






作者 | 科技猛兽 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
本文只做学术分享,如有侵权,联系删文
导读
本文提出了一个即插即用的模块-重新参数化重新聚焦卷积(RefConv),作为常规卷积层的替代品,该方法可以在没有任何推理成本的情况下提高性能。
本文目录
1 RefConv:一种基于重参数化操作的重聚焦卷积方法
(来自南京大学,腾讯 AI Lab,RepVGG 作者团队)
1 RefConv 论文解读
1.1 背景:增加现有卷积架构的先验
1.2 DW Conv 的重参数化重聚焦技术
1.3 广义的重参数化重聚焦技术
1.4 计算复杂度分析
1.5 重参数化重聚焦训练
1.6 实验结果
1.7 消融实验结果
1.9 重参数化重聚焦训练平滑了 Loss Landscape
太长不看版
一个卷积层,如何才能在不增加任何推理成本的前提下,以一种近乎 Free-Lunch 的方式提升整个模型的性能?
本文提出一种名为重参数化重聚焦卷积 (Re-parameterized Refocusing Convolution) 的技术,该方法的思想基于结构重参数化的方法,即:在训练时为模型融入更多的可学习参数并且训练它们以获得更优的性能。在推理时把这些参数合并入原始模型的参数,以达到不引入额外的推理成本的目的。
具体到这种方法,RefConv 技术为每个卷积额外配了一个重聚焦变换操作 (新的可学习参数),并且在训练时只训练这些重聚焦变换操作的权重,并在推理时把它们和原始权重混合,不增加额外的参数。作者在分类,检测和分割任务上面验证了这种方法的有效性。
1 RefConv:一种基于重参数化操作的重聚焦卷积方法
论文名称:RefConv: Re-parameterized Refocusing Convolution for Powerful ConvNets
论文地址:
http://arxiv.org/pdf/2310.10563.pdf
1.1 背景:增加现有卷积架构的先验
卷积神经网络 (CNN) 确实是各种计算机视觉任务的主要工具。提高 CNN 性能的主流方法之一是依赖于精心设计的模型架构,比如 ResNet[1],DenseNet[2] 等等。或者依赖于设计一些即插即用的组件,比如 SENet[3],Cbam[4],Selective Kernel[5]。对于空间维度,ConvNet 典型的解法是利用图像局部先验的卷积滑动窗口机制。对于通道维度,Depth-Wise 卷积在具有独立 2D 卷积核的每个输入通道上完成,与常规的卷积核相比的区别是每个输出通道都会关注于各个输入通道。
本文作者建议从另一个角度提高 CNN 的性能:即增加现有结构的先验。比如,DW Conv 可以看作是多个相互独立的二维卷积核 (称为核通道 [kernel channels]) 的串联:特定核通道的唯一输入是与核位置所对应的特征的通道 (称为特征通道 [feature channel]),作者认为这可能会限制模型的表征能力。作者寻求在不改变模型定义或引入任何推理成本的情况下为模型添加更多的先验。比如,让核通道与其他特征通道进行交互,但是这就使得 DW Conv 不再是 DW Conv 了,因此这种做法不能考虑。
因此,本文提出了一种重参数化技术,通过使其参数关注其他结构的参数来增强模型结构的先验。具体而言,作者提出了一种叫做重参数化重聚焦 (Re-parameterized Refocusing) 技术,该技术建立了现有结构参数之间的联系。
1.2 DW Conv 的重参数化重聚焦技术
给定一个预训练好的卷积模型,作者将其卷积层替换为重参数化重聚焦卷积 (RefConv),如图1所示。
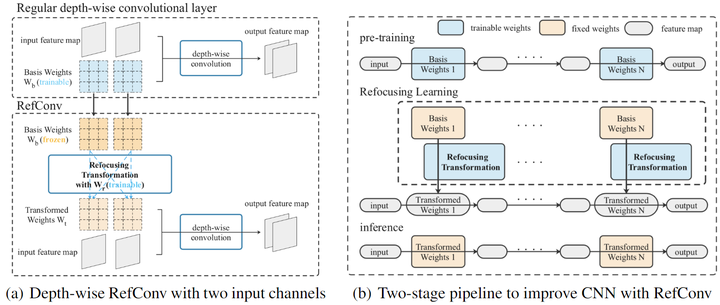
以 DW Conv 为例, 假设输入通道数是 , 输出通道数是 , group 数是 , DW Conv 满足 。
预训练好的 DW Conv 的权重 会经过这么几步变化:
进行一步, 获得新的 DW Conv Kernel, 称之为 。重聚焦变换的权重是 , 这个过程可以写成: 。
然后作者使用权重 , 而不是原始参数来对输入特征进行处理。
假设 Kernel Size 是 , 基权重 和变换后的权重 可以表示为: 。注意, 作者不希望模型的推理结构发生改变, 因此 应该与 的尺寸保持一致。
