






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | Yuchen Zhou
编辑 | 自动驾驶之心
笔者的个人理解
笔者是做规划的,所以下面思考是从规划角度出发。目前learning-based方法,尤其是end2end特别流行。这种直接从传感器数据到trajectory或最终的控制信号的方式,相较于传统模块化方法能够一定程度上减少人工调试成本,且直接将最终的规控作为优化目标,减少了算力浪费。
在end2end方法的众多网络结构中,基本遵循范式:传感器数据->特征提取->场景编码->规划结果输出。往往交通场景中存在大量的动静态障碍物,静态障碍物还好说,动态障碍物的行为则存在大量不确定性,极大程度影响最后的规划结果。所以,上述范式中的场景编码尤为重要,如果能很好地捕捉各个动静态交通要素之间的时空耦合关系,则自然而然利于最后规划结果的输出,反之亦然。
目前的一些方法,大多数直接提取动静态交通场景要素如人、车、车道线和道路边界等特征,然后使用Transformer隐式进行时空建模。这种让模型自己去学习交通要素复杂耦合关系的思路确实比较直观,但可能会存在泛化能力不足的问题。今天分享的这篇文章,针对上述问题,提出了一种比较新颖的解决思路,事先根据人类先验知识建立场景关系图,然后再通过数据驱动,学习图中各个要素的注意力权重,这种显示构建交通要素时空耦合关系图的方式能在一定程度上给我们带来一些启发。
文章主要贡献
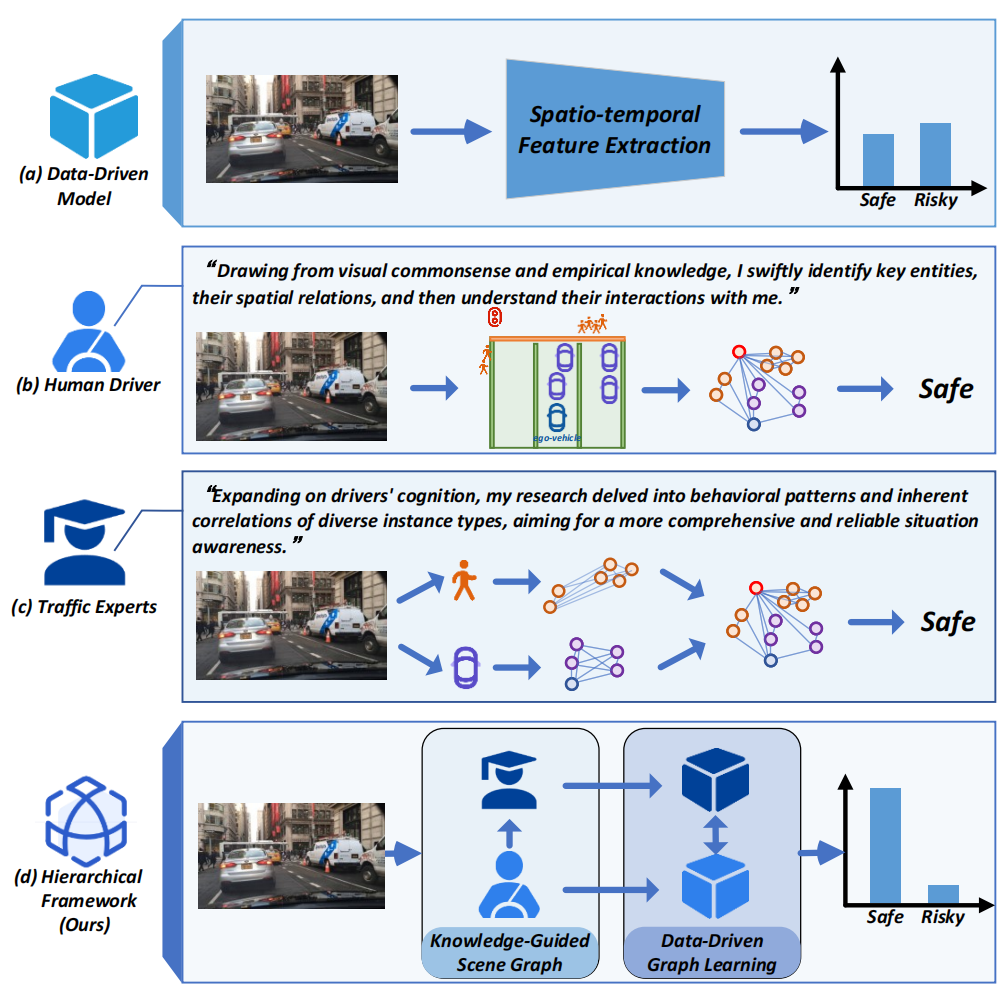
受人类认知启发,作者提出了一个分层知识引导的交通场景图表示学习框架,用于智能车辆。该框架充分利用了通用领域知识和特定领域知识来引导动态交通场景的整个认知过程。
构建了针对行人和车辆的特定图,引导学习过程捕捉每种交通实例类型的运动模式和内在关联。
将全局环境的视觉特征整合到局部实例级场景图中,实现了对行人、车辆、道路、环境动态的全面而鲁棒的理解。
