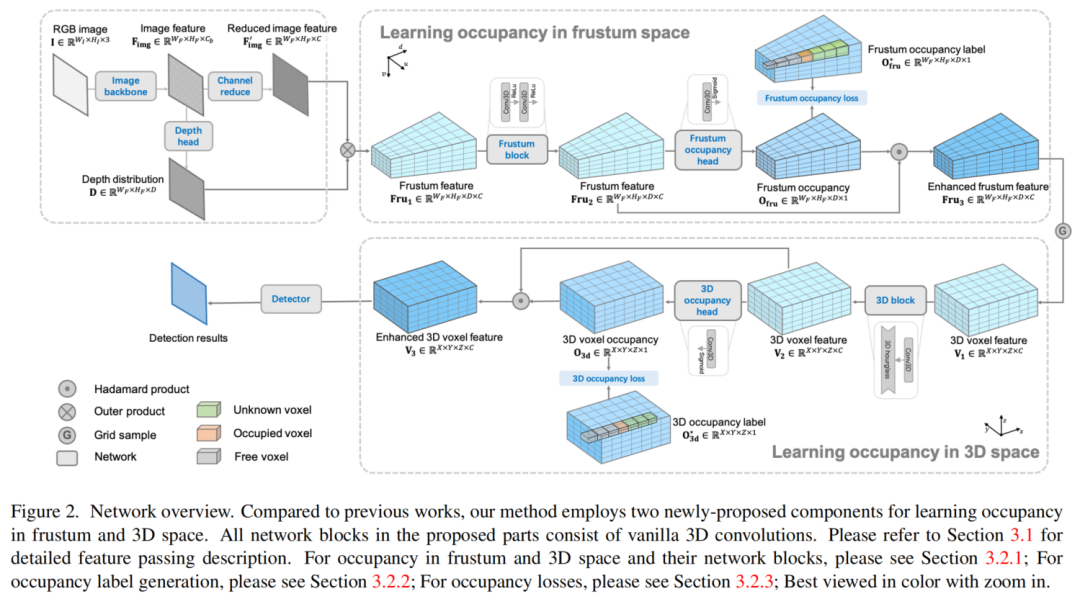
在图2中展示了本文的方法的网络概述。首先,将单个RGB图像输入DLA34 Backbone网络以提取特征。然后,使用这些特征来产生分类深度分布,这将2D特征提升到Frustum空间。之后,使用深度预测和 Backbone特征来生成Frustum特征。它们用于学习Frustum空间中的 Occupancy,然后使用网格采样将其转换为Voxel化的3D特征。这种Voxel化的3D特征被用于研究3D空间中的Occupancy。在Frustum和3D空间中的Occupancy学习可以产生合理的Occupancy估计,从而增强原始特征。最终增强的Voxel化3D特征被传递到检测模块以获得最终的3D检测结果。
在训练阶段,使用所提出的Occupancy损失,分别通过在Frustum和3D空间中生成的Occupancy标签来监督Occupancy估计。我们将在以下章节中详细介绍入住率学习。
3.2、Occupancy Learning
如果Frustum或规则3D Voxel包含目标的一部分,则认为它被Occupancy。将得到的Voxel状态分别表示为Frustum occupancy和3D occupancy。
在本节中,将介绍用于单目3D检测的occupancy learning。它被组织为4个部分:occupancy in frustum/3D space、occupancy labels、occupancy losses以及occupancy and depth。
1、Occupancy in Frustum Space and 3D Space
在提取 Backbone特征后,使用深度头来获得密集的类别深度。为了节省GPU内存,使用卷积层来减少特征通道的数量,并在深度估计的帮助下将得到的特征提升为Frustum特征。然后提取Frustum特征如下:
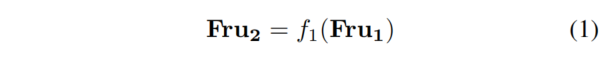
其中表示后面跟着ReLU激活函数的2个3D卷积。然后,使用3D卷积层和Sigmoid函数来获得Frustum Occupancy ,如第3.2.2节和第3.2.3节所述,这由相应的标签监督。
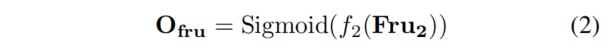
Frustum Occupancy表示Frustum空间中的特征密度,因此可以固有地用于对原始Frustum特征进行加权,以实现增强的Frustum特性,如下所示:
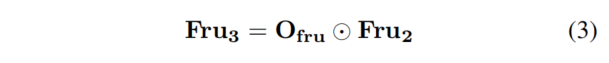
其中表示乘积(按元素相乘)。通过网格采样,将得到的Frustum特征转换为规则Voxel化特征。然后在规则的3D空间中重复Occupancy学习过程。
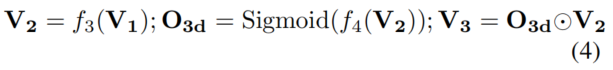
为了更好地在规则的3D空间中对3D特征进行编码,在中使用了类似3D沙漏的设计,是3D卷积。最后,为检测模块提供了更多信息的3D Voxel特征。
在Frustum和3D空间中学习Occupancy的基本原理是什么?