重聚焦变换 把基权重 变换为权重 , 本文中作者建议把 设置为密集卷积 , 来完成重聚焦变换:

式中, 代表卷积, 这里式1还做了 "Identity mapping" 的操作。作者默认 来确保基权重 和变换后权重 有相同的维度。因此卷积 是密集的,建立通道间连接,就可以使得 的每个通道与 的所有通道相关。
基权重 就好像是重聚焦变换的输入 "特征图",作者使用单个的密集卷积 来提取其特征,因为它简单、直观且足够有效。
通过精心设计的重聚焦变换技术,RefConv 可以将特定 Kernel 通道的参数与其他 Kernel 通道的参数相关联, 即使它们重新关注模型的其他部分 (而不是仅输入特征) 来学习新的表征。其他的 Kernel 通道借助了对应的特征通道进行训练, 编码了其他特征通道的表征。这样一来, RefConv 可以间接建立特征通道之间的连接, 而这种连接没法通过 DW Conv 来直接实现。
在重聚焦变换的权重 训练好以后, 作者使用经过训练的重聚焦权重和冻结的基权重 来生成最终的变换权重, 这些权重被保存并用于推理。
最终得到的模型 (重参数化的 RefConv 模型) 将以与原始模型相同的推理成本提供更高的性能。需要强调的是, 这种性能改进是在没有额外的推理成本或对原始模型结构的变化的情况下实现的。
1.3 广义的重参数化重聚焦技术
本节介绍一般的 Group-Wise Conv 的 RefConv 方法。
对于一般的 Group-Wise Conv 而言, 基权重 和变换后的权重 可以表示为:
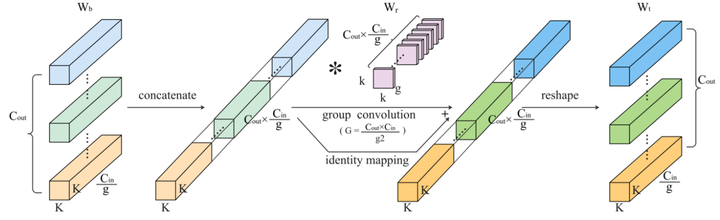
预训练好的 Group-Wise Conv 的权重 会经过这么几步变化:
把基权重 Concatenate 为 的 "特征", 这些 "特征"分为 组 ( 为组数), 每组 "特征" 的通道数是 , 维度是 。
使用变换权重 对基权重 进行变换, 得到的输出维度是 。
把输出 Reshape 成变换之后的权重 。
特殊情况:
DW Conv: 时, , 变换权重 。
Dense Conv: 时, , 变换权重
1.4 计算复杂度分析
本节对重参数化重聚焦方法进行计算复杂度分析, 假设特征图的维度是 :
原始版本卷积的 FLOPs 是 。
重参数化转换操作的 FLOPs 是: , 与 Batch Size 无关。
假设常规设置下有: , 则原始 Conv 的 FLOPs 为 , 而重参数化转换操作只有 。
1.5 重参数化重聚焦训练
从给定的预训练好的 ConvNet 开始, 通过将常规卷积层替换为相应的 RefConv 层来构造 RefConv 模型。作者不替换 卷积层, 因为它们在通道中密集并且没有空间模式的编码, 因此不需要建立跨通道连接或从中提取空间表征。RefConv 层是使用继承自预训练模型的基权重 以及使用 Xavier 随机初始化变换权重 构建的。而且, 变换权重 可以被初始化为零, 以使初始模型等效于预训练模型, 因为每个 RefConv 的 。
在训练过程中, 基权重 是固定的, 变换权重 是可学习的, 得到了用于变换之后的权重 。使用变换之后的权重 来处理输入特征。
在训练完成后, 作者基权重 是和变换权重 来计算最终的变换权重, 并只保存最终的转换权重, 并将它们用作原始 ConvNet 的参数进行推理。这样, 推理时间模型将与原始模型具有相同的结构。
1.6 实验结果
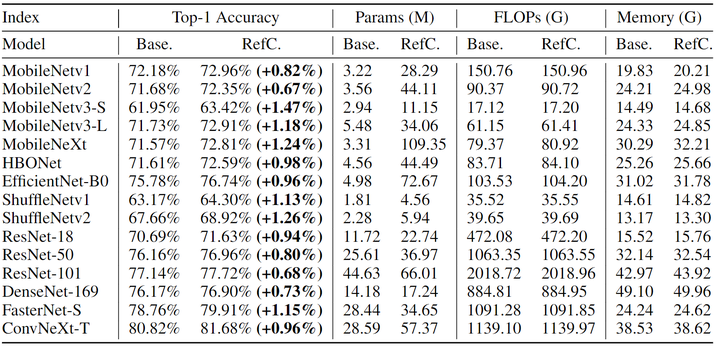
ImageNet 图像分类
作者尝试了多种具有代表性的 CNN 架构,涵盖了不同类型的卷积类型 (DW Conv、Group-Wise Conv 和 Dense Conv)。模型包括 MobileNetv1、v2、v3、MobileNeXt、HBONet、EfficientNet、ShuffleNetv1、v2、ResNet、DenseNet、FasterNet 和 ConvNeXt。
为了训练基线模型,作者采用 momentum 为 0.9 的 SGD 优化器,Batch Size 为 256,权重衰减为 4e−5,使用 5 个 Epochs 预热、学习率初始值 0.1 和 Cosine Annealing 100 Epochs 的学习率 schedule。数据增强使用 random cropping 和 horizontal flipping。输入分辨率为 224×224。重聚焦学习使用 Xavier 随机初始化初始化重聚焦变换的权重,并冻结从相应的预训练模型继承的基本权重。重聚焦学习使用与基线相同的优化策略。