在两个典型的驾驶场景理解任务上实现了该框架,并进行了大量的实验来验证其有效性。实验结果证明该方法在多个数据集:IESG, Non-IESG, 571-Honda, 和1043-Carla上实现了SOTA表现。
详解HKTSG
问题定义
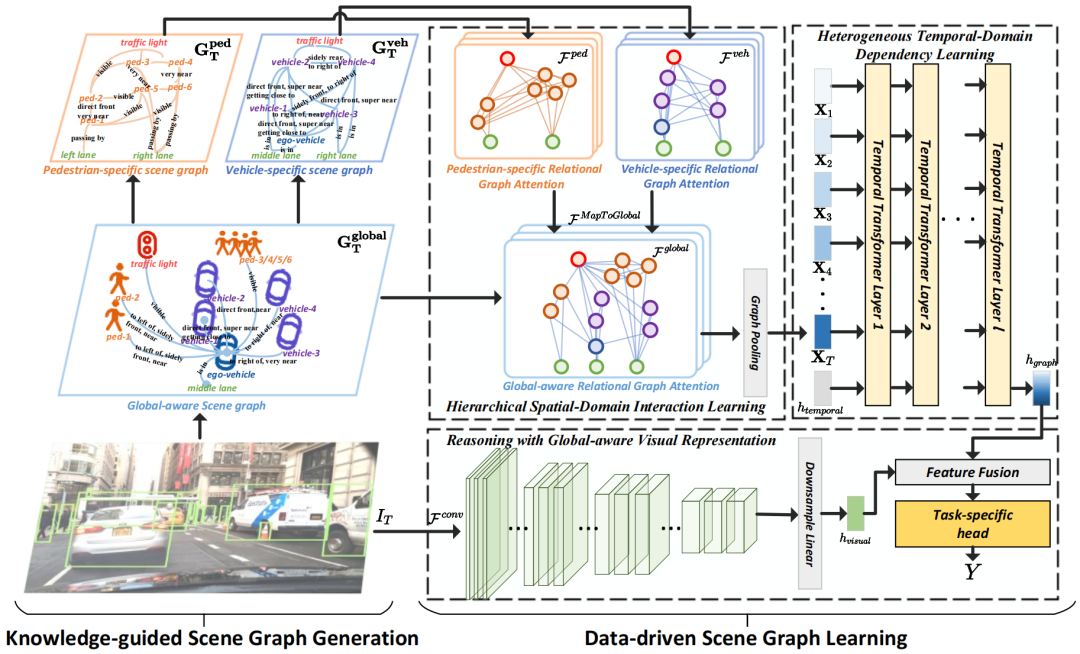
问题建模。输入是序列图像,输出是特定的下游任务,如行人碰撞预测和风险评估等,。方法框架如Fig.2. 所示。该框架分为两个阶段:知识引导的场景图生成和数据驱动的场景图学习。在第一阶段,生成了全局图、行人图和车辆图,这些图基于常识知识包含了明确的关联信息。在这些图的引导下,进行第二阶段的工作。它首先提取交通实例的运动模式、类内和类间的交互(分层空间-领域交互学习),然后建立时间依赖性(异构时间-领域依赖性学习)。最后,它将图特征与全局感知的视觉表示融合,以完成下游特定任务(利用全局感知的视觉表示进行推理)。下面分知识引导的场景图、数据驱动的图学习和全局信息聚合等三部分进行介绍。
知识引导的场景图
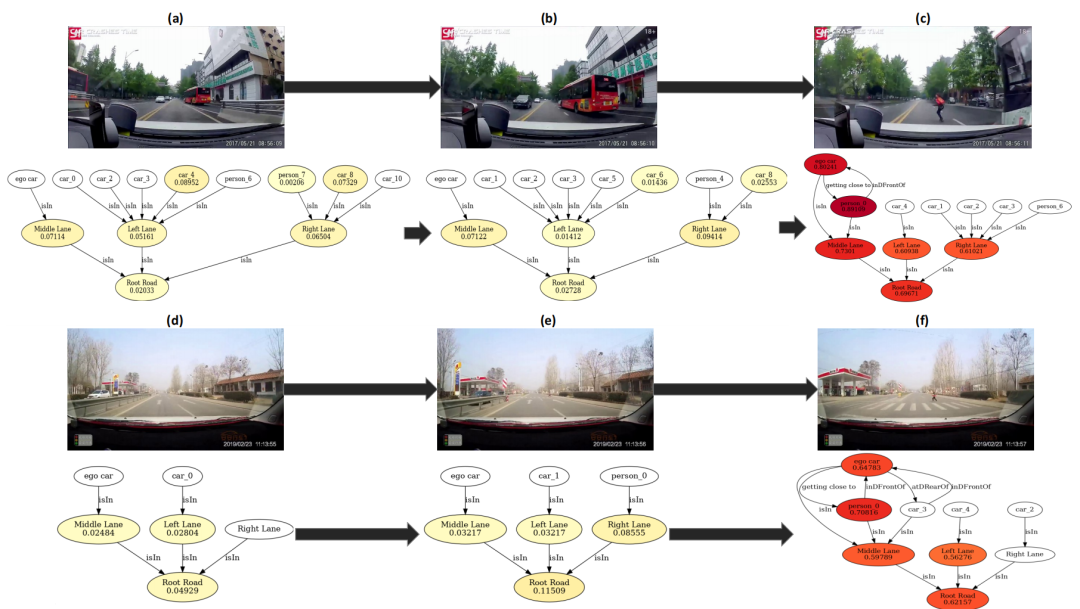
首先介绍知识引导的场景图,对应Fig.2. 的左半部分。该模块,作者采用全局到局部的思想,建立三种场景树:全局场景树、行人场景树和车辆场景树,三者有如下包含关系:(前者就是全局,后两者就是局部)。场景树的结构为,其中是每帧图像的检测结果集合,包含检测框的类别和位置(由Mask R-CNN检测得到,然后投影到BEV空间);其中代表检测结果之间的关系集合,关系事先根据人类驾驶经验建立,如Fig.3. 所示。
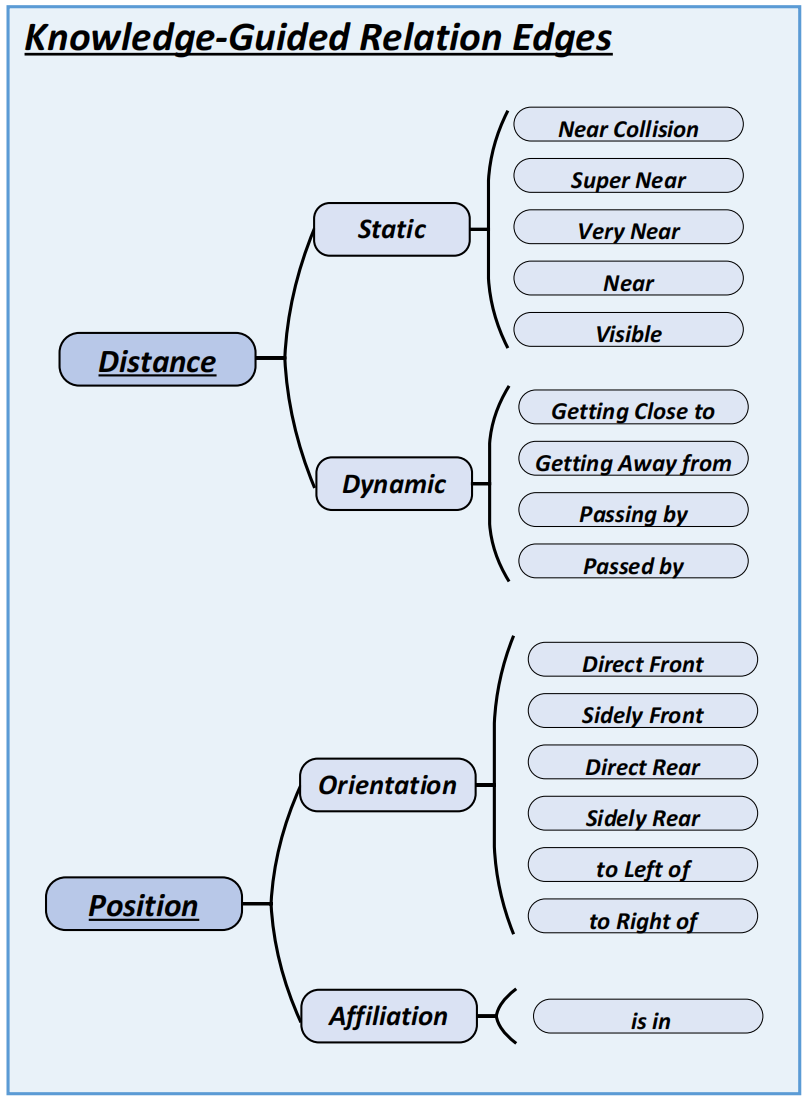
关系分为两大类:距离(Distance)和位置(Position),距离又包含静态(Static)和动态(Dynamic),位置又包含方向(Orientation)和归属关系(Affiliation)。