在Frustum和3D空间中的Occupancy学习是有益的,因为它们具有不同的性质。Frustum空间的分辨率取决于相机内参和 Backbone网络的下采样因子,而Voxel化3D空间的分辨率由预定义的Voxel大小和检测范围决定。
FrustumVoxel是不规则的,并且大小根据到相机的距离而变化,这导致较近的物体产生细粒度Voxel,而较远的物体产生粗粒度Voxel。相反,规则的3D Voxel在整个3D空间中具有相同的大小。另一方面,Frustum空间更适合相机图像,但平Frustum内的目标无法精确地表示真实的3D几何体。因此,特征提取和在Frustum空间中的Occupancy对于目标/场景具有失真。因此,在Frustum和3D空间中的Occupancy学习是互补的,可以产生更多信息的表示和特征。
2、Occupancy Labels
给定一组稀疏激光雷达点,其中是点的数量,3是坐标维度,生成相应的Occupancy标签。
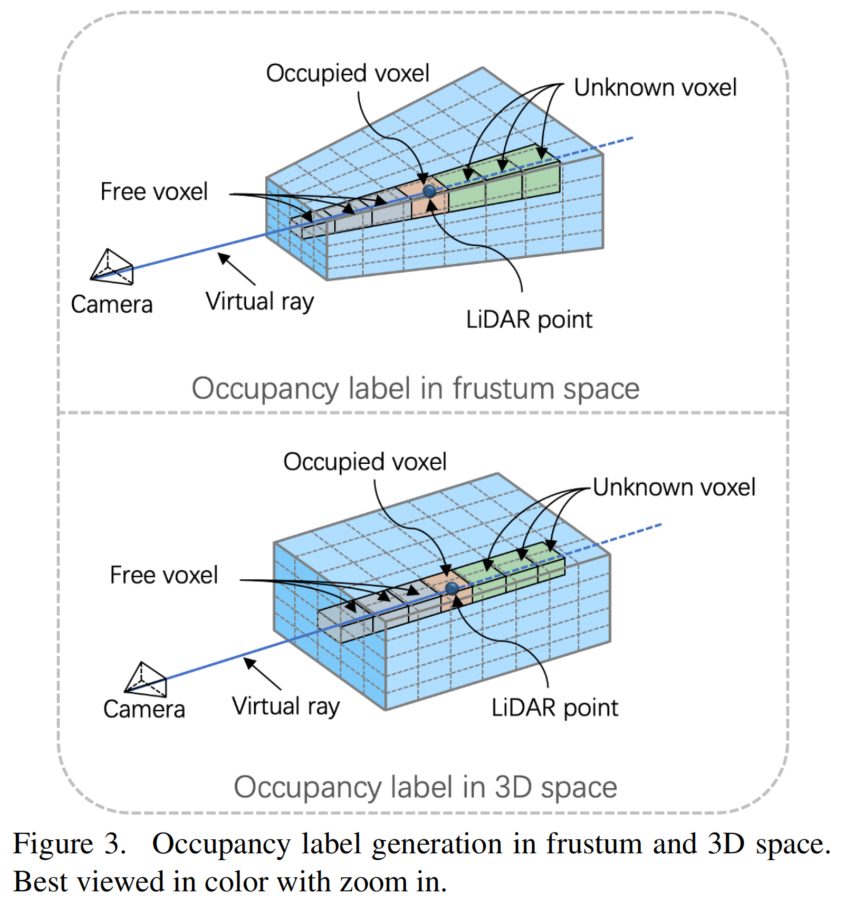
该过程如图3所示,并在每个激光雷达点上进行操作。更正式地说,首先定义了3个空间状态,并用数字表示它们:,,。然后,分别描述了在Frustum和3D空间中的Occupancy标签生成过程。
2.1、Occupancy label in frustum space
将Frustum Occupancy标签表示为*,其中和是特征分辨率,是深度类别。首先将激光雷达点投影到图像平面上,以形成类别深度索引图。每个有效投影点都有一个类别深度索引,而无效点(无激光雷达点投影)的负索引为−1。然后对该索引图进行下采样以拟合特征分辨率,得到。得益于相机的投影性质,可以很容易地区分空间状态,如下所示:
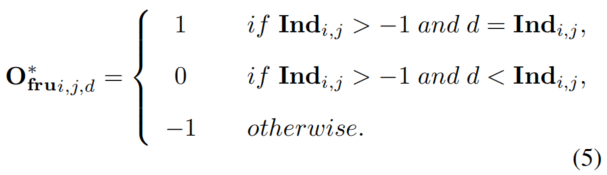
其中。
注意,在Occupancy标签和Occupancy损失中都不考虑未知Voxel。使用已知的Voxel,即自由Voxel和Occupancy Voxel,来执行Occupancy学习。