实验结果如下图3所示,可以观察到 RefConv 可以显着提高各种基线模型的性能,并有明显的差距。例如,RefConv 将 MobileNetv3-S (DW Conv)、ShuffleNetv2 (group-wise conv) 和 FasterNet-S (DW 和dense conv) 的 top-1 准确率分别提高了 1.47%、1.26% 和 1.15%。
图3还显示了训练中的参数数量。对于基线模型,在训练和推理期间有相同的参数。对于 RefConv 模型,只在训练期间有额外的参数,在推理期间的参数量与基线模型一致,因此完全不会引入额外的推理成本。
为了衡量训练过程中 RefConv 额外计算量带来的额外训练成本,作者在图3中展示了基线模型和 RefConv 模型的总训练期间的 FLOPs 和内存成本,使用了4个 RTX 3090 GPU,Batch Size 大小为256。与基线相比,RefConv 引入的额外 FLOPs 和内存可以忽略不计,计算成本很小,这是因为它是在 Kernel 上进行的而不是在特征图上。
值得注意的是,只有训练时间RefConv需要少量的额外计算来生成Wt,并且在转换权重后,重新参数化的RefConv模型将在结构上与基线相同(因为在推理过程中根本没有重新聚焦转换),在推理中完全不需要额外的内存或计算成本。这说明 RefConv 只有在训练期间会需要少量的额外计算来生成变换权重,且在推理期间重参数化之后的 RefConv 的模型在结构上与基线一致,无需额外的内存和计算成本。
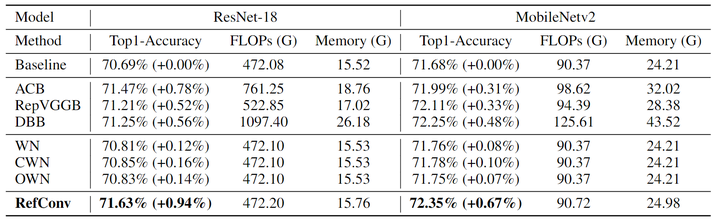
与重参数化方法的比较
作者将 RefConv 与 ImageNet 上其他与数据无关的重参数化方法进行了比较,具体包括:
结构重参数化方法:ACB[6]、RepVGG[7]和 DBB[8]。
权重重参数化方法:WN[9]、CWN[10]和 OWN[11]。
基线模型是 ResNet-18 和 MobileNetv2。应注意这些方法的推理模型都与基线模型相同。实验结果如下图4所示,权重重参数化方法旨在加速和稳定训练,带来的性能上的改进微不足道。结构重参数化方法虽然性能带来了改进,但是引入了较大的额外训练成本。相比之下,RefConv 带来的性能改进最大,且几乎没有额外的训练成本,证明了方法的优越性。
1.7 消融实验结果
作者进行了更多的消融实验,来验证重参数化重聚焦训练的有效性,实验结果如下图5所示。
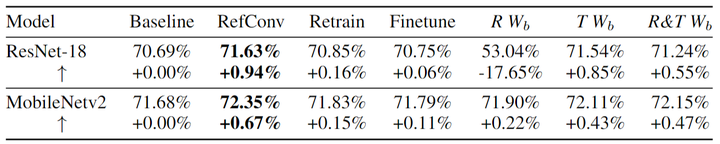
1) 重参数化重聚焦训练优于简单重新训练模型。
图6显示了重新训练模型几乎无法提高性能,因为重新训练特定的 Kernel 的参数仍然没法关注到其他通道的信息 (比如 MobileNet 中的 DW Conv),因此无法学习到新的表征。
2) 重参数化重聚焦训练优于微调模型。
图6显示了与 RefConv 相比,微调仍然只能带来微不足道的好处。简单地微调收敛的模型无法学习到任何新的表征。
3) 预训练的基权重是很重要的先验知识。
基权重 是在重新训练期间固定的。
图6中的 这一列表示随机初始化基权重 并冻结, 而只训练重聚焦权重 。这样做只会对 MobileNetv2 带来微小的改进, 甚至会导致 ResNet-18 显着下降, 这是意料之中的, 因为预训练的基权重可以被视为 RefConv 模型带来的先验知识,这为学习新表示提供了良好的基础。
图6中的 这一列表示基权重 按照预训练权重初始化, 并和重聚焦权重 一起训练。与标准 RefConv 没有改进, 这表明保持基权重 的先验知识是有利的。
图6中的 这一列表示随机初始化基权重 并和重聚焦权重 一起训练。低于标准 RefConv 的性能。
总之, 基权重 含有一些对于训练过程比较重要的先验知识。
4) RefConv 连接了独立的 Kernel。