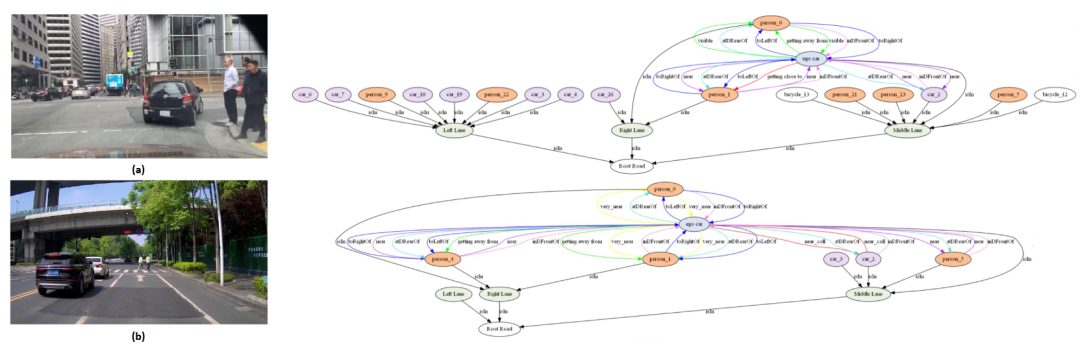
静态距离直接由实例之间的BEV坐标计算得到,有very near、near和visable等,动态距离则是根据相邻帧的实例间距离变化计算,有getting close to、getting away from和passing by等。方向关系根据实例之间的航向角计算,有direct front、sidely front和direct rear等。归属关系根据实例与车道的位置关系计算,有is in。Fig.4. 展示了(a)和(b)两种典型场景下建立的场景图。(上述建立关系图的方式适用于全局、车辆和行人场景图。)
数据驱动的场景图学习
经过上述知识引导的场景图,一个实例间基本框架已经构建完成,接下来需要在这个框架基础上学习实例间动态的时空交互关系 。这里采用数据驱动的方法,具体地分为分层的空域交互学习和时域依赖学习,对应Fig.2. 的右半部分。
分层的空域交互学习
由上述可知,构建了三种场景图:全局、车辆和行人。作者采用从局部到全局的思想,即先学习类内的交互关系(车辆和行人),再学习类间的关系(全局)。首先根据特定类别图注意力函数和学习特定类别场景图和的交互关系,然后再通过全局图注意力函数学习类别之间场景图的交互关系。具体如下,从行人场景图的学习开始介绍。首先得到每个行人实例的embedding:
然后,使用关系图注意力网络(Relational Graph Attention Network,RGAT)根据边更新节点。节点之间的注意力分数如下:
接着,进行节点特征更新:
车辆场景图计算过程类似:
最后,计算类之间的交互关系,也就是全局场景图:
原文中说是把三个场景图中相同的实例concatenate起来:,然后独立的实例特征进行维度补充。最后经过池化和相加得到该时刻的空域特征。
时域交互学习