2.2、Occupancy label in 3D space
将*表示为3D Occupancy标签,其中、、由预定义的Voxel大小和检测范围确定。对网格内的LiDAR点进行Voxel化,并将包含点的Voxel设置为1,将不包含点的设置为−1。通过这种方式,可以容易地实现被Occupancy的Voxel。
为了获得 Free Voxel,作者利用从每个激光雷达点到相机的光线跟踪,其中相交的Voxel被设置为Free ,由0填充。将3D空间中的Occupancy标签总结如下:
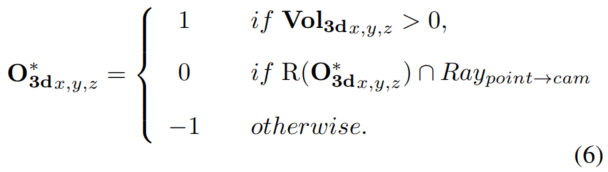
其中。在该方程中,表示Voxel化网格。当它被激光雷达点占据时,>。表示Voxel范围,表示索引处的Voxel与从激光雷达点到相机的光线相交。通过这种方式,生成3D Occupancy标签。
当生成基于Voxel的Occupancy标签时,由于离散化过程而出现量化误差。较小的Voxel大小导致较低的量化误差,从而提供更细粒度和准确的信息。然而,它需要更多的计算和GPU内存资源。
3、Occupancy Losses
使用生成的Occupancy率标签和来分别监督预测的Occupancy率和。将Occupancy预测视为一个简单的分类问题,并使用Focal Loss作为分类损失。只有有效的Voxel,即free Voxel和Occupancy Voxel,会有Loss,而未知Voxel会被忽略。
首先得到有效掩码和。如果,,否则。是使用类似的方式获得的。
因此,Frustum空间中的Occupancy损失为:

其中是指Focal Loss。类似地,可以获得3D Occupancy损失,如下所示:
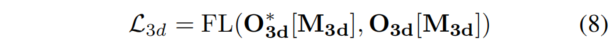
最终入住损失为其总和:
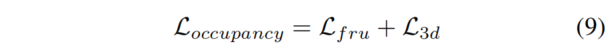
