






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | 自动驾驶Daily
编辑 | 自动驾驶之心
写在前面
基于NeRF的方法生成3D城市显示出了有希望的生成结果,但在计算上效率不高。最近,3D高斯Splatting(3D-GS)已成为目标级3D生成的高效替代方案。然而,将3D-GS从有限尺度的3D物体和人类扩展到无限尺度的3D城市并非易事。无边界的3D城市生成会产生显著的存储开销(内存溢出问题),因为需要将点扩展到数十亿个,这通常需要数百GB的VRAM来呈现一个跨越10km²的城市场景。
GaussianCity,一个生成性Gaussain Saplatting框架,专门用于通过单次前馈传递高效地合成无边界的3D城市。主要贡献有两点:
1)紧凑的3D场景表示:引入了BEV-Point作为高度紧凑的中间表示,确保无边界场景中的VRAM使用量增长保持不变,从而实现无边界城市的生成。
2)空间感知的高斯属性解码器:提出了空间感知的BEV-Point解码器来生成3D高斯属性,该解码器利用点序列化器整合BEV点的结构和上下文特征。
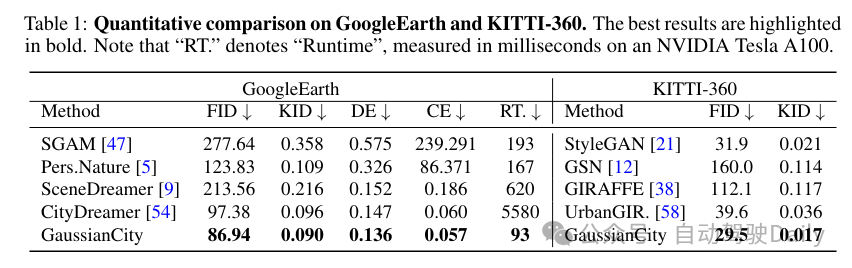
大量实验表明,GaussianCity在无人机视角和街道视角的3D城市生成中都取得了最先进的结果。特别值得注意的是,与CityDreamer相比,GaussianCity表现出更优越的性能,速度提高了60倍(10.72 FPS vs 0.18 FPS)。
GaussianCity方法介绍
GaussianCity的框架如下所示:为了创建一个无边界的3D城市,首先从BEV地图的一个局部区域生成BEV点,这些点包括高度场H、语义地图S和二进制密度地图D。然后,为每个点生成BEV-Point属性,并为每个实例生成样式查找表。接下来,BEV-Point解码器从BEV-Point属性中生成高斯属性A。最后,高斯渲染器R生成渲染图像R。
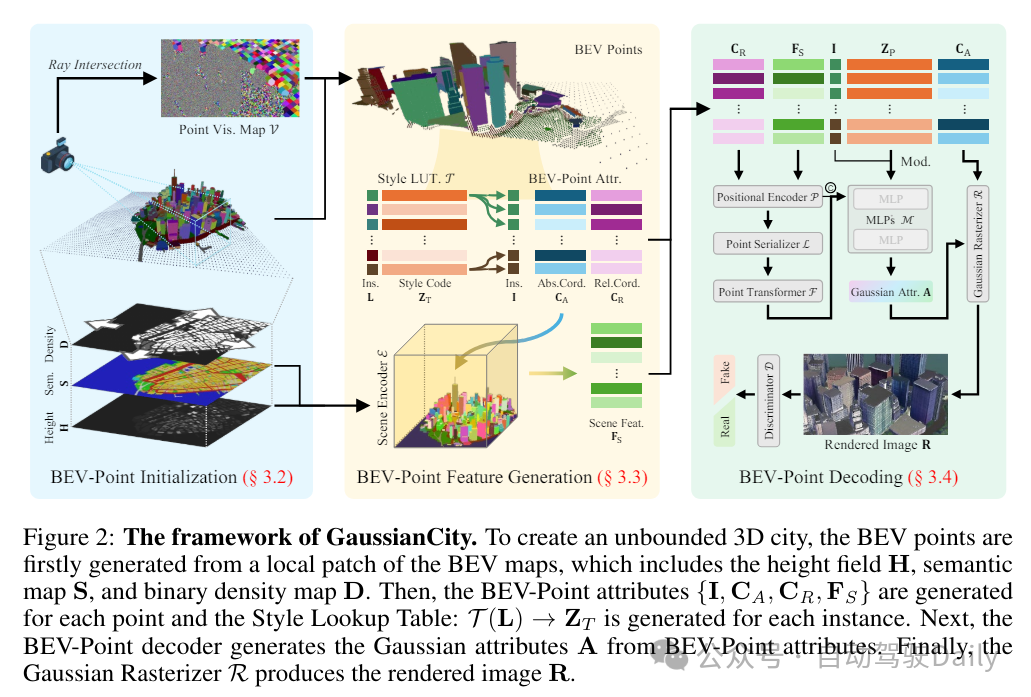
BEV-Point Initialization
在3D-GS中,所有的3D高斯函数在优化过程中都会使用一组预定义的参数进行初始化。然而,随着场景规模的扩大,VRAM的使用量会急剧增加,使得生成大规模场景变得不实际。为了解决这个问题,这里提出了一种高度紧凑的表示方法,即BEV-Point。在BEV-Point表示法中,仅保留可见的BEV点,因为只有它们会影响当前帧的apperance。它确保VRAM的使用量保持不变,因为给定固定的相机参数,可见BEV点的数量不会随着场景规模的增加而增加。
在BEV地图的一个局部区域中,该区域包含一个语义地图M和一个高度场H,可以通过根据高度场H中对应的值将语义地图S中的像素挤出,来生成该区域内的BEV点集合。这里进一步引入了二进制密度图D来调整不同语义类别的采样密度。这是基于观察到某些类别具有更简单的纹理(例如,道路、水域),因此可以通过降低密度来管理计算成本,而其他类别(例如,建筑立面)具有复杂的纹理,需要更多的点来表示。生成的BEV点的坐标,记作,可以按照以下方式生成:
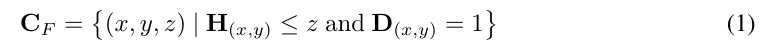
得益于二进制密度图D,已经省略了相当数量的冗余BEV点。然而,剩余的数量,通常约为2000万个BEV点,对于优化来说仍然太大。为了解决这个问题,额外进行了射线相交检测,以获取二进制可见性映射V:(x, y, z) → v,其中v ∈ {0, 1},用于过滤出可见的BEV点。因此,可见的BEV点的坐标可以生成为:
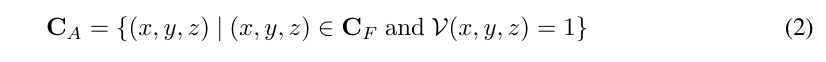
BEV-Point Feature Generation
BEV-Point表示中的特征可以分为三类:实例属性、BEV-Point属性和样式查找表。实例属性包含每个实例的基本细节,如实例标签、大小和中心坐标。BEV-Point属性决定了实例内的apperance,而样式查找表则控制不同实例之间的样式变化。
实例属性。语义地图S为BEV点提供了语义标签,参照CityDreamer,这里引入了实例地图Q来处理城市环境中建筑和车辆的多样性。