经过上述的空域学习,建模了实例间的空间关系,为了更准确的学习实例之间的时空交互关系,需要融合时间序列信息。这里,作者采用比较直观的多层Transformer,提取特征序列的时序依赖关系。然后将最后一个时刻作为最终该模块的输出。
全局信息聚合
上面讲的场景图构建和数据驱动图学习,都是在检测结果这种实例级别上进行操作的,缺少对周围环境的背景特征的提取。因此,作者对整个输入图片进行特征提取:
将上述实例特征和全局特征进行融合得到最终特征:
最后,可以根据下游任务接不同的head以实现具体任务:
实验
作者在两种任务的场景理解上评估模型:行人碰撞预测(pedestrian collision prediction)和主观风险评估(subjective risk assessment)。前者预测自车与行人发生潜在碰撞的场景,后者则定性评估了交通场景中的潜在风险。这两种任务都有助于自动驾驶系统规避风险,提高驾驶的安全性和有效性。
定量结果
数据集。作者在 IESG、Non-IESG、571-Honda和1043-Carla数据集上进行了实验。指标。精度(accuracy ,Acc),曲线下面积( area under the curve,AUC)和F1分数(F1 score,F1)。
对比实验
对比的Baseline有CNN-LSTM、MRGCN-Mean、MRGCN-LSTM-last、MRGCN+LSTM-attn、MRGIN和PCRA。如Table I和Table II所示,我们在IESG和Non-IESG数据集上进行了行人碰撞预测任务的测试,在571-honda-sg1043-carla-sg数据集上进行了主观风险评估测试。可以看到,HKTSG在两种任务上均达到SOTA水平。


消融实验
为了验证模型中各组件的有效性,作者在IESG和Non-IESG等两个数据集中进行了消融实验,如Table III所示。可以看到,当三个组件:、和同时存在时,性能达到最优。

可视化
可视化结果如Fig.5. 所示,在两种场景下的结果,场景图中每个节点具有不同的注意力权重。
参考