Occupancy损失允许网络学习信息性和判别性特征和表示,从而有利于下游任务。因此,网络的最终损失是:
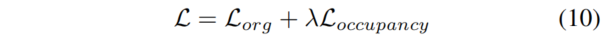
其中表示CaDDN中的原始检测和深度损失,λ是Occupancy损失加权因子,默认设置为1。
4、Occupancy and Depth
Occupancy与2D深度图有一些相似之处,尤其是Frustum Occupancy。它们都可以表示空间中的目标几何体曲面。然而,深度图是二维的,而Occupancy是3D的。Occupancy是超越深度的,可以以此为基础。它能够表达物体的密集特征,而不仅仅是表面。
对于由于遮挡而导致的未知空间,Occupancy可以推理出合理的结果。此外,与2D空间相比,在Frustum和3D空间中的学习Occupancy允许网络在更高维度下研究更多信息特征。
Occupancy和深度不是相互排斥的表示。事实上,它们在3D目标检测任务中是相辅相成的。如果没有深度,网络必须处理很大的搜索空间,这使得学习合理的Occupancy特征具有挑战性。结合深度估计为网络提供了一个良好的起点,并有助于学习Occupancy特征。因此,建议利用深度和Occupancy信息来实现单目3D检测的更好表示和特征。
4、实验
4.1、 Results on KITTI and Waymo Datasets
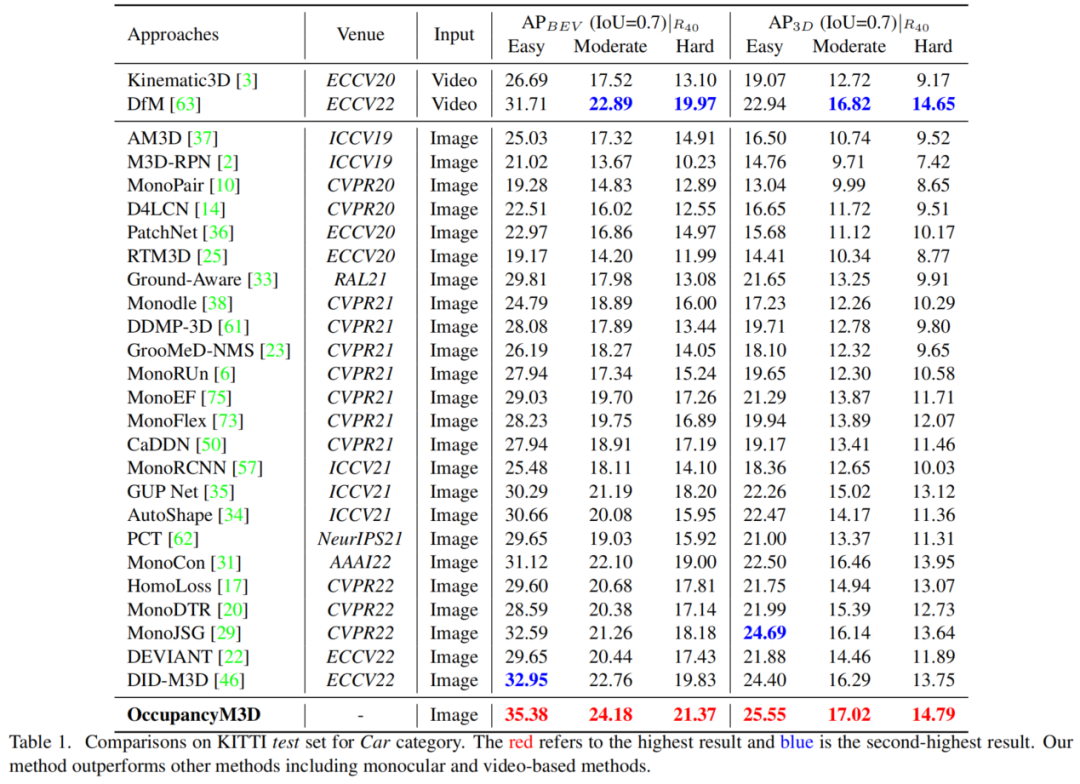
作者提供了KITTI和WaymoOD的性能比较。表1显示了Car类别在KITTI测试集上的结果。本文的方法在很大程度上优于其他方法,包括基于视频的方法。例如,所提出的方法在所有度量下都超过了CaDDN,例如,25.55/17.02/14.79与19.17/13.41/11.46 AP3D。
本文的方法以2.43/1.42/1.54 APBEV的优势优于DID-M3D。与最近的基于视频的方法DfM相比,OccupancyM3D也显示出更好的性能,例如,在中等配置下,24.18比22.89 。