其中,Inst(·) 表示通过在语义地图上检测连通分量来进行实例化。因此,BEV点的实例标签I可以计算为:
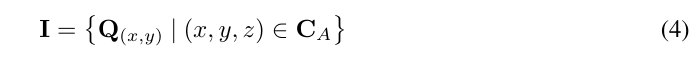
BEV-Point属性。在BEV-Point初始化中,生成了绝对坐标,其原点设置在世界坐标系的中心。除了绝对坐标外,还引入了相对坐标,其原点设置在每个实例的中心,以指定相对于实例的归一化点坐标。
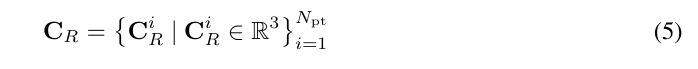

在生成过程中,为BEV点整合上下文信息变得至关重要。这是通过引入从BEV地图中获取的、并使用绝对坐标索引的场景特征来实现的。
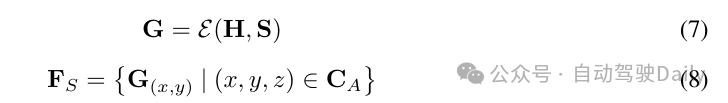
样式查找表。在3D-GS中,3D高斯函数的外观由每个高斯函数的属性定义。随着3D高斯函数数量的增加,对VRAM和文件存储的需求也显著增加,使得无限制的场景生成变得不可行。为了进一步降低计算成本,实例的外观被编码为一组潜在向量ZT 即:

BEV-Point Decoding
BEV-Point解码器被设计用来利用BEV-Point特征生成高斯属性A。它包含五个关键模块:positional encoder, point serializer, point transformer, modulated MLP, and Gaussian rasterizer。
位置编码器。位置编码器不是直接将坐标输入到后续网络中,而是将每个点坐标和相应的特征转换为更高维度的位置嵌入,具体过程如下:

点序列化器。与NeRF不同,NeRF维持了沿射线采样的点之间的空间相关性,但由于点云的不规则性,BEV点和3D高斯函数是无结构和无序的。因此,直接将多层感知机(MLPs)应用于从FP生成高斯属性可能不会产生最优结果,因为MLPs并没有完全考虑点云的结构和上下文特性。
为了将无结构的BEV点转换为结构化格式,这里提出了点序列化器L: (x, y, z) → o,其中o ∈ Z,用于将点坐标转换为整数,以反映该点在给定BEV点中的顺序。
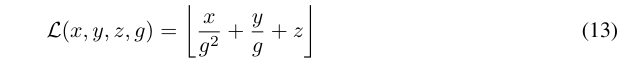
point transformer。在序列化之后,BEV点的特征可以通过一个Transformer F进行处理:

调制多层感知机(MLPs)。通过应用多层感知机(MLPs)M ,结合BEV点的特征对样式代码和实例标签I进行调制,生成3D高斯函数A :
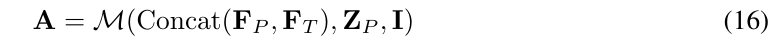
高斯栅格化器。给定相机的内参和外参,可以使用高斯栅格化器R来渲染图像。

在栅格化过程中,如果A中未生成所需的属性,则会使用默认值。这些默认值包括缩放因子s = 1,旋转四元数q = [1, 0, 0, 0],以及不透明度α = 1。
损失函数
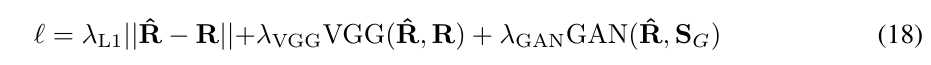
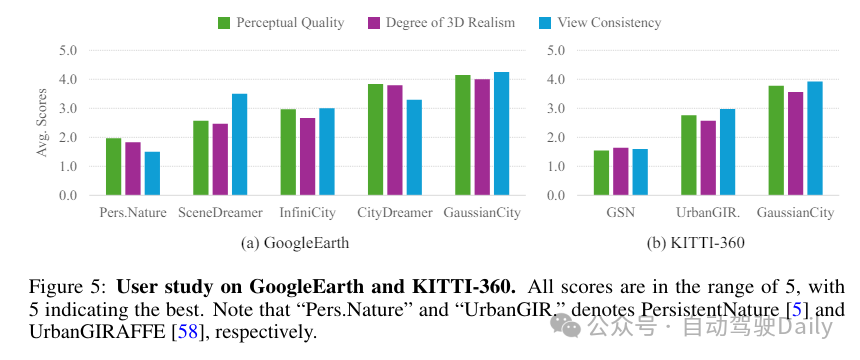
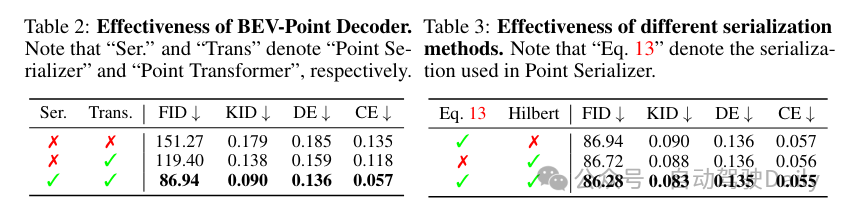
实验对比


参考
[1] GaussianCity: Generative Gaussian Splatting for Unbounded 3D City Generation
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