[1] Y. Zhou, X. Liu, Z. Guo, M. Cai and C. Gou, "HKTSG: A Hierarchical Knowledge-guided Traffic Scene Graph Representation Learning Framework for Intelligent Vehicles," in IEEE Transactions on Intelligent Vehicles, doi: 10.1109/TIV.2024.3384989.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!
自动驾驶感知:目标检测、语义分割、BEV感知、毫米波雷达视觉融合、激光视觉融合、车道线检测、目标跟踪、Occupancy、深度估计、transformer、大模型、在线地图、点云处理、模型部署、CUDA加速等技术交流群;
多传感器标定:相机在线/离线标定、Lidar-Camera标定、Camera-Radar标定、Camera-IMU标定、多传感器时空同步等技术交流群;
多传感器融合:多传感器后融合技术交流群;
规划控制与预测:规划控制、轨迹预测、避障等技术交流群;
定位建图:视觉SLAM、激光SLAM、多传感器融合SLAM等技术交流群;
三维视觉:三维重建、NeRF、3D Gaussian Splatting技术交流群;
自动驾驶仿真:Carla仿真、Autoware仿真等技术交流群;
自动驾驶开发:自动驾驶开发、ROS等技术交流群;
其它方向:自动标注与数据闭环、产品经理、硬件选型、求职面试、自动驾驶测试等技术交流群;
扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】硬件专场


















 3858
3858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