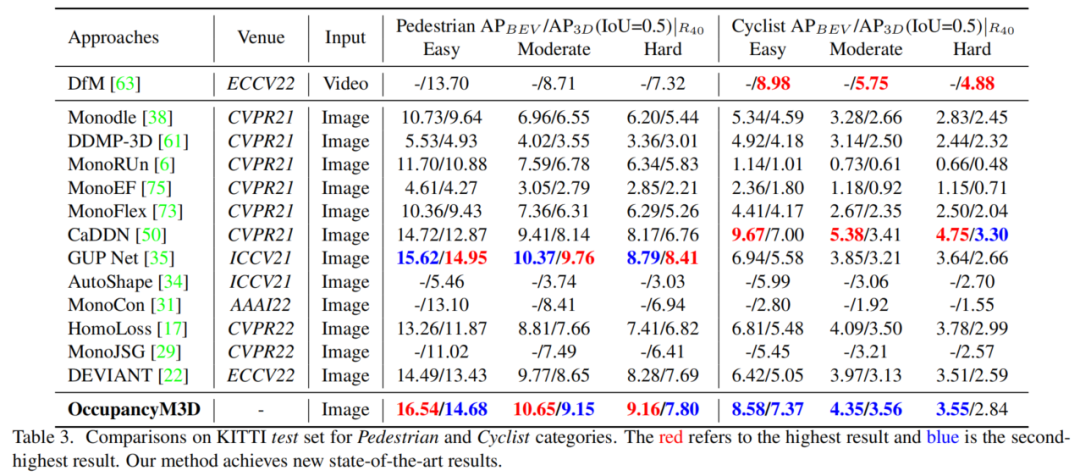
在表3中提供了其他类别的比较,即行人和骑自行车的人。结果证明了本文的方法在不同类别上的优越性。总之,本文的方法在用于单目3D检测的KITTI测试集上获得了最新的结果。
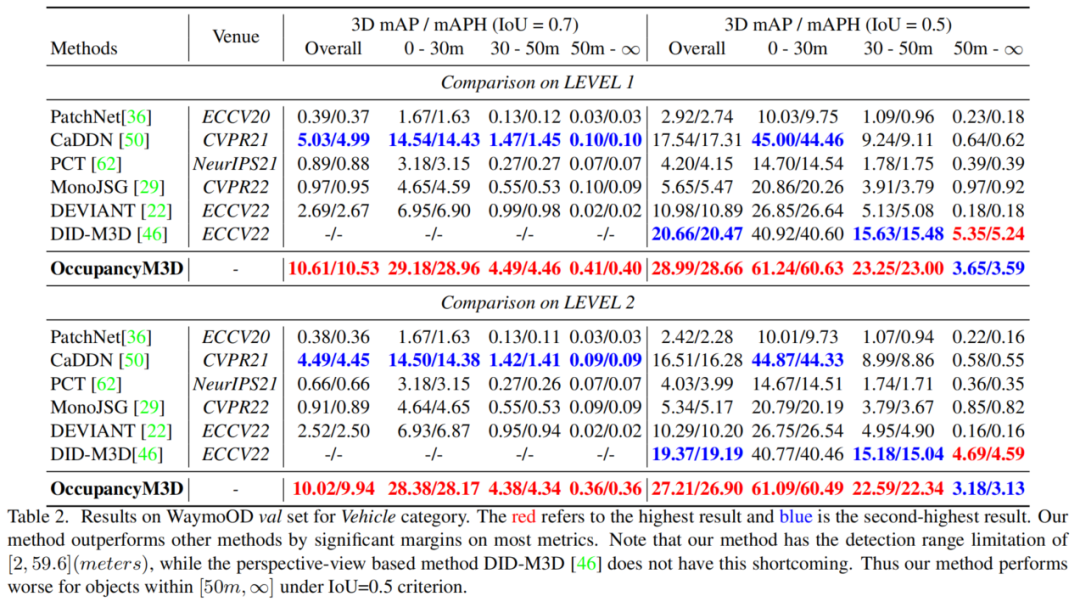
作者还在Waymo开放数据集(WaymoOD)上评估了本文的方法,并获得了有希望的结果。如表2所示,本文的方法以显著的优势超过了其他方法。例如,在LEVEL 1设置下,OccupancyM3D在IoU 0.7和0.5标准下分别优于CaDDN 5.58/5.54 mAP/mAPH(10.61/10.53对5.03/4.99)和11.55/1.35 mAP/mAPH(28.99/28.66对17.54/17.31)。
与DID-M3D相比,在IoU标准0.5下,本文的方法在LEVEL 1和LEVEL 2设置下分别优于它8.33/8.19 mAP/mAPH(28.99/28.66 vs.20.66/20.47)和7.84/7.71 mAP/mAPH(27.21/2690 vs.19.37/119.19)。
这一成功可以归因于这样一个事实,即Occupancy学习受益于大型数据集中存在的不同场景。换句话说,大型数据集尤其支持所提出的Occupancy学习方法。有趣的是,对于[50m,∞]范围内的目标,本文的方法的性能比DID-M3D差。这是因为本文的方法是基于Voxel的,这具有检测范围限制(在本文的方法中为[259.6](米))。相比之下,DID-M3D是一种基于透视的方法,这表明它没有这个限制,可以检测到更远的物体。
4.2、消融实验
按照以前工作中的常见做法,对KITTI val-set进行消融,以验证每个组件的有效性。比较了IoU标准0.7下car类别的性能。
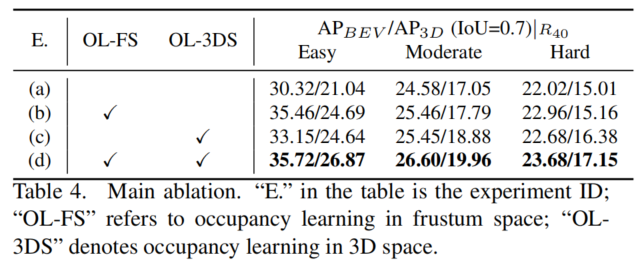