为了验证 DW RefConv 使 的每个独立的核通道都关注 的其他通道, 作者计算了所有的 中的第 个 channel 和 的第 个 channel 之间的相关矩阵。因为这样的 channel 之间的联系是通过滤波器 建立的, 是一个 矩阵。作者使用 的大小 (即绝对值之和)作为连接程度的数值度量。简而言之, 较大的幅度值表示更强的连接。作者使用 和 的前 64 个通道并计算每对通道之间的连接度以获得 连接度矩阵。结果如下图6所示, 中的第 个通道不仅关注 中对应的第 个通道, 还不同幅度地关注 的多个其他通道, 这表明 DW RefConv 可以关注所有通道来学习现有表示的不同组合。

1.8 重参数化重聚焦减少了通道之间的冗余
为了探索基权重 和变换权重 之间的差异, 本文探索了 和 的通道几余性。作者利用 Kullback-Leibler (KL) 散度来衡量不同通道对之间的相似性, KL 散度越大,相似度越低,通道几余程度越低。
具体而言,作者从训练好的 MobileNetv1 中采样 DW RefConv 层,并对每个 核通道应用 Softmax,然后对前64个通道进行采样,计算每对通道之间的 KL 散度。通过这种方式获得了采样层的 64 × 64 相似度矩阵。如图7所示为多层的相似度矩阵。可以看出,基权重之间的 KL 散度较低,说明通道之间存在高冗余度。而变换权重之间的 KL 散度明显更高,说明通道之间不存在高冗余度。
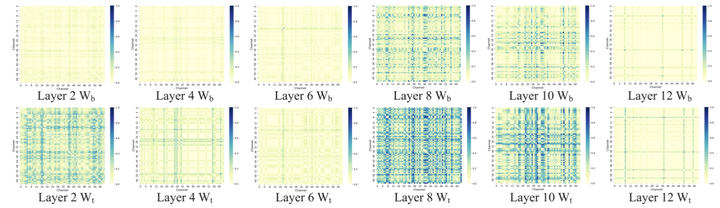
基于这些观察结果,作者得出结论,RefConv 可以有效地减少通道的冗余。作者给出的解释是:RefConv 可以显式地使每个通道能够关注预训练的 Kernel 的其他通道,这就相当于是重新关注了预训练的 Kernel 通道中编码的表征,以学习到不同的新表征。因此,RefConv 可以减小参数的冗余度,增强表征的多样性,从而从而提高了模型的整体表达能力。
1.9 重参数化重聚焦训练平滑了 Loss Landscape
为了探索 Refocus Learning 如何影响训练动态,作者对 Loss Landscape 做了可视化,作者使用在 CIFAR-10 上训练的 MobileNetv1 和 MobileNetv2 作为 Backbone 模型。如图8所示,与基线相比,RefConv 的Loss Landscape 具有更宽、更稀疏的轮廓,这表明 RefConv 的损失曲率更平坦,具有更好的泛化能力。这一现象表明,重聚焦学习具有更好的训练特性,这在一定程度上解释了性能的提高。

参考
^Deep residual learning for image recognition
^Densely connected convolutional networks
^Squeeze-and-excitation networks
^Cbam: Convolutional block attention module
^Selective kernel networks
^ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks
^RepVGG: Making VGG-style ConvNets Great Again
^Diverse Branch Block: Building a Convolution as an Inception-like Unit
^Weight normalization: a simple reparameterization to accelerate training of deep neural networks
^Centered Weight Normalization in Accelerating Training of Deep Neural Networks
^Orthogonal Weight Normalization: Solution to Optimization Over Multiple Dependent Stiefel Manifolds in Deep Neural Networks
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!















 2068
2068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