在表4中提供了主要消融。可以很容易地看出,Occupancy学习显著有利于最终检测性能。当在Frustum空间中执行Occupancy学习时,检测从21.04/17.05/15.01增加到24.69/17.79/15.16(实验(a)→(b) )。
另一方面,当在3D空间中执行Occupancy学习时,检测被提升到24.64/18.88/16.38(实验(c))。最后,该模型获得5.83/2.91/2.14 增益(实验(a)→(d) ),通过在Frustum和3D空间中采用Occupancy学习。这种主要消融证明了方法的有效性。
4.3、定性结果

在图4中给出了Occupancy预测和3D检测的定性结果。本文的方法可以预测当前场景的合理Occupancy,尤其是前景目标。这表明了Occupancy学习在下游任务中的潜力。然而,可以看到,对于严重遮挡的物体(见下图右侧物体),Occupancy率估计不是很准确,这为未来的工作留下了改进的空间。
5、局限性与未来
这项工作的一个显著缺点是Voxel大小的限制。基于显式Voxel的表示中的大Voxel可以减少计算开销和GPU内存,但代价是由于量化误差而无法精确描述场景的3D几何结构。相反,较小的Voxel大小能够表达细粒度的3D几何体,但这是以增加计算开销和GPU内存使用为显著代价的。
另一方面,基于Voxel的方法具有有限的检测范围。这项工作主要集中在单目3D检测任务中的Occupancy学习,而其在多摄像头检测和分割等下游任务中的应用探索较少。作者认为这是一个有趣且有前景的话题,并鼓励未来的工作来缓解上述限制,以推进自动驾驶社区。
6、参考
[1].Learning Occupancy for Monocular 3D Object Detection.
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、多传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









